출처: https://www.edwith.org/bayesiandeeplearning/lecture/24678?isDesc=false
Probability
학습 목표
Set이 정의되어 있어야 그 위에 Measure를 정의할 수 있고,
Measure가 있어야 Probability를 정의할 수 있습니다.
그래서 이전 학습을 통해 Set과 Measure에 대해서 공부해보았습니다.
이제부터는 베이지안 딥러닝을 공부하기에 앞서 꼭 필요한 개념인 Probability에 대해서 구체적으로 공부해보도록 합시다.
Keywords
- 확률(Probability)
- 표본공간(Sample space)
- 확률 시행(Random experiment)
- 확률 질량 함수(Probability mass function)
- 베이즈정리(Bayes' theorem)
- 기댓값(Expectation)

여기서 각각의 눈이 나올 확률은 sample space에서 정의된 면적과 같다.
P({1})=P({2})=P({3})=P({4})=P({5})=P({6})=1/6
P(A)=P(2,4,6)=P({2})+P({4})+P({6})=1/2
- The random experiment should be well defined.
- The outcomes are all the possible results of the random experiment each of which canot be further divided. (outcome ≠ sample space)
- The sample point w: a point representing an outcome.
- The sample space Ω
: the set of all the sample points. - Definition (probability)
- P defined on a measurable space (Ω,A) is a set function
P : A→[0,1] such that (probability axioms). (A는 σ-field 이며, 0에서 1사이로 measure되고)- P(∅)=0 (empty set은 0)
- P(A)≥0∀A⊆Ω (항상 0이상이고)
- For disjoint sets Ai and Aj⇒P(∪ki=1Ai)=∑ki=1P(Ai) (countable additivity, disjoint set에 대해서 더하면 더해지는)
- P(Ω)=1 (normalize 되었기 때문에 set 전체가 들어가면 1)
- P defined on a measurable space (Ω,A) is a set function
- probability allocation function
- For discrete Ω: (probability mass function)
p:Ω→[0,1] such that ∑w∈Ωp(w)=1 and P(A)=∑w∈Ap(w) - For continuous Ω: (probability distribution function)
f:Ω→[0,∞) such that ∫w∈Ωf(w)dw=1 and P(A)=∫w∈Ωf(w)dw. - Recall that probability P is a set function P:A→[0;1] where A is a σ-field.
:결국 sample space에서 확률의 정의를 만족하는 함수들을 찾다보니 gaussian distribution 같은 분포가 나온 것
- For discrete Ω: (probability mass function)
- conditional probability of A given B:
P(A|B)def=P(A∩B)P(B) - Again, recall that probability P is a set function, i.e., P:A→[0;1].
- From the definition of conditional probability, we can derive:
- chain rule:
P(A∩B)=P(A|B)P(B)
P(A∩B∩C)=P(A|B∩C)P(B∩C)=P(A|B∩C)P(B|C)P(C) - total probability law:
P(A)=P(A∩B)+P(A∩BC)=P(A|B)P(B)+P(A|BC)P(BC) - Bayes' rule
p(B|A)=P(B∩A)P(A)=P(A∩B)P(A)=P(A|B)P(B)P(A) - When B(로또를 맞을 확률) is the event that is considered and A(전날 밤에 꾼 꿈) is an observation,
- P(B|A) is called posterior probability.
- P(B) is called prior probability.
- independent events A and B: P(A∩B)=P(A)P(B)
- independent ≠ disjoint, mutually exclusive
Random variable
학습 목표
이전 수업을 통해서 확률에 대해서 공부하면서, 확률 공간에 대해서 정의하였습니다.
확률 공간에서는 확률적인 과정에 따라 값이 결정되는 변수가 있는데
그 변수를 확률 변수(Random variable)이라고 부릅니다.
이번 시간에는 확률 변수에 대해서 공부해보도록 해요.
Keywords
- 확률변수(Random variable)
- 확률공간(Probability space)
- 확률 밀도 함수(Probability density function)
- 상관분석(Correlation analysis)
- random variable:
A random variable is a real-valued function defined on Ω that is measurable w.r.t. the probability space (Ω,A,P) and the Borel measurable space (R,B), i.e.,
X:Ω→R such that ∀B∈B,X−1(B)∈A.
:sample space에서 하나의 원소가 특정 실수에 대응되는 함수, 확률은 sample space σ-field 에서 정의된 set function
:여기서 inverse image(역함수)로 표시한 것은 주사위의 1과 2가 나올 확률을 구하기 위해 1과 2가 차지하는 면적을 구하기 위해 원래 sample space에서 만들어지는 σ-field 안에 들어가게하고 싶은 것
*Borel set: 실수들의 집합(R)으로 만들어지는 σ-field
- What is random here?
: sample space에서 하나를 뽑는 것, 함수이기 때문에 그에 해당하는 값이 튀어나옴 - What is the result of carrying out the random experiment?
: 결과는 관측치가 하나 나오는 것
- What is random here?

- Random variables are real numbers of our interest that are associated with the outcomes of a random experiment.
- X(w) for a specific w∈Ω is called a realization. (즉, sampling이 realization)
- The set of all realizations of X is called the alphabet of X. (주사위를 던질 때 alphabet은 1~6)
- We are interested in P(X∈B) for B∈B:
P(X∈B)def=P(X−1(B))=P({w:X(w)∈B})
:역함수가 차지하는 면적을 계산하는 것이 확률 - discrete random variable: There is a discrete set
{xi:i=1,2,...} such that ∑P(X=xi)=1 (X라는 random variable이 x_i 값이 나올 면적의 크기) - probability mass function: pX(x)def=P(X=x) that satisfies
- 0≤pX(x)≤1
- $\sum_x p_X(x)=1
- P(X∈B)=∑x∈BpX(x)
- example: three fair-coin tosses
- X = number of heads
- probability mass function (pmf)
pX(x){1/8,x=03/8,x=13/8,x=21/8,x=30,else - P(X≥1)=38+38+18=78
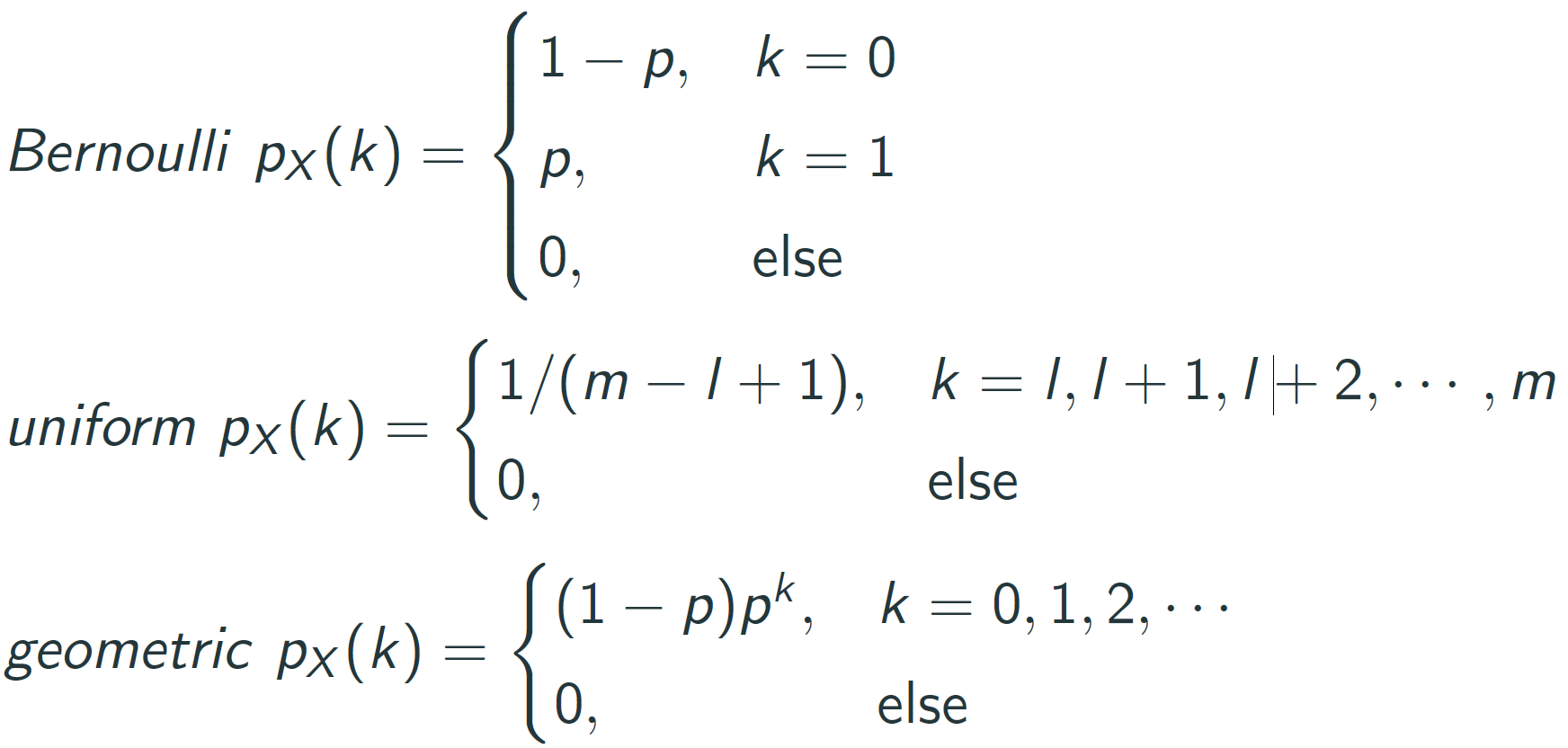
- continuous random variable
There is an integrable function fX(x) such that
P(X∈B)=∫BfX(x)dx - probability density function
fX(x)def=limΔx→0P(x<X≤x+Δx)Δx that satisfies
:pmf와 다른점은 단일 값의 확률은 면적이 0이기 때문에 0이다
- fX(x)>1 is possible
- ∫−∞∞fX(x)dx=1
- P(X∈B)=∫x∈BfX(x)dx

EXdef={∑xxpX(x),discreteX∫∞∞xfX(x)dx,continuousX
- Conditional expectation E(X|Y) (mean 0 gaussian의 expectation 은 0이다. 즉, random variable의 expectation은 radom variable이 아니라 그 평균이다. 그러나 다른 random variable (Y)에 contional하게 되면 그 expectation (E(X|Y))는 random variable이 된다.)
- Expectation E(X) of random variable X is EX=∫xfX(x)dx and is a deterministic variable.
- E(X|Y) is a function of Y and hence a random variable.
- For each y, E(X|Y) is X average over the event where Y=y.

- Definition (conditional expectation)
- Given a random variable Y with E|Y|<∞ defined on a probability space (Ω,A,P) and some sub-σ-field G⊂A we will define the conditional expectation as the almost surely unique random variable E(Y|G) which satisfies the following two conditions
- (Y|G) is G-measurable.
- E(YZ)=E(E(Y|GZ)) for all Z which are bounded and G-measurable.
- Conditional expectation E(X|Y) with different σ-fields.
- Given a random variable Y with E|Y|<∞ defined on a probability space (Ω,A,P) and some sub-σ-field G⊂A we will define the conditional expectation as the almost surely unique random variable E(Y|G) which satisfies the following two conditions

- Moment
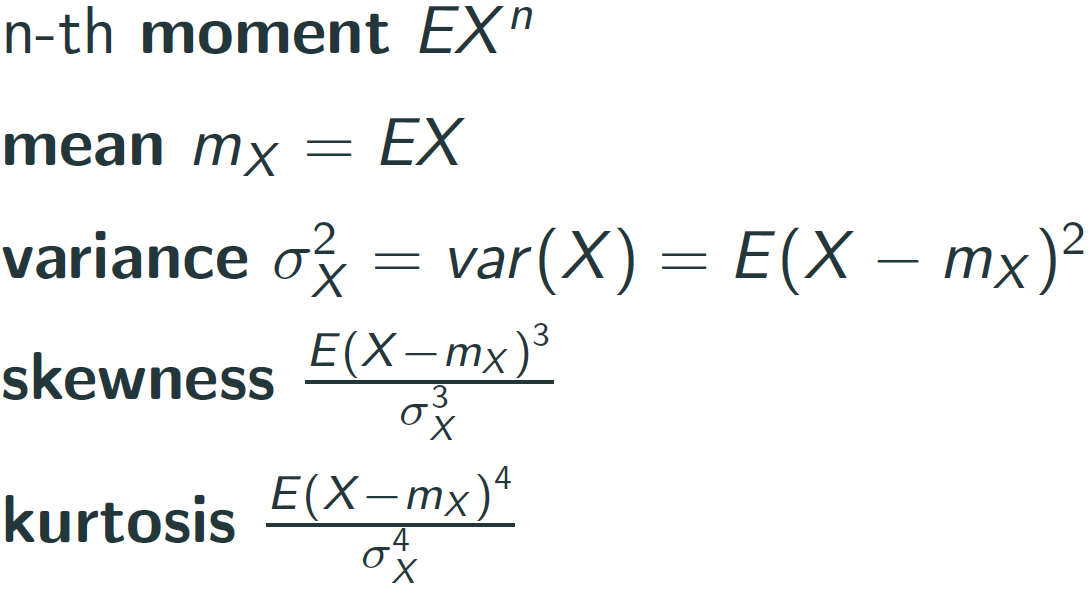
평균은 분포를 고려하지 않기 때문에 다른 분포를 의미하는 다른 수치들과 함께 봐야한다. - Joint Moment

'교육 > Bayesian Deep Learning' 카테고리의 다른 글
| 1-1) Elementary of mathmatics (0) | 2022.11.22 |
|---|
