
Abstract
Deep NLP 모델은 input perturbation에 약한 모습을 보인다. 최근 연구는 counterfactual을 이용한 data augmentation이 이 약점을 개선한다고 한다. 그 중 해당 논문은 question answering(QA)에 대한 counterfactual 생성 작업에 초점을 맞췄다. 최소한의 사람의 감독으로 counterfactual 평가와 훈련 데이터 생성을 위해 Retrieve-Generate-Filter(RGF)를 개발했다. Open domain QA 프레임워크와 원래 작업 데이터에 대해 훈련된 질문 생성 모델을 사용하여 유창하고 의미론적으로 다양하며 자동으로 레이블이 지정된 counterfactual을 생성한다. RGF counterfactuals를 이용한 data augmentation은 out-of-domain과 도전적인 평가 set 그리고 기존 방식보다 독해 그리고 open-domain QA에서 성능 향상을 보여주었다. 더 나아가 RGF 데이터는 local perturation에 대한 robustness 향상을 보여주었다.
Introduction
Natural language understanding(NLU)는 표준 벤치마크에서 사람을 능가하지만, 비논리적인 상관관계 또는 데이터 결함에 과도하게 의존적인 분포 변화의 경우 성능이 저조한 경우가 많다. 이 행동은 특정 속성에 대한 개입을 시뮬레이션하도록 설계된 반대 사실 데이터(Kaushik et al., 2020; Gardner et al., 2020)를 사용하여 조사할 수 있다.
예를 들어, 영화평론 “A real stinker, one out often!" 을 “A real classic, ten out of ten!"으로 자극하면 우리는 모델의 예측에 대한 형용사 극성의 영향을 구별할 수 있다.
최근 연구들은 counterfactual data(CDA)로 훈련된 모델이 일반화되고 훨긴 견고하다고 밝혔다. 결과적으로 몇몇 downstream tasks에 대해 CDA 자동 생성 기술이 몇 가지 제안되었다.
해당 논문에서는 독해와 open-domain의QA에 대한 CDA에 초점을 맞췄다. 모델 입력은 질문에 추가적으로 지문으로 되어있으며 타겟은 짧은 정답 span, a로 되어있다. 논문은 다양한 실용적인 조건에서 사용할 수 있도록 counterfactual을 생성하는 방법을 찾아봤다. QA에서 가능한 인과적 특징 집합은 크고 선험적 요소를 지정하기 어렵다.
예를 들어, “Who is the captain of the Richmond Football Club” 에서 “Who captained Richmond’s women’s team?”으로의 변환은 해당 club의 다른 team에 대한 정보가 필요하다. 그리고 “Who was the captain of RFC in 1998?”은 원래 질문에서 시간 민감성 특성에 대한 지식을 요구한다. 즉 특정 지식 없다면 “Who captained the club in 2050?” 와 같은 그럴싸하지만 잘못된 가정이나 대답 불가능한 질문을 초래할 것이다.
이러한 문제 극복을 위해 Retrieve, Gernerate, and Filter (RGF; Figure 1)를 개발했다. Retrieve-and-read QA 모델의 near-misses를 사용하여 원래 질문과 밀접하게 관련되어 있지만 의미적으로는 다른 대체 컨텍스트 및 답변을 제안한다. 그런 다음 시퀀스 대 시퀀스 질문 생성 모델(Alberti et al., 2019)을 사용하여 이러한 구절과 답변에 해당하는 질문을 생성합니다. 그 결과 augmented 훈련 데이터 또는 분석을 위해 필터링된 사후 필터링에 직접 사용할 수 있는 완전한 레이블이 지정된 예제가 생성됩니다.
이 방법은 원래 작업 훈련 데이터 외에 supervised 입력이 필요하지 않지만 heuristic, meaning representation 또는 human generation을 통해 생성하는 많은 변환 유형을 포함하여 semantic phenomena의 범위를 포괄하는 매우 다양한 counterfactuals을 생성할 수 있습니다. 합성 데이터의 대체 소스와 비교할 때 RGF 데이터로 보강된 훈련은 도메인 내 정확도를 유지하면서 도메인 외 및 대비 평가 세트를 비롯한 다양한 설정에서 성능을 향상시킵니다. 추가적으로 pairwise consistency를 소개하고 이를 통해 RGF가 local perturbation 범위에서 robustness가 상당히 향상됐음을 보여주겠다.
Related Work
1) Counterfactual Generation
사람들은 다양한 반사실적 시나리오에서 모델을 평가하는 NLU용 챌린지 세트를 개발하는 데 상당한 관심이 있었다. 이전에는 해당 세트를 사람이 만들거나, adversarial 설정을 특정 모델에 주어서 생성했다. 그러나 이러한 방법은 비효율적이였다.
이로 인해 out-of-distribution generalization(Bowman and Dahl, 2021)를 평가하기 위한 그리고 counterfactual data augmentaion(Geva et al., 2021; Longpre et al., 2021)를 위한 자동 반사실 데이터 생성에 대한 관심이 높아졌습니다.
경험적 방법
최상급과 명사 교환(Dua et al., 2021)
성별 단어 변경(Webster et al., 2020)
특정 데이터 분할 타겟팅(Finegan-Dollak 및 Verma, 2020)
최근 작업
Meaning representation frameworks and structured control codes (Wu et al., 2021a)
Including grammar formalisms (Li et al., 2020)
Semantic role labeling (Ross et al., 2021b)
Structured image representations like scene graphs (Bitton et al., 2021)
Query decompositions in multi-hop reasoning datasets (Geva et al., 2021)
Perturb contexts instead of questions by swapping out all mentions of a named entity (Ye et al. (2021) and Longpre et al. (2021))
레이블 변경은 heuristic 방식으로 파생되거나 사람이 데이터에 레이블을 다시 지정해야 한다. 이는 사전 정의된 schema가 관심을 가질 수 있는 의미적 섭동의 범위를 다루는 데 어려움이 있을 수 있는 Natural Questions(Kwiatkowski et al., 2019)과 같은 작업에 적용하기 어려울 수도 있다.
2) Data Augmentation
QA를 위한 non-counterfactual data augmentation은 out-of-domain 일반화와 robustness에 약간의 상승만 보여줬다. 모델에 최소한 데이터쌍을 노출시킴으로 비논리적인 상관관계를 줄이고 정확한 인과관계를 학습할 가능성이 높아지므로 CDA가 예측을 더 잘 한다(Kaushik et al., 2020). 그러나 Joshi와 He(2021)는 perturbation의 구조적 및 semantic 공간을 제한하는 방법이 다른 유형의 변환에 대한 일반화를 잠재적으로 손상시킬 수 있음을 발견했다. 이 문제는 편집할 semantic 차원이 여러 개 있을 수 있는 QA 시나리오에서 악화된다. 이 논문에서는 광범위한 semantic 현상을 대상으로 하여 이 문제를 해결하려고 시도하여 증강 모델이 과적합될 가능성을 줄입니다.
RGF: Counterfactuals for Information-seeking Queries
우리는 반대되는 예를 원래 x′와 의미 있고 통제된 방식으로 다른 alternative 입력 x로 정의합니다. 그러면 레이블(출력)의 변경에 대해 모델을 추론하거나 가르칠 수 있습니다.
QA 설정) Question, Context passage, short Answer
입력: (q,c,a)
Counterfacual: (q′,c′,a′)
이 설정은 변경할 관련 semantic 변수를 식별하기 위한 배경 지식의 필요성, 질문 편집에서 충분한 semantic 다양성 보장, 잘못된 전제 또는 실행 가능한 답변이 없는 질문 방지와 같은 몇 가지 고유한 문제를 제기한다. 표면 형태에 대한 작은 변화가 semantic 변화를 초래할 수 있고 그 반대의 경우도 마찬가지이기 때문에 최소성을 보장(또는 특성화)하는 것도 어려울 수 있다.
1) Overview of RGF
RGF는 입력 x=(q,c,a)에 대해 새로운 입력 세트 N(x)={(q′1,c′1,a′1),(q′2,c′2,a′2),...}를 생성한다.
Open-domain retrieve-and-read 모델을 사용하여 a≠a′ alternate contexts c′과 answer a′를 가져온다. Task 모델의 near-misses의 경우 (c′,a′)는 원본 (c,a)와 밀접하게 관련되어 있지만 원래 question, context, 그리고 answer 와의 관계에서 latent semantic 차원(Figure 2)에 따라 종종 다르다. 이후 seq2seq 모델로 새로운 questions q′를 (c′,a′)로 부터 생성한다. 결과적으로 대답 불가능한 또는 잘못 가정된 문제를 피해서 라벨링된 (q′,c′,a′)를 생성한다.
curated set of minimal edit (e.g. Wu et al., 2021b; Ross et al., 2021b),와 비교하여 우리의 방법은 대체 컨텍스트의 사용을 허용하고 생성 단계에서 트리플을 최소 섭동으로 명시적으로 제한하지 않는다. 대신 우리는 noise를 줄이고, 최소 후보를 선택하거나, q와 q′ 사이의 관계를 기반으로 specific semantic phenomena를 선택하기 위해 post-hoc 필터링을 사용한다.
2) Retrieval
REALM retrieve-and-read model of (Guu et al., 2020)을 해당 논문에서 사용하였다.
REALM은 dense retrieval을 위한 BERT 기반 이중 인코더, Wikipedia passages의 dense index, 독해력을 위한 BERT 기반 answer-span extraction 모델로 구성되며 모두 Natural Questions(NQ; Kwiatkowski et al)에 따라 fine-tune 된다.
Answer Generation)
같은 NQ의 subset으로 학습된 T5-3B 모델로 Question generation에 사용된 모델과 같은 hyperparameter를 사용
입력은 "제목»지문" 으로 들어가며 출력은 짧은 answer이다.
Reading Comprehension Model)
Task of span selection-based reading comprehension, 즉 주어진 질문과 구절의 span을 seq2seq 문제로 식별하는 작업
입력은 "질문»제목»지문"
Answer format은 gold answer strings중 하나이다.
T5 Large model / batch size 512 / lr=2×10−4 / 20k steps
Open-domain Question Answering model)
Open domain QA model (Lee et al. (2019))를 REALM checkpoint로 초기화
retriever와 reader 양쪽 모두 BERT-based-uncasd model로부터 초기화 된다.
query와 document representation 128 / lr=10−5 / batch size 1 (in Nvidia V100) / 2epochs로 NQ에 대해 fine-tuned
주어진 질문 q에 대해 REALM 출력은 contexts와 answers의 순위 목록{(c′1,a′1),(c′2,a′2),...(c′k,a′k)}을 제공한다. 이러한 alternate contexts와 answers는 관련이 있지만 다양한 배경 정보를 제공하여 counterfactual 질문을 구성한다.
Question 예시)
q: “Who is the captain ofthe Richmond Football Club" >> “Trent Cotchin"
q′1: “Who captained the team in 1994" >> “Jeff Hogg"
q′2: “Who captained the reserve team in the VFL league" >> “Steve Morris"
Context 예시)
q: “who wrote the treasure of the sierra madre"
우선 원본 책 Sierra Madre, 각색된 영화, Sierra de las Cruces 산맥에서 벌어진 전투에 대한 passages를 retrieve한다. 해당 배경지식이 contextualized counterfactual 생성을 가능하게 한다.
label-transforming counterfactuals에 초점을 맞추기 위해 a와 다른 a′의 (c′i,a′i)는 모두 남겨놓는다.
3) Question Generation
이 component는 답변 context pair (c,a)에 해당하는 질문 q′를 생성한다. T5-3B(Raffel et al., 2020) 모델을 사용하여 NQ에서의 (q,c,a)에 대해 fine-tune을 사용하고 special token으로 표시된 answer과 함께 context passage를 입력으로 사용한다.
{(c′1,a′1),(c′2,a′2),...(c′k,a′k)}로부터 (q′1,q′2,...q′k)를 생성한다. 각 (c′i,a′i)에 대해 beam decoding을 이용하여 15개의 다른 q′를 생성한다.
NQ 데이터에서 short answer과 long answer evidence paragraph를 사용.
Title과 passage는 »로 구분되어되며, short answer는 ‘« answer =’ 와 ‘»’ 로 감싸져 있다.
"제목»지문«answer=정답»"
출력은 original NQ question
input / output 길이: 640 / 256
20k step, lr=2×10−5, dropout: 0,1, batch size: 128, beam size: 15
4) Filtering for Data augmentation
Noise Filtering
Question 생성 모델은 noise가 있을 수 있으므로 c′가 주어졌을 때 대답할 수 없거나 a′가 오답인 질문이 생성될 수 있다. Round-trip consistency (Alberti et al., 2019; Fang et al., 2020)는 기존의 QA모델을 사용하여 생성된 question에 answer하는 방식으로 예측된 answer가 question generator에 제공된 answer와 일치하는지를 확인한다.
다양한 seed로 randomize된 NQ 데이터로 학습한 6개의 T5기반의 독해 ((q,c)⟶a) 모델의 ensemble을 이용한다. 이를 통해 5개 이상의 예측된 answer가 일치하면 keep한다. 비록 noise는 여전히 남아있지만 이는 5%의 데이터를 제거한다.
Filtering for Minimality
생성된 질문 q′의 perturbation 최소화하기 위해 사후 필터링을 사용한다. q에 대한 q′의 semantic shift또는 perturbation을 분류하는 필터링 함수 f(q,q′)를 정의한다. 가장 간단한 방법은 q와 q′ 사이에 word-level edit distance (Levenshtein)를 확인하는 것이다. Noise 필터링 후에 각 (q,c,a)에 대해 f(q,q′)값이 가장 작으면서 a≠a′인 생성된 (q′,c′,a′)를 선택한다. 이런 간단한 선험적인 방법으로 augmentation 실험을 위한 대규모 counterfactual training data를 생성했다. 결과적으로 retrieval을 통해 가져온 latent dimensions에 기반한 counterfactuals의 과도한 생성과 단순한 필터링이 선험적으로 모델이 perturbation 타입의 좁은 집합으로 모델이 편향되는 것을 방지한다.
5) Semantic Filtering for Evaluation
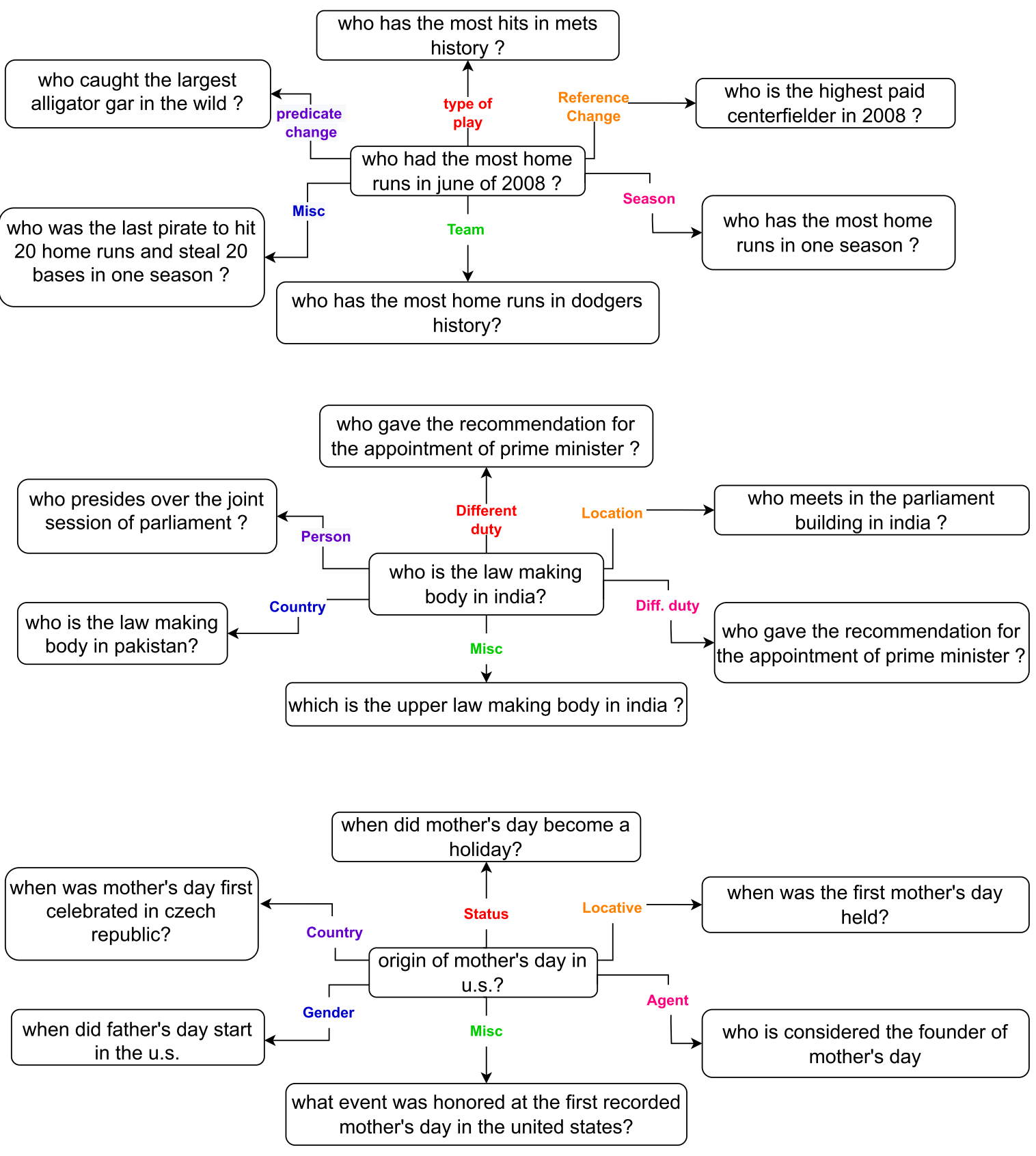
RGF로 생성된 counterfactuals의 종류를 더 잘 이해하기 위해 평가를 위한 (q,q′) 쌍을 분류하기 위한 question meaning representation에 기반한 추가 필터를 적용한다. Meaning representation은 question을 semantic 단위로 분해하고 이러한 단위 중 어떤 것이 perturbed 되는지에 따라 (q, q')를 categorize 하는 방법을 제공한다. 해당 논문에서는 QED 공식을 통해 QA에서 설명하려고 했다. QED decomposition 질문을 술어 템플릿과 reference phrase 세트로 분할한다.
“Who is captain of richmond football club" > “richmond football club" / “Who is captain of X"

Lamm et al. (2021)의 레시피에 따라 question generation을 수행하기 위해 QED dataset에 대한 T5-based model을 fine-tune하고, 이를 사용하여 각 (q, c, a)에서 질문에 대한 술어 및 reference를 식별한다.
Reference 변경을 식별하기 위해서 string 간의 exact match를 사용한다.
술어는 종종 표현에서 약간 다를 수 있기 때문에(who captained vs who is captain) 10개 이상의 글자와 일치하는 접두어로 술어 일치를 취한다.
“Who is the captain of Richmond’s first ever women’s team?", “Who is the captain of the Richmond Football Club" > 같은 predicates
Table 1. 과 같이 reference change, predicates change, 또는 둘 다 총 세 가지로 분류한다.
Intrinsic Evaluation
RGF 데이터를 fluency, correctness, and directionality 세 가지로 평가했다.
1) Fluency
grammaticallly correct 그리고 semantically meaningful.
RGF데이터에서 T5로 생성한 만큼 fluency는 높다. 100개의 생성된 questions에 대해 수작업으로 주석을 달고, 그 중 96%가 fluent했다.
2) Correctness
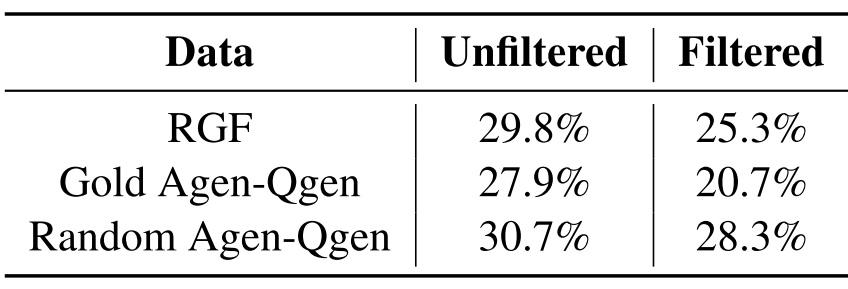
correctness를 q′와 (c′,a′)가 align 되어 있을 때, 즉 주어진 q′에 대해 c′로부터 a′를 대답할 수 있을 때라면, correctness를 정량화 할 수 있다. 100개의 주석된 표본으로 부터 noise 필터 전 30%, 필터 후 25%의 비율을 가지고 있다.
필터링은 각 카테고리 별로 1000개가 되었을 때 실시했다.
3) Directionality/Semantic Diversity

RGF data에서 semantic changes 발생 비율,
| Reference changes | Predicate changes | Question expansionsDisambiguations Contractions |
Negations |
| 50% | 30% | 13% | 1% |
과거 연구에서와 달리 RGF는 선험적 transformation이나 structured meaning representations을 이용하지 않고 이 모든 것이 가능했다.
아래 Figure 6에서 볼 수 있듯이 관계 유형은 semantically 풍부하며 전역적으로 specific-schema로 캡처하기 어려운 각 특정 인스턴스와 관련된 속성을 다룹니다.
Data Augmentation
RGF는 CDA로 바로 사용할 수 있는 fully-labeled (q′,c′,a′) 데이터를 생성한다. Data augmentation은 NQ 학습셋으로부터 임의 추출하여 생성하였다. 이 때 우리는 reading comprehension 및 open-domain QA(5.3)의 두 가지 experimental settings를 탐색하고 NQ에서만 훈련된 RGF-augmented 모델뿐만 아니라 또 다른 생성 baseline 모델과 비교한다. 위에 서술하였듯이 edit-distance based filtering을 통해 생성된 후보들 중 하나의 triple을 선택한다.
1) Baselines
요약하면 모델에서 반대 사실을 생성하기 위해 원래 question에서 c′를 선택하고 해당 c′ 내에서 a′를 생성하고, (c′,a′)로부터 q′을 생성한다. 이 때 RGF는 context를 찾기위해 retrieval 모델을 사용한다.
해당 논문에서 c′를 다른 방법으로 선택하는 두 가지 baseline을 사용하였다.
또한 ensemble한 reading comprehension model을 majority voting 방법과 비교합니다.
Random Passage (Rand. Agen-Qgen)
c′를 원래 question과 아무 상관없는 임의로 추출된 단락이라고 해보자. NQ의 원본 data 분포로부터 생성을 simulate하는 setting이다. Wikipedia 단락의 무작위 샘플링이 유사한 분포를 갖도록 하기 위해 Lewis et al.(2021)의 learned passage selecction 모델을 사용한다. 이 기준선은 SQuAD dataset(Rajpurkar et al., 2016)에 적용된 Bartolo et al.(2021)의 모델에 해당한다. 우리 버전은 NQ에 대해 학습되었으며 AdversarialQA를 생략한다.
Gold Context (Gold Agen-Qgen)
c′를 NQ 훈련 세트의 원래 short answer를 포함하는 passage c 해보자. 이 baseline은 특히 RGF의 retrieval component를 제거하여 alternate passages의 사용이 결과적인 counterfactual question에서 더 많은 diveristy로 이어지는지 여부를 테스트한다.
Answer Generation for Baselines
위의 두 baseline에서 생성한 potential counterfactual question에 대해 answer를 new passage로부터 선택한다. 다양한
NQ에서 question-independent answer selection c→a를 위해 fine-tuned T5(Raffel et al, 2020) 모델을 사용하고 beam search에서 상위 15개 후보를 선택한다. Original question의 반복을 피하기 위해 answer candidates a′ 중 원래 NQ answer a와 일치하지 않는 것만 유지한다. 이러한 alternate generated answer candidates 및 associated passages는 RGF에서와 같이 question generation 및 필터링에 사용된다. Gold Agen-Qgen의 경우, (q,q′) 사이의 가장 긴 edit distance를 기반으로 선택했는데, 이는 무작위 선택 또는 RGF에 사용된 가장 짧은 편집 거리보다 훨씬 더 나은 성능을 제공했다.

NQ Passage는 gold Agen-Qgen, RGF가 제일 덜 perturbation된 데이터 분포를 보여준다.
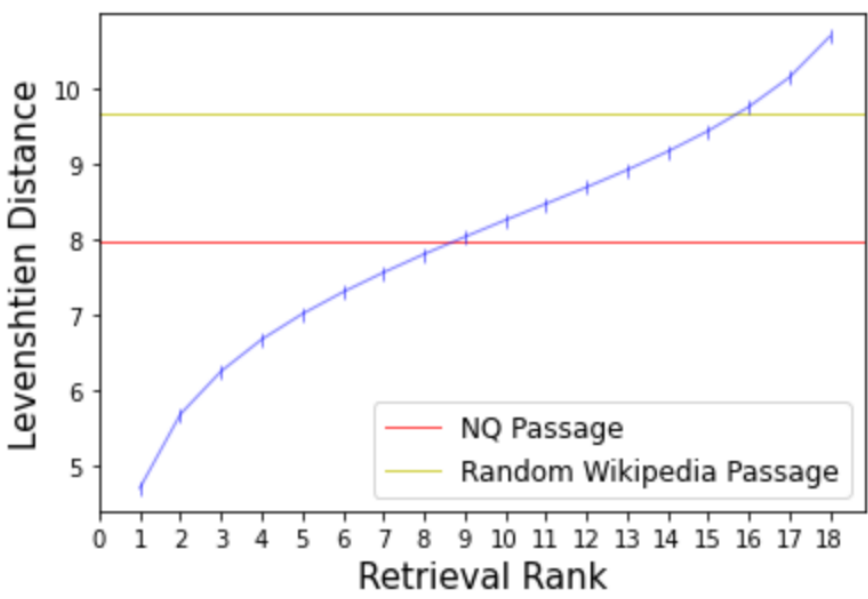
원래 question과 counterfactual question과의 edit distance의 평균을 retrieval rank에 따라 plot 하였다. Edit distance가 rank에 비례하여 단조증가 하는 것을 확인할 수 있다.
2) Reading Comprehension (RC)
RC(Reading Comprehension) 설정에서 input은 question과 context로 구성되며 task는 context에서 answer span을 식별하는 것입니다. 따라서 augment 학습은 (q′,c′,a′)로 한다.
Experimental Setting
T5를 fine-tuning하여 사용하고 입력은 question다음 context가 온다. MRQA 2019 Challenge(Fisch et al., 2019)의 세 가지 evaluation set로 RC 모델의 domain generalization을 평가한다. 또한 SQuAD(Rajpurkar et al., 2016), AQA(adversarially-generated SQuAD 질문, Bartolo et al., 2020)를 포함하여 Wikipedia에서 RC dataset의 counterfactual 또는 perturbed 버전으로 구성된 evaluation set에 대한 성능을 측정한다. 또한 AmbigQA(Min et al., 2020b)를 통해 disambiguated queries를 평가합니다. 이는 구성상 원래 NQ의 쿼리에 대한 최소한의 편집입니다.
Results
다음은 해당 실험에 대한 exact-match 점수이다. F1 score는 유사하다.

RGF는 in-domain NQ에서는 그저 그랬지만, out-of-domain과 challenge-set 평가에서 상당한 성능 향상이 있었다. Original NQ 대비 baseline은 성능 저하도 보이는 반면 RGF는 1~2부터 많게는 BioASQ에서 7 point 향상이 있었다.
세 augmentation method가 유사한 noise비율을 갖고 있는 것에 주목해 볼 때, CDA의 이점은 RC task에 대한 robust features를 더 잘 학습하는 모델의 능력 향상에 기인할 수 있습니다. RC 모델에 ensemble을 사용하면 일부 task에서 약간 향상되지만 RGF만큼 OOD 성능이 향상되지는 않습니다. Gold Agen-Qgen baseline 대비 RGF의 우수한 성능은 전자는 주제와 관련된 질문도 생성하기 때문에 특히 흥미롭다. 우리는 q′가 원래 q에 답하기 위해 near-miss candidate (c′,a′)에서 파생되기 때문에 RGF counterfactuals가 이 baseline과 비교하여 원래 질문과 더 밀접하게 관련되어 있음을 관찰했다.
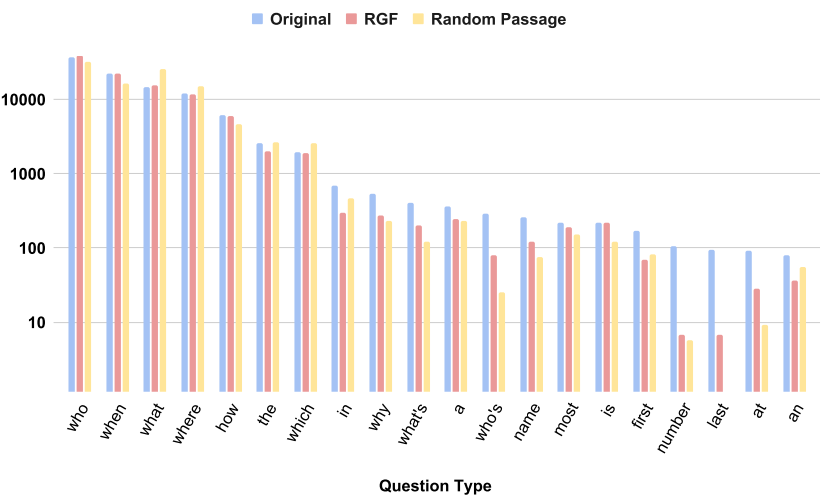
Figure 5는 question type 별 분포를 plot한 것으로 RGF나 baseline 모두 원본 데이터의 bias를 악화시키는 것이 확인됐다.
3) Open-Domain Questioni Answering (OD)
OD에서 question만이 입력으로 제공된다. 생성되고 필터된 q′ 그리고 alternate answer a′으로 구성된 쌍 (q′,a′)이 augmentation에 사용된다. Passages도 변경되는 RC 설정과 비교하여 여기에서 편집 거리 필터링은 augment가 최소한의 perturbation을 나타내도록 한다.
Experimental Setting
NQ의 (q,a)에서 REALM을 미세 조정하기 위해 Guu et al.(2020)의 방법과 구현을 사용합니다. REALM의 End-to-End 학습은 retriever module의 reader 모델과 query document encoder 모두 update한다. 해당 setting은 TriviaQA (Joshi et al., 2017), SQuAD (Rajpurkar et al., 2016), Curated TREC dataset (Min et al., 2021), and disambiguated queries from AmbigQA (Min et al., 2020b) 로 평가한다.
Results
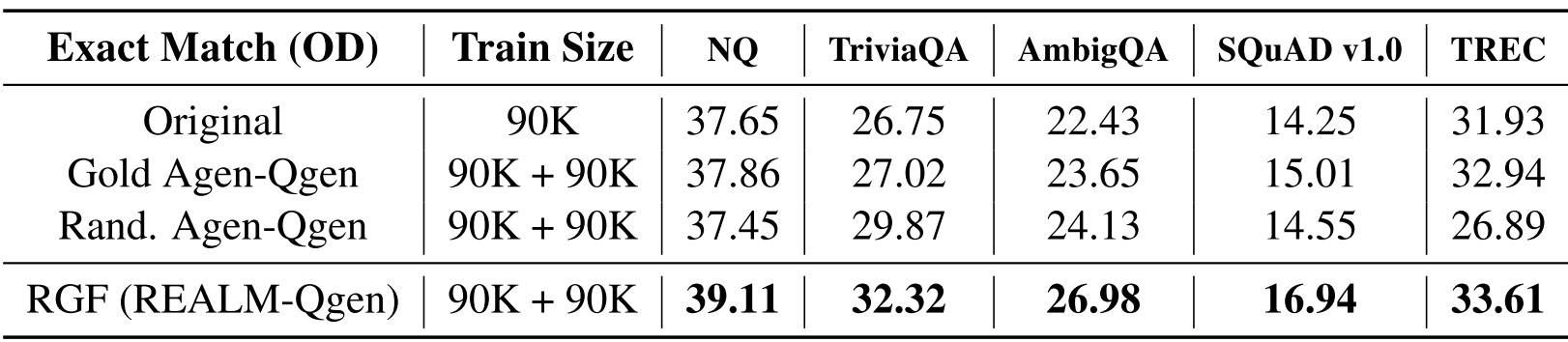
Table 4에서 확인할 수 있는 것과 같이 in-domain NQ에서 2 EM points 상승하였으며 다른 data augmentation 기법과 비교해도 많이 향상되었다. RGF는 baseline 중 성능이 가장 좋았던 Random Agen-Qgen보다 최대 6 EM points(TriviaQA에서) 향상됐다. Open-domain task가 RC보다 더 어렵기 때문에 data augmentation이 이 setting에서 더 많은 이점이 있다고 가정하고 counterfactual query는 model이 retrieval을 개선하기 위해 더 나은 query 및 document representation을 학습하는 데 도움이 될 수 있다.
Analysis
CDA가 model을 개선하는 방법을 더 잘 이해하기 위해 model robustness를 측정하기 위해 local consistency를 통해 RGF에서 가능한 semantic diversity 이점을 보여주기 위해 stratified 분석을 수행합니다.
1) Local Robustness
PAQ(Lewis et al., 2021)와 같은 합성 데이터 방법과 비교하여 RGF는 원래 입력과 쌍을 이루고 local neighborhood에 집중된 counterfactual 예를 생성한다. 따라서 우리는 이 data를 사용한 augmentation이 특히 local consistency, 즉 입력의 작은 perturbation 하에서 모델이 어떻게 동작하는지를 개선해야 한다고 가정합니다.
Experimental Setting
입력의 perturbation에 모델의 local behavior가 어떻게 되는지 측정한다. 구체적으로 만약 모델이 q에 대해 정확하게 answer를 말했다면 f:(q,c)→a, 얼마나 자주 q′에 대해 정확하게 대답하는가? 정확한 예측을 원본 예제에 대해 수행했을 때, pairwise consistency를 counterfactual (q′,a′,c′)에 대해 정의한다:
C(D)=ED[f(q′,c′)=a′|f(q,c)=a]
위 수식으로 consistency를 측정하기 위해 paired examples (q,c,a),(q′,c′,a′) set를 구성했다. QED를 사용하여 데이터들을 분류했다. 구체적으로 두 가지 (a) reference가 변경된 경우 (b) predicate가 변경된 경우 로 분류하였다. 각 유형의 평가 쌍은 1000개가 될 때까지 잘못된 것을 버리도록 data를 수동으로 filtering하여 깨끗한 evaluation set를 만듭니다.
또한 paired version의 AQA, AmbigQA 그리고 QUOREF constrast 세트를 만들었다.
Results

RGF data의 경우 12~14 point 정도 성능 상승이 있었고, AQA, AmbigQA, QUOREF-C의 경우 5~7 point 정도 성능이 향상되었다. The Gold Agen-Qgen baseline (which contains topically related queries about the same passage) also improves consistency over the original model compared to the Random Agen-gen baseline or to the ensemble model, though not by as much as RGF. (떨어졌는데?)

QAQ, AmbigQA, QUOREF에서의 성능향상은 local perturbation 에 대한 모델의 robustness가 향상됐음을 암시한다.
2) Effect of Perturbation Type
QED-based decomposition을 통해 counterfactuals를 label별로 orthogonal한 차원을 따라 생성할 수 있다. 우리는 한 가지 type 변화로 학습이 NLI와 같은 작업에서 관찰된 악영향인 generalization bias를 유도하는지 여부를 조사합니다.
Experimental Setting
학습 data를 각각 predicate와 reference 변화 두 종류로 구분했다. 기준과 일치하는 최소 하나의 q를 찾을 수 있도록 각 원래 교육 예제에 대해 20 (q′,c′,a′)부터 시작하여 과잉 생성한다. 그리고 위와 같이 쌍을 이루는 평가 set도 구성한다.
Results
Counterfactual perturbation을 통한 data augmentation은 baseline NQ model 대비 성능저하가 일어나지 않는다. 또한 한 종류의 augmentation은 perturbation은 orthogonal 이점이 있어 다른 유형의 perturbation 모델 일반화 성능을 향상시키다.
: RGF(ΔPred.)가 RGF(ΔRef.) 성능을 향상시킨다, predicate가 성능 향상폭이 더 큰 것으로보다 reference는 어휘 정보만 변경되기 때문에 predicate가 더 많은 정보를 가지고 있는 것으로 보인다.
3) Effect of Training data size
Low-resouce에서 효과를 확인하기 위해 적은 데이터로 RC, cross-domain setting으로 실험해보았다.
Experimental Setting
NQ데이터로 학습된 모델을 low-resource domain인 BioASQ로 transfer해 보았다. Domain-targeted retrieval model (Ma et al. 2021), 을 사용하여 PubMed corpus로부터 question-passage 쌍을 생성하여 supervised data 없이 학습에 사용했다. 해당 data로 RGF augmentation 후 RC모델을 fine-tune했다.
Results
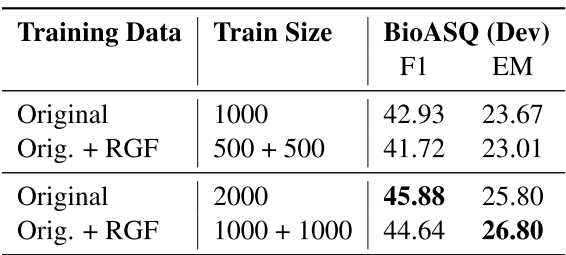
RGF데이터를 추가한 1000+1000이 original 1000개 데이터 대비 F1 2% EM 3% 성능 향상을 보였다. 이는 단순 2000개의 데이터를 학습한 수준과 유사했다. 즉, low-resource 데이터에 적용하는 것이 효과적이다.
'논문 > ACL' 카테고리의 다른 글
| ACL 2022, Findings) What does it take to bake a cake (0) | 2022.09.22 |
|---|---|
| ACL 2022) Composition Sampling for Diverse Conditional Generation (0) | 2022.08.04 |
| BioNLP 2022) Explainable Assessment of Healthcare Articles with QA (0) | 2022.08.03 |


