
Abstract
문서는 fine granularity(e.g., words), medium granularity(e.g., paragraphs or figures), coarse granularity(e.g., the whole page)와 같이 계층적 구조로 이루어져 있다. 각 granularity 수준 차이와 계층적 상관관계는 문서 이미지 파악에 중요하다. 과거의 모델 중 word-level 모델은 상위 계층의 정보를 활용하지 못하는 반면 region-level 모델은 paragraphs 나 text blocks를 단일 embedding하여 word-level 특징을 뽑는데는 부족했다. 이러만 문제에 입각하여 MGDoc을 제안한다. Multi-modal multi-granular pre-training framework로 page-level , region-level, 그리고 word-level 정보를 동시에 인코딩 한다. MGDoc은 unified text-visual encoder를 이용하여 multi-modal 특징들을 얻는다. Region-word 상관관계를 cross-granular attention mechanism과 구체적인 pre-training task를 통해 학습한다. 이렇게 만들어진 모델은 downstream task에서도 성능향상을 보여주었다.
1. Introduction
문서 이미지는 text와 layout 패턴을 통한 풍부한 정보를 가지고 있어 이를 처리하는데 어려움이 있다. 여기서 layout pattern은 문서 내의 각각의 region으로 나누어 준다. Fig1을 보면 fine-grained textual content가 특정 양식에 맞게 분포한 것을 알 수 있다.
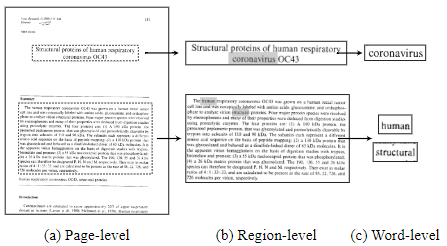
영수증 우측하단 표의 숫자가 가격 총합을 얘기해 주는 것과 같이 각 level은 중요한 정보를 가지고 있으며 이는 서로 관계가 있다.
page-level: 영수증 양식
region-level: 표 또는 제목
word/token-level: 폰트, 숫자
따라서 서로 다른 level 간의 계층적 구조를 잘 encoding하는 모델이 필요하다
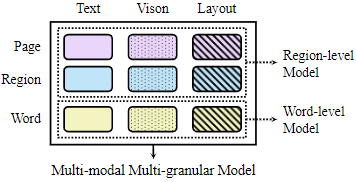
과거의 연구들이 region-level이나 word-level에서만 이루어졌다는 것에 입각하여 해당 논문에선 fig.2와 같이 MGDoc을 제안한다. 구체적으로 OCR engine을 사용하여 문서 페이지를 page-level, region-level, 그리고 word-level로 나눈다. 서로 다른 granularity level 입력 간의 상관 관계를 학습하기 위해 attention을 활용하고 계층적 구조와 상대적 거리를 인코딩하기 위해 특별한 attention weights를 추가한다. 다른 level에서의 region을 정렬하고 사전학습을 통해 이를 학습한다. 추가적으로 masked language modeling을 word-level의 입력에 사용하고 더 coarse-grained 입력에 확장한다. 일정 비율의 region을 mask하고 이를 맞추도록 했다.
이후 public benchmark인 FUNSD, CORD, RVL-CDIP를 통해 MGDoc의 효과를 확인해보았다.
본 논문의 기여는 다음과 같다.
- Multi-modal multi-granular pre-training framework
- Cross-granularity attention mechanism 과 새로운 pre-training task
- Benchmark에서는 효과적인 MGDoc 성능
2. Method
2.1 Overview
MGDoc framework는 특징을 문서 페이지의 granularity의 수준의 차이로 부터 encode하여 공간적 계층구조간의 차이를 이용한다. 해당 아키텍쳐는 세 개의 stage가 있다.
첫 째로, OCR engine, human annotations, 또는 digital parsing을 통해 granularity 수준에 따른 text와 bounding boxes를 제공받는다. 해당 논문에서는 pages, regions, 그리고 words 수준에서 집중하였다. 해당 세 수준으로 textual content, image, 그리고 bounding boxes를 입력하여 text와 image embedding을 생성하도록 했다. 과거 방식을 (Xu et al., 2020b) 참고하여 공간적 embedding을 이용하여 공간적인 layout 정보를 encoding하였다.
다음 multi-granular attention mechanism을 통해 각 다른 수준에서의 특징간 상관관계를 추출했다. 해당 attention은 특성들 간에 내적 계산하고 attention bias를 추가해 region과 words 간의 계층적 관계를 encode한다. 그 후 cross-attention mechanism을 사용해 각기 다른 modalities 간 특징을 합친다.
마지막으로 최종 text와 visual 특징들의 합은 pre-training 이나 fine-tuning task에 사용된다.

2.2 Multi-modal Encoding
입력을 얻기 위해서 모든 granualarity에 따른 입력이 text와 bounding box로 정의한다
word-level: text와 각 단어의 bounding box
region-level: words이 region으로 묶이고 묶인 모든 단어의 인접한 bounding box
page-lebel: page내의 모든 단어가 textual 입력이 되고 document image의 width와 heigh가 bounding box
이 입력을 $P, \{R1, ..., R_m\}, \{w_1, ..., w_n\}$ 이 때 $m, n$은 region과 word의 수다
Textual content는 pre-trained language model e.g. SBERT (Reimers and Gurevych, 2019)를 사용하여 encode한다. Text encoder에 fully-connected layer를 사용하여 bounding boxes를 hyperspace로 전사시켜 공간적 임베딩을 추가한다. 그 다음 MGDoc 은 전체 이미지를 visual 특성 추출기 e.g., ResNet (He et al., 2016)를 이용하여 이미지를 encode하고 bounding boxes를 Region of Interest(ROI)로 사용하여 region 특성을 추출한다. Vision encoder의 결과는 다른 크기의 bounding boxes로 인해 다른 해상도를 가지지만 같은 특성 공간에 놓인다. 유사하게 공간 임베딩을 bounding boxes를 이용하여 visual 임베딩에 추가한다. Multi-modal 임베딩은 다음과 같이 표현된다.
$$ e^T_\lambda = \texttt{Enc}^T(text_\lambda) + \texttt{FC}(box_\lambda) + \texttt{Emb}^T $$
$$ e^V_\lambda = \texttt{Enc}^V(img)[box_\lambda] + \texttt{FC}(box_\lambda) + \texttt{Emb}^V$$
여기서 $e^T, e^V$는 text와 visual 임베딩을 의미한다; $\lambda \in \{P\} \cup \{R1, ..., R_m\} \cup \{w_1, ..., w_n\}$ 각 다른 granularity level을 의미한다. $\texttt{Enc}^T, \texttt{Enc}^V$는 각각 text와 visual 인코더이다.
$\texttt{Emb}^T$, $\texttt{Emb}^V$는 type embedding이다.
2.3 Multi-Granular Attention
Region-word 상관관계를 강화하기 위해 self-attention 가중치에 편향을 더 한다. 다른 granularity 수준 간의 상호작용을 학습하는 것이 이 module의 목적이므로 modality 표현은 생략한다.
$$A_{\alpha, \beta}=\frac{1}{\sqrt{d}}(W^Qe_\alpha)^\top (W^Ke_\beta)$$
$$+\texttt{HierBias}(box_\alpha \in or \notin box_\beta) $$
$$+\texttt{RelBias}(box_\alpha - box_\beta)$$
$\alpha, \beta\in \{P\} \cup \{R_1,...,R_m\} \cup \{w_1, ..., w_n\}$
처음 파트는 단순 cross-attention이며, RelBias는 bounding box 기준으로 상대적 거리를 편향으로 더해준다. HierBias는 page 내에서 공간적 계층 구조에 속하는지 여부를 가중치 편향으로 추가한다. 각 단어는 특정 group을 이뤄 특정 region에 속하므로 고정된 길이의 벡터에 이진으로 관계를 포함하여 attention head에 더해준다. 이후 self-attention이 입력 임베딩에 적용되어 문맥적 정보와 계층적 관계를 학습한다.
$f_\lambda^T, f_\lambda^V$
$\lambda \in \{P\} \cup \{R_1,...,R_m\} \cup \{w_1, ..., w_n\}$
는 각 text, vision feature는 위와 같다.
2.4 Cross-modal Attention
Modality fusion을 위해 cross-modal attention 이용한다.
$$\texttt{CrossAttn} (\alpha|\beta)=\sigma(\frac{(W^Q\alpha)^\top (W^K\beta)}{\sqrt{d}})W^V\beta$$
여기서 $\alpha$와 $\beta$는 같은 크기 행렬이며, $\sigma$는 softmax 함수이다. $W$는 학습 가능한 가중치이며, $Q, K, V$는 각각 query, key 그리고 value 이다.
여기서 다른 수준의 granularity에서의 text, vision 특성을 $F^T=\{f^T_\lambda\}$와 $F^V=\{f^V_\lambda\}$라 하면, multi-modal 특성은 다음과 같다,
$$ f_\lambda ^{T \rightarrow V} = \texttt{CrossAttn} (F^T|F^V)[\lambda] $$
$$ f_\lambda ^{V \rightarrow T} = \texttt{CrossAttn} (F^V|F^T)[\lambda] $$
결국 최종 multi-modal 특성은
$$ f_\lambda = f_\lambda ^{T \rightarrow V} + f_\lambda ^{V \rightarrow T}, \lambda \in \{P\} \cup \{R_1,...,R_m\} \cup \{w_1, ..., w_n\} $$
2.5 Pre-training Tasks
고전적인 masking 방식을 넘어서서 mask text modeling 과 mask vision modeling 을 모든 입력의 다른 수준의 granularity에 적용한다. 이를 통해 다른 수준의 granularity 공간적 상관 관계를 모델이 학습한다. 최종 학습 손실은 각각의 pre-training tasks의 합이다. $ L = L_{MTM}+L_{MVM}+L_{MGM}$
Mask Text Modeling
일정 비율의 region 또는 words을 special token [MASK]로 교체한다. 손실 함수는 Mean Absolute Error를 사용한다.
$$ L_{MTM}=\sum_{\lambda \in \Lambda} \left| e^T_\lambda - f^{V \rightarrow T}_{\texttt{[MASK]} | \bar{\lambda}} \right| $$
$$ \Lambda = f_\lambda ^{T \rightarrow V} + f_\lambda ^{V \rightarrow T}, \lambda \in \{P\} \cup \{R_1,...,R_m\} \cup \{w_1, ..., w_n\} $$
$e^T_\lambda$는 textual contents
$\bar{\lambda}$는 $\lambda$를 제외한 multi-granular context
$f^{V \rightarrow T}_{\texttt{[MASK]} | \bar{\lambda}} $ 는 masked textual 입력의 문맥적 특성
Mask Vision Modeling
Text modeling 처럼 [MASK] token으로 교체하는 것과는 달리 선택된 구역의 visual embedding을 0 벡터로 설정한다. 손실함수는 Mean Absolute Error를 masked 구역과 원래 visual embedding의 문맥 특성 간의 Mean Absolute Error를 계산한다.
$$ L_{MVM}=\sum_{\lambda \in \Lambda} \left| e^V_\lambda - f^{T \rightarrow V}_{\texttt{[0]} | \bar{\lambda}} \right| $$
$ f^{T \rightarrow V}_{\texttt{[0]} | \bar{\lambda}} $은 masking 되지 않은 입력이 주어진 0 벡터의 문맥 특징
Multi-Granularity Modeling
모델은 region 수준과 word 수준에서 특성을 통해 어느 region에 word가 위치해있었는지 예측한다. Score를 region과 word 수준의 특성들의 내적으로 구한 후 Cross-entropy를 통해 손실을 구한다.
$$L_{MGM}=\sum_{w \in W} \frac{e^{f^\top_w f_{r^*}}}{e^{f^\top_w f_{r^*} + \sum _{r_\in R-\{r^*\}}e^{f^\top_w f_{r}}}}$$
여기서 $ W={w_1,....,w_n} $이고 $R={R_1,...,R_m}$.
$r^*$는 $w$ word를 포함하고 있는 region이다.
3. Experiments
3.1 Pre-training Settings
사용된 데이터: RVL-CDIP 400,000 grey-scale 이미지
Layout 및 word 추출: EasyOCR을 두 가지 출력 방식 non-paragraph와 paragraph 이용. 여기서 paragraph 방식의 출력을 region 수준 입력으로 사용하였다.
3.2 Fine-tuning Tasks
- Form Understanding
FUNSD Dataset 199개의 fully-annotated noisy-scanned form으로 149/50 개의 train/test로 구성된다. 각 entity는 Header, Question, Answer 로 분류된다. - Receipt Understanding
CORD Dataset 800/100 개의 train/test로 구성되는 영수증 데이터로 bounding box와 textual contents로 fully annotated 되어있다. 30개의 entity로 분류된다. - Document Image Classification
RVL-CDIP Dataset 400,000개의 문서 페이지로 구성되며 16개로 분류되는 IIT-CDIP의 subset 데이터이다. 입력 특성들은 EasyOCR로 추출한다. RVL-CDIP는 pre-training 단계에서 사용되나 정답을 주지 않기 때문에 정보 유출 문제는 없다. train/valid/test는 8:1:1 비율로 나누어 사용했다.
3.3 Implementation Details
- Multi-modal encoder로 "BERT-NLI-STSb-base" model을 text encoder로 "ResNet-50"을 vision encoder로 사용
- 12 layer of cross-modal attention
- Hidden states 768
- Head number 12
- Freeze the pre-trained weights of the multi-modal encoder
- 5 epochs pre-training 8 NVIDIA V100 32G GPU
- AdamW optimizer
- Batch size 64
- Learning rate 1e-6
- 초기 20% training step warm up
3.4 Results

RVL-CDIP에서 LayoutLMv2와 TILT는 Microsoft OCR와 BROS는 CLOVA OCR와 같이 상용 OCR을 사용하기 때문에 더 높은 OCR 결과를 가지고 더 적은 학습 매개 변수 더 적은 사전 학습 데이터로 좋은 결과를 보여준다.
3.5 Abalation Study
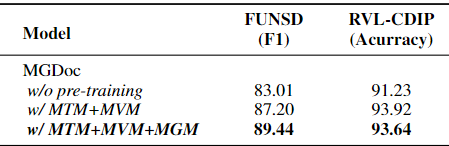
사전 학습이 6.43%, 2.69% FUNSD와 RVL-CDIP에서 향상
MGM이 2.24%, -0.28% FUNSD와 RVL-CDIP에서 향상
Words와 regions의 지역 관계를 학습하는 것은 fine-grained task에서 도움 될 수 있으나 coarse-grained task에서는 노이즈를 발생 시킬 수 있다.
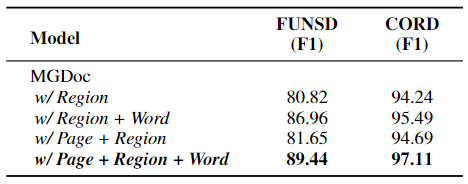
따라서 각 granularity 특성의 역할을 공부하기 위해 Table 3 실험을 수행
word 수준의 특성이 성능 향상에 제일 많이 기여한다.
3.6 Region-word Correlation Visualization

Figure 5. 에서 4개의 샘플을 FUNSD에서 뽑아 마지막 특성의 내적을 히트맵으로 표시하였다. 히트맵을 통해 볼 때 대각선 성분이 하이라이트 된 것을 확인할 수 있는데 이는 모델이 region-word의 계층적 구조를 잘 사전 학습단계에서 배워서 down-stream task에 적용한 것을 알 수 있다. 그 외의 다른 하이라이트 된 부분을 통해 원래 모델의 입력이 직렬화 되어 있는 것을 고려해보면 처음 직관대로 granularity의 수준이 다른 정보를 합치는 것이 도움 됐다는 것을 알 수 있다.
3.7 Error Analysis
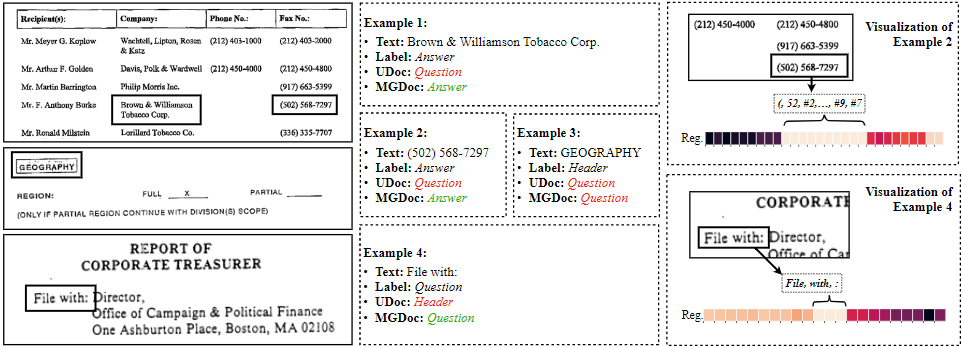
UDoc과 MGDoc의 비교에서 대표적인 몇 가지 사례를 선정하여 Figure 4에 나타냈다. \
Example 2에서 UDoc의 경우 Question과 Answer 사이의 거리가 멀어서 예측을 잘못하는 반면 MGDoc은 밝은 히트맵에서 알 수 있는것처럼 단어 수준의 정보를 다른 multi-modal 특성 통해 잘 강화하여 올바른 답을 한다.
Example 4에서 visual 특성을 잘 활용하여 UDoc이 하지못한 올바른 예측을 하였다.
반면에 example 3에서는 두 모델 모두 예측에 실패하였다. 이 경우 일반적으로 header가 등장하는 최상단에 위치하지 않았기 때문에 발생하는 오류로 MGDoc이 공간 정보활용의 의존성 때문이다.
4. Related Word
Word-level Models
skip
Region-level Models
해당 모델은 문서 page를 encode한다. 유사한 spatial and visual 특징이 모델에서 사용된다. 해당 모델들은 high-level cues를 잘 잡아낸다. 또한 word-level model 대비 긴 문서를 적용하는 것에 효과적이다.
5. Conclusions and Future Work
본 논문에서는 MGDoc이라는 granularity의 다양한 수준을 반영할 수 잇는 모델을 제안한다. Multi-modal encoder로 pages, regions, 그리고 words로 부터 특징을 같은 hyperspace로 embed하고 multi-granular attention mechanism과 multi-granularity modeling task를 통해 MGDoc이 더 나은 공간적 계층 관계를 학습하도록 한다. 실험을 통해 해당 모델이 downstream task에서 성능 향상이 존재하는 것을 보였다.
Limitations
기존 region-level 모델 대비 word-level 정보도 사용하기 때문에 많은 메모리를 필요로 한다.



