Explainable Assessment of Healthcare Articles with QA
Alodie Boissonnet1, Marzieh Saeidi2, Vassilis Plachouras2, Andreas Vlachos1,2
1Department of Computer Science, University of Cambridge 2Facebook AI, London
{avmb2,av308}@cam.ac.uk, {marzieh,vplachouras,avlachos}@fb.com Abstract
Proceedings of the BioNLP 2022 workshop, Dublin, Ireland, pages 1–9 May 26, 2022. ©2022 Association for Computational Linguistics
Abstract
인터넷 상에서 healthcare domain에 잘못된 자료들이 많으며, 이를 하나하나 확인하는 것은 불가능하다. 자료에 대한 평가는 text classification 작업으로 자동화할 수 있지만, 사용자가 모델 예측을 신뢰하려면 레이블에 대한 설명이 필요하다. 현재는 이 설명을 summarization을 생성하는 모델로 다루지만, 우리는 여러 기준에 대한 설명 생성을 question and answering (QA) 단일 모델로 수행하는 것을 제안한다. 또한 설명 생성 모델의 평가에 적합한 인간 평가 프로토콩을 소개한다.
1. Introduction
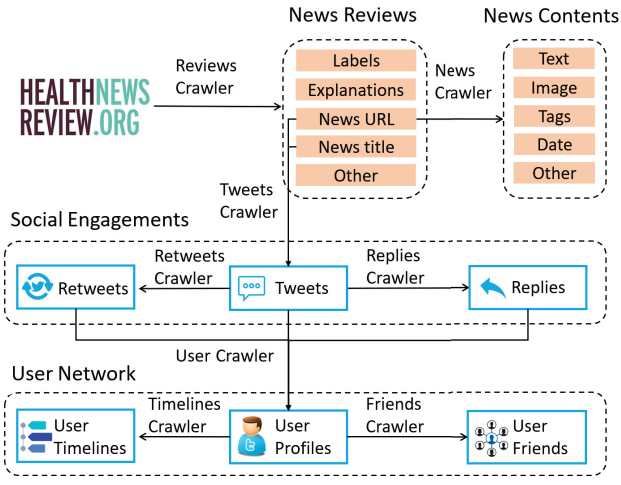
인터넷은 중요한 의료 도구이다. 2017년 Rutten et al. (2019)에 따르면 13.3%의 인구가 의료인에게 묻는 반면, 74.4%의 미국 인구가 건강 관련 정보를 인터넷에서 우선 찾는다. 그러나 질 나쁜 의료 정보가 온라인 상에 범람하고 있다. 다행히도 https://www.healthnewsreview.org와 같은 사이트가 의료 기사를 비판적으로 분석하여 나쁜 품질의 보도를 식별한다. 하지만 이런 수작업은 너무 많은 시간이 소요된다.
Story #1511
Criterion 1: Does the article adequately discuss the costs of the intervention?
Answer: Not Satisfactory
Explanation: There was no discussion of cost as there was in the competing AP story.
Criterion 2: Does the article adequately quantify the benefits of the treatment/test/product/procedure?
Answer: Satisfactory
Explanation: The story adequately quantified the benefits seen in the study that led to FDA approval.
Criterion 3: ...
Table 1: Example of an article evaluated by the Health-NewsReview website. Each article is evaluated according to ten criteria (two shown) and explanations are given to support the answers.
뉴스 기사를 평가는 많은 연구에서 text classification으로 다루었다(Louis and Nenkova, 2013; Chakraborty et al., 2016; Kryscinski et al., 2020).
그러나 예측에 대한 설명은 독자를 설득하는 데 필요함에도 불구하고 최근에야 주목을 받기 시작했다.
예를 들어, Dai et al. (2020) 의료 분야에서 기사 품질 평가를 자동화하기 위해 HealthNewsReview 웹 사이트에서 수행한 평가 작업을 기반으로 설명 없이 기사 분류에만 집중했다. 마찬가지로 Wright와 Augenstein(2021)도 의료 분야에서 과장 탐지 분류를 연구했지만 설명은 없다.
품질 평가를 넘어 분류에 대한 설명 생성을 요약으로 수행하려한 연구도 있다(Atanasova et al., 2020; Kotonya and Toni, 2020).
그러나 이런 방식은 하나의 input text에 대해 하나의 요약만 생성하기에 여러 기준으로 기사를 평가하려 할 때 문제가 발생한다. 즉, 요약을 이용한 방식은 기준 하나 당 모델 하나가 필요하고 따라서 데이터를 나눠써야하는 단점이 있다.
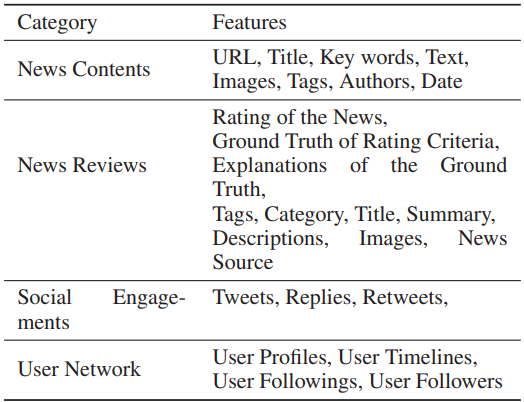
이 논문에서는 health news에 대한 설명가능한 품질 평가 시스템을 개발하였으며, FakeHealth corpus(Dai et al., 2020)로 평가했다. 설명 생성 모델은 QA(Question-swering) 기반으로 각 평가 기준의 정의를 질문 형식으로 고려한다는 점에서 이전 작업과 다르다.
Ginger Cannot Cure Cancer: Battling Fake Health News with a Comprehensive Data Repository
Enyan Dai, Yiwei Sun, Suhang Wang The Pennsylvania State University(ICWSM 2020)
QA를 이용한 접근 방식은 요약 기반의 시스템의 한계를 해결할 수 있다: 모든 기준과 라벨의 인스턴스로 구성된 큰 학습 데이터셋을 이용할 수 있으며, 정보 부족에 관한 설명을 더 잘 생성하고, 모든 기준에 대해 하나의 모델로 학습이 가능하다.
우리는 요약기반 시스템 (Kotonya and Toni (2020))과 비교 분석하였으며, 각각 관련 정보 내용이 기사에 존재하는가 유무에 따라 존재할 시에는 요약 기반이 부재 시에는 QA 기반이 적합했다.
마지막으로 생성된 설명에 대한 평가는 text의 structure와 sense를 모두 고려했다. 과거에는 automatic metrics를 이용하여 설명을 평가하였으나 abstractive 텍스트 생성에는 부적합하였다. 따라서 Mani (2002)는 가독성과 생성된 text의 품질을 평가하기 위해서는 사람이 필요하다고 주장하였다. 유사하게 Kryscineski et al. (2019)는 ROUGE scores가 인간의 판단과 약한 상관 관계가 있으며 사실적 일관성과 같은 중요한 기능을 평가하지 못한다는 점을 강조했다. 따라서 해당 논문에서는 사람이 설명의 fluency, consistency, and factual correctness를 평가하는 프로토콜을 제안한다.
2. Methodology
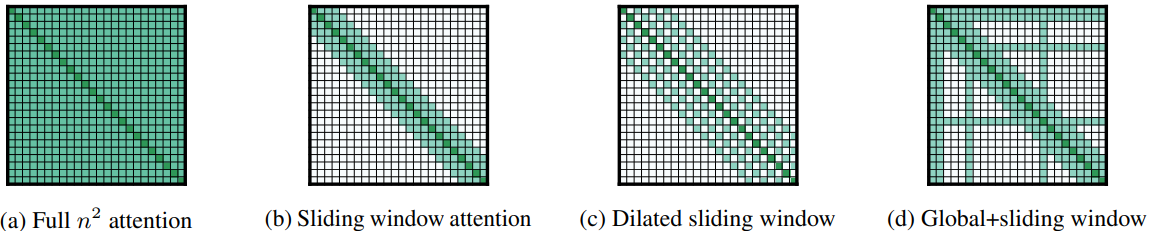
해당 시스템은 우선 기사를 10개의 기준으로 분류하고, 분류 결과를 고려하여 QA를 통해 설명을 생성한다. 다른 평가기준과 관련하여 기사가 만족스러운지 여부를 결정하는 단계가 text 분류이다. 이 때 사용한 것은 단순한 logistic regression, 512tokens로 자르는 BERT-based classification, 기사와 같이 긴 text에 적합한 Longformer-based encoder model 이다. 이 때 BERT와 Longformer는 PubMed로 pre-trained되었고, FakeHealth로 fine-tune했다. Longformer classifier에는 [CLS] 토큰을 global attention mask로 배치하는 classification object를 사용했다. 이 토큰은 input text의 앞에서 전체 text의 표현을 모은다.

두 번째 단계는 사전 예측된 분류로부터 abstractive 설명을 생성하는 것이다. QA접근은 classes와 질문들을 하나의 모델에서 모두 고려한다. Soni and Roberts (2020)에 따라, 해당 논문에서는 SQuAD v2.0으로 1차 학습하고 FakeHealth로 fine-tune된 Longformer 기반의 encoder-decoder(Rajpurkar et al., 2018)를 선택했다. FakeHealth의 gold 설명이 abtractive하기 때문에 모델이 spans of phrases로 설명하는 SQuAD로 1차 trained 됐음에도 완전한 설명을 작성할 수 있도록 학습됐다. 비록 항상 같은 아래의 10가지 질문을 fine-tuning과 평가에 이용하지만 이 방식은 요약 시스템이 처리할 수 없는 기사에서 누락된 정보에 대한 설명을 생성하는 기능 때문에 쿼리 중심 요약과 다르다.

논문에서는 Beltagy et al. (2020)이 소개한 QA objective를 사용합니다. 모든 질문 토큰에 global attention mask를 배치하는 Longformer의 경우, 모델에 기사, 기준 및 분류 예측을 입력한다. 훈련시 잘못 예측된 분류에 대한 설명을 생성하는 것은 의미가 없기 때문에 기사의 glod classes를 사용하여 설명을 생성합니다.

Kotonya and Toni (2020)의 최근 작업에 따라 설명 생성의 baseline으로 요약 모델을 (10개 기준 x 3개 classes) 30개 생성하였다. 이 때 Longformer의 summarization object는 아래와 같다.
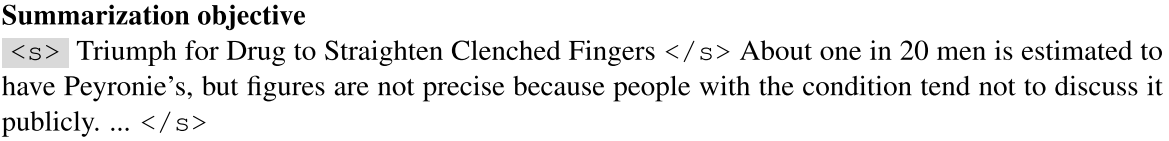
3. Human evaluation of explanations
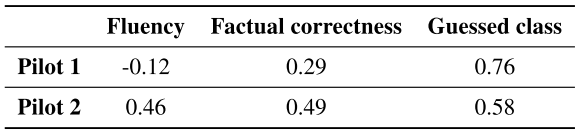
우리는 두 번의 pilot studies를 거쳐 품질 평가에 대한 guideline을 제시했다. Pilot 1은 살짝 애매했던 반면 Pilot2는 높은 inter-annotator agreement score를 달성했다. pilot 2가 더 자세하고 몇 가지 예상되는 질문에 대한 예시를 제공했다. 예를들어 "is explanation fluent?" 를 묻는 대신 "sound natural and their syntactic structure is correct"를 평가하도록 했다. 예를들어 “it’s sunny but it’s sunny”는 유창한 것이 아닌 반면 “it’s sunny but it’s not sunny”는 모순되어 일관성에서 부정적인 점수를 받더라도 유창하다고 판단한다.
4. Data
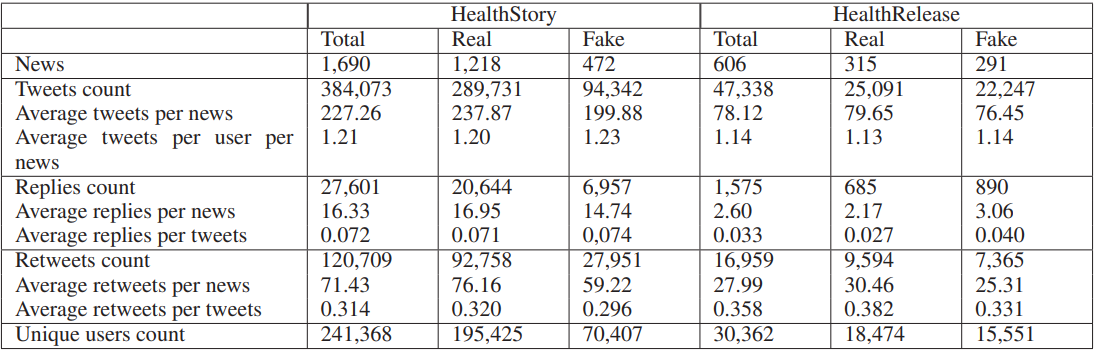
FakeHealth corpus of health news articles - Dai et al. (2020)
각 기사는 최소 두 명 이상의 전문가로부터 10가지 기준(과대 주장, 정보 누락, 출처의 신뢰성 및 이해 충돌, 등)에 의해 평가 받았다.
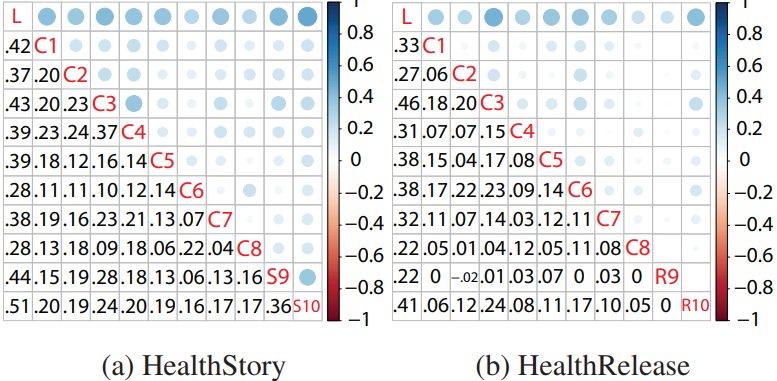
각 기준들 간에 상관관계는 적었으며, 해당 논문에서 S와 R은 합쳐서 하나의 기준으로 취급했다. 각 기준에 대해 Not Satisfactory, Satisfactory, and Not Applicable 로 기사들은 annotate 되었으며, 설명은 해당 라벨의 이유를 설명한다. 각 라벨의 분포는 상당히 불균형을 이루고 있으며 Not Applicable이 가장 희소했다. 예를 들어 기준 2, 4, 6에 대해 Not Satisfactory가 Not Applicable에 비해 65배 많았다.
5. Results
5.1 Quality assessment per criterion
논문에서 Longformer기반, BERT기반, Logistic Regression 기반 모델의 품질 분류 task에서 각 기준에 대한 macro F1-score (F1 score의 평균)을 비교했다.
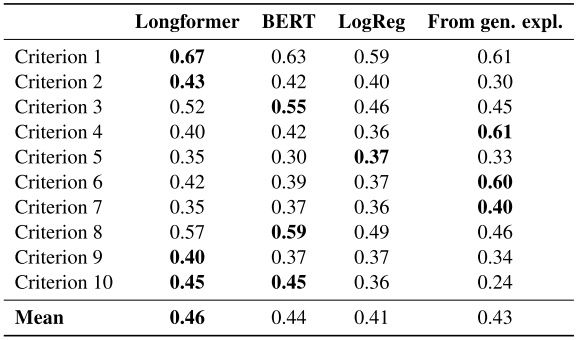
위의 결과로 부터 Longformer가 긴 text를 encode할 수 있기 때문에 성능이 가장 좋았다. Logistic Regression도 단순함에 비해 좋은 결과를 보인것 같지만 데이터의 불균일함 때문에 단순히 지배적인 class로 분류했다. 심층 분석에 의하면 모든 모델은 기준 별로 다른 성능을 보여주었다. 특히 외부 지식 또는 주관적인 판단이 필요한 (예를 들면 criterion 5, asking whether articles commit disease-mongering) 기준은 다루기 힘들다. 또한 기준을 질문으로 처리하고 분류 레이블을 예측하는 QA 기반 접근 방식을 사용하여 한 번에 모든 클래스를 처리하는 단일 Longformer 기반 모델을 구축하려고 시도했지만 제대로 수행되지 않았다. 분류에 QA 기반 모델을 사용한 것이 좋지 못한 결과를 낸 이유로 의심한다.
5.2 Explanation generation
아래의 표는 요약(Sum.) 및 QA 기반 모델의 설명 생성 task 전체 성능을 보여준다.
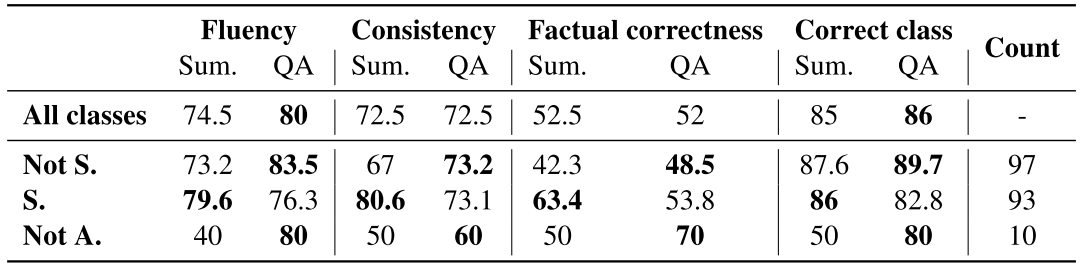
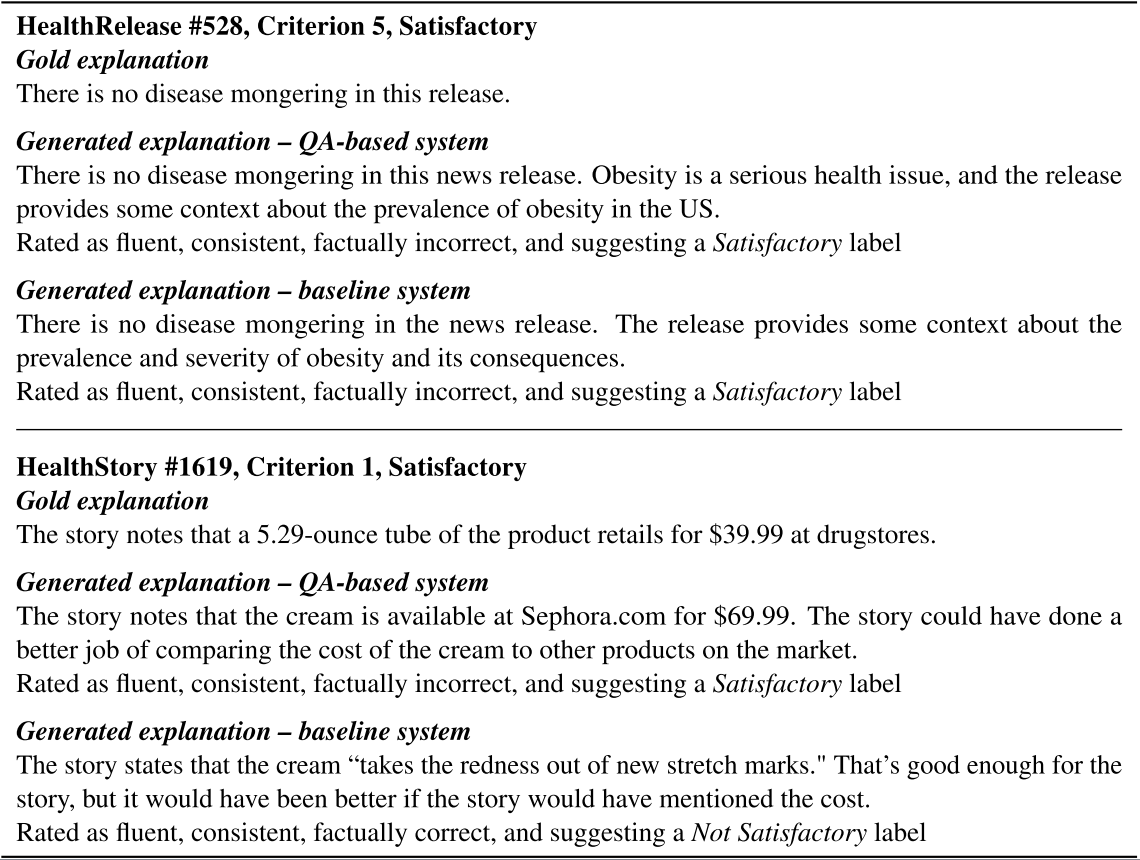
결과를 보면 QA가 좋거나 비슷한 성능을 보여주는 것을 확인할 수 있다. 자세히 들여다보면 일관성과 사실적 정확성의 경우 비슷하지만, 유창함과 정확한 라벨을 제공했다. 아래는 그 중 두 가지 예시이다. Class 별로 분석해보면 요약이 Satisfactory (S.)에 대해서는 더 좋은 성능을 보인 반면, Not Satisfactory 와 Not Applicable classes에서는 QA가 좋은 성능을 보였다. 이는 S.의 경우 기준에 대한 상관 정보가 기사에 포함되어 있어 이를 설명 생성에 사용할 수 있기 때문이다. 반면에 Not S.의 경우 어떤 정보가 누락되는지를 찾아야하는데 이는 요약 모델에서는 어려운 작업이다. 마지막으로 Not A.의 경우 데이터 수가 적기 떄문에 성능을 내기 어렵다. 이 문제는 위에서 언급했던 것과 같이 QA식 접근을 통해 극복 할 수 있다.
따라서 최고 성능을 내기 위해서는 S.에 대해서는 요약 기반의 나머지에 대해서는 QA 기반의 모델을 사용하는 것이 좋다. 이 조합을 통해 81%의 fluent, 76% consistent, 57% factually correct, 85% indicate correct labels를 달성했다. 설명의 사실적 정확성이 매우 낮은 것은 다른 모든 세부사항의 정확성과 상관없이 최소한 하나의 세부사항이 정확하지 않으면 주석가에게 설명을 부정확한 것으로 평가하도록 하는 엄격한 guideline 때문이다.
5.3 Predicting classes from generated explanations
방법을 여러가지를 시도해 보았는데 그 중 하나는 설명 생성을 먼저하고 이를 기반으로 분류를 이후에 하는 것이다. 모델은 같은 것을 사용하였으며 그 결과는 위에 From gen. expl.로 기술되어있다. 분류를 먼저하는 것이 성능이 더 좋았으며 이는 설명 생성모델이 지배적인 classes에 영향을 받는 것을 생각해볼 때 당연한 것이다. 잘못된 설명은 분류 작업에도 영향을 미쳤다. 그러나 4, 6번 기준에 대해서는 설명 생성 후 분류하는 것이 높은 성능을 보였지만 이는 불균일한 데이터 때문이다.
5.4 Automatic v. human evaluation
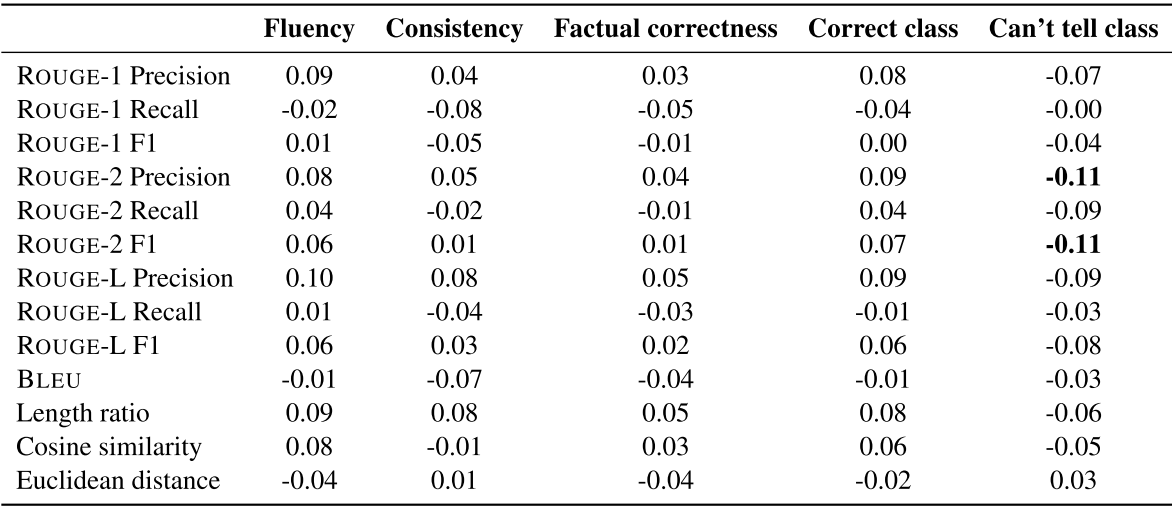
마지막으로 사람 판단과 autometic metrics(ROUGE, BLEU)의 상관관계를 분석하였다. Kendall's Tau를 이용해서 비교해보면 ROUGE는 0.11 BLEU는 0.07이 가장 높은 값이다. 이는 대부분의 matrics가 단어 중첩에 초점을 맞췄기 때문에 문법이나 구문 분석 사실적 일관성을 파악하는데는 부족하다.
6. Conclusion and discussion
이 논문에서는 설명 생성에 QA 기반 접근을 사용하였다. 이는 다양한 기준에 대해 하나의 모델로 학습이 가능하며, 요약 기반의 모델에 비해 경쟁력이 있으며 서로 상호 보완적인 결과를 보여줬다. QA 기반 접근은 기사 내에 정보가 없거나 class 양이 적은 경우 좋은 효과를 보여주었다. Longformer 기반의 모델이 긴 input text를 지원하기 때문에 좋은 성능을 보여주었다. Automatic metric (ROUGE와 같은)은 설명 생성 모델 평가에 대해 사람이 판단하는 것과 낮은 상관성을 보여주었다.
'논문 > ACL' 카테고리의 다른 글
| ACL 2022, Findings) What does it take to bake a cake (0) | 2022.09.22 |
|---|---|
| ACL 2022) Retrieval-guided Counterfactual Generation for QA (0) | 2022.08.16 |
| ACL 2022) Composition Sampling for Diverse Conditional Generation (0) | 2022.08.04 |


