
Abstract
- Document understanding transformer인 Dessurt를 소개
- Document image와 task string을 입력으로 받고 autoregressive하게 텍스트를 출력
- End-to-end 아키텍쳐로 document understanding에 text recognition까지 추가로 수행
- 9개의 다른 task에 대해 효과적인 성능을 달성
Introduction
Document understanding 분야에 많은 연구가 진행중이며 대표적으로 LayoutLM이 있다.
- LayoutLM Family
- BERT-like transformers에 spatial/layout 정보와 visual feature 추가
- Document image로 사전학습되었으며 각 task로 미세조정
- (한계1) Encoder-only 모델이기 때문에 input token에 대한 예측만 가능하고 추가적인 출력이 불가능
- (한계 2) 외부 OCR 모델을 통해 text를 추출해야 하기 때문에 OCR 성능에 영향을 받음
위 한계를 극복하기 위해 Dessurt(Document end-to-end self-supervised understanding and recognition transformer)를 소개한다.
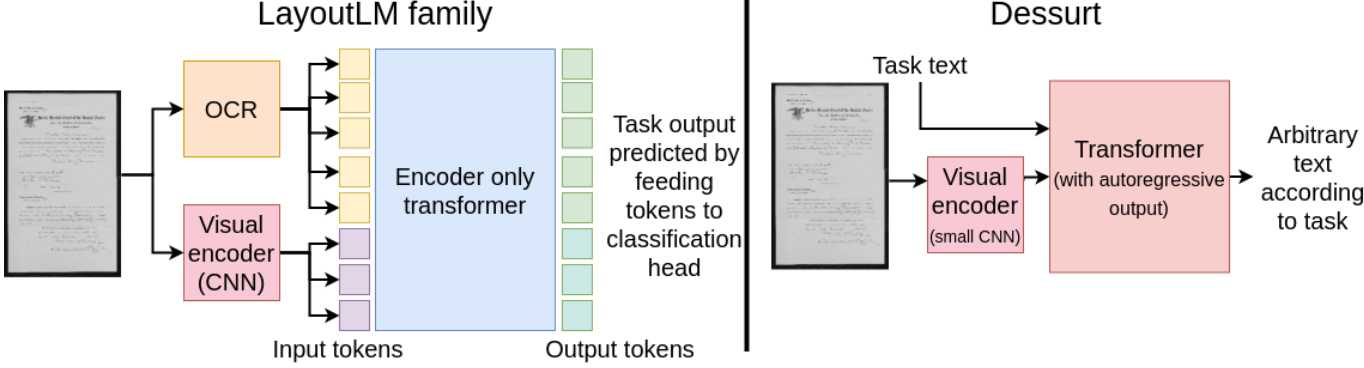
- Dessurt (https://github.com/herobd/dessurt)
- End-to-end로 수행 (text segmentation과 recognition을 암시적으로 학습)
- Auto-regressive 출력
- IIT-CDIP 데이터로 사전 학습 (masked language modeling) + 3 synthetic document dataset
- 문서 구조 parsing과 텍스트 위치를 읽기 위한 새로운 사전학습 제안
- 모델 평가 (DocVQA, HW-SQuAD, FUNSD, NAF, IAM handwriting, RVL-CDIP)
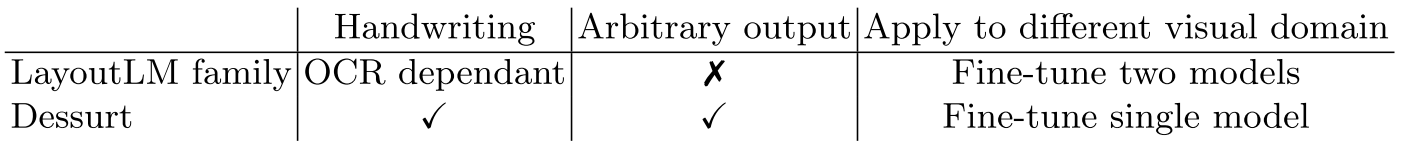
출력에 제한이 없기 때문에 parsing task (form image → JSON) 도 가능하다. 또한 다른 도메인을 학습할 때 하나의 모델만 미세조정 하면 된다.
Related Work
1. LayoutLM Family
LayoutLM은 BERT와 굉장히 유사하지만 spatial position 정보를 추가했다. BROS와 TILT 및 LayoutLMv2는 biased attention을 architecture를 도입하여 spatial 정보를 더 활용했다. LayoutLMv2는 visual tokens도 도입하여 layout정보를 spatial보단 visual하게 포착하고자 하였다. DocFormer는 textual 과 visual 특징을 동시에 업데이트 하려고 했다. TILT와 DocFormer는 공간적으로 text token 근처의 visual 특징만 사용하였으나 LayoutLMv2는 전체 문서의 visual token을 사용했다.
2. End-to-End Models
LayoutLM 계열은 text recognition을 고려하지 않았다. end-to-end는 인식과 이해를 한번에 하고자 하는 목적이 있다. DocReader는 end-to-end 방법으로 핵심 정보를 추출한다. 반면에 외부 OCR에 의존하지만 RNN을 사용하여 임의의 텍스트를 예측할 수 있다. Donut의 경우 Dessurt와 유사하게 Swin 인코더를 이용하지만 BART-like 디코더를 사용한다. Donut은 주로 cross-attention이 방식과 pre-training에서 Dessurt와 다르다.
Model
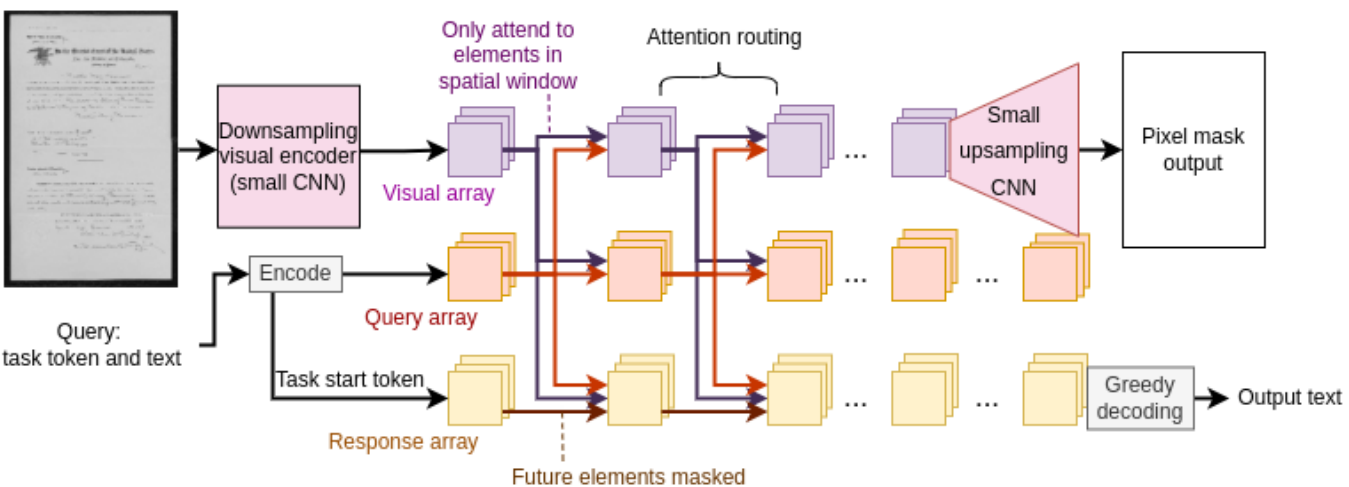
Dessurt는 입력으로 image와 query text를 받으며 출력으로 임의의 text를 주어진 task에 대해 반환한다. Fig 2.에서 architecture에서 세 토큰을 확인할 수 있다. 1. Visual token 2. Query token (model 이 수행할 task) 3. Autoregressive response token (출력이 생성될 곳)
- Input encoding
- 입력 (image + query token string)
- Swin은 고정된 image를 입력 받음 (본 모델에서는 1152 x 768로 고정, 한 페이지를 전부 처리했을 때 글자를 읽을 수 있도록 큰 사이즈가 필요)
- 입력 image는 2-channeled (grayscale + 몇 작업에 사용된 highlight mask)
- Query token은 task와 관련된 context를 제공 (e.g. the qustion text)
- Response token은 task specific start token 으로 시작(학습시 teacher-forcing)
- Image는 작은 downsampling CNN을 통해 2d spatial embedding을 더한다
- Query와 response text는 BART와 동일하게 처리하며 sinusoidal position embedding 수행
- Cross-attention
- Response에 정보를 전달하기 위한 목적
- Visual array의 Swin layer는 다른 요소의 local window 뿐만아니라 query 배열도 처리하도록 수정 (biased attention이 visual 요소에 남아있다.)
- Query 배열은 일반적인 transformer attention을 사용하지만 전체 visual 배열에도 attention을 한다
- Response 배열은 일반적인 이전 response 요소에 autoregressive한 attention처리 뿐만 아니라 visual과 query 배열 attention도 수행한다
- 8개의 cross-attention layer가 있으며 마지막 두개의 layer는 query와 response만 모델에서 업데이트하며 두 layer 모두 마지막 visual 특성에 사용
- Output decoding
- Greedy decoding 사용
- 학습에 사용된 pixel mask 출력. 작은 upsampling network(6 transpose convolution)로 마지막 visual 특성을 생성
Pre-training Procedure
여러 작업이 연결된 각 dataset로 여러 dataset을 사전 학습한다.

1. IIT-CDIP dataset
OCR이 해당 데이터에 적용되었으며 이를 이용한 여러 task를 적용하였다. 가장 많이 사용한 방법은 (2/3 빈도로 발생) Text Infilling task이다. 이는 BART를 학습시키기 위한 masked language modeling 으로 blank token으로 text위치의 image를 대체한다. 전체 텍스트 블럭과 삭제된 영역은 입력 하이라이트 channel에서 Fig 3.와 같이 마킹됐다. 그러면 모델은 전체 블럭을 예측하고 지워진 영역을 채워야한다. 그 외에도 한 단어만 삭제한다던지 RC 문제를 학습하기도 했다.
*자세한 추가 내용은 supplment에
2. Synthetic Wikipedia
Wikipedia에서 임의의 기사, column width, 폰트, text height, 간격 들을 선정하여 문단을 생성 후 이어붙여 image를 생성한다.(Fig. 3 (b)) 폰트는 1001fonts.com 에서 10,000개의 폰트를 받아서 사용했다. IIT-CDIP와 같은 분포의 task를 적용했다.
3. Synthetic Handwriting
기존의 IIT-CDIP나 IAM과 같은 데이터에서 손글씨 데이터 수는 너무 적다. 따라서 Davis et al.[7]이 제안한 전체 줄 손글씨 생성 방법을 활용하여 Wikipedia 기사로부터 각 줄마다 다른 스타일을 적용하여 800,000 줄의 데이터를 생성했다. Synthetic Wikipedia와 같이 전부 임의로 선택해서 데이터를 생성했다. (Fig. 3(c))
4. Synthetic Forms
FUNSD 데이터의 주석 구조를 기반으로 표를 추가하여 양식을 생성한다. GPT-2를 이용 "This form has been filled out" prompt를 통해 새로운 줄과 라벨쌍을 콜론으로 구분하여 얻는다. 문서 내에 더 이상 배치할 수 없는 수준이 될 때까지 반복하여 생성한다. 주요 작업은 문서를 JSON으로 parsing하는 것이다. (Fig.3 (d)) 또한 엔티티를 예측하고 연결하는 작업도 있다.
5. Distillation
Dessurt는 독특한 아키텍처를 가지고 있어 사전 학습된 transformer를 사용할 수 없다. 그래서 cross-domain distilllation 방식으로 사전 학습된 지식을 이전시켰다. Text를 사전학습된 transformer(teacher)에게 입력하고 출력을 문서 image로 render하여 Dessurt(student)에게 전달했다. 손실은 Hinton et al. 이 제안한 student와 teacher의 logit predictions의 차이로 주어진다. ("dark knowledge")
Distillation은 일반적으로 student와 teacher에 같은 입력을 넣는다. 따라서 동등한 입력을 넣기 위해서 textual에서 visual로 변환하여 넣는다.
아키텍쳐적으로 유사한 모델을 사용해야하기 때문에 BART를 사용한다. BART와 Dessurt 모두 Text Infilling task를 수행한다. BART는 MLM을 수행하고 Dessurt는 비어있는 지역의 text와 render된 image도 예측한다.
6. Training
- 학습 초반에는 curriculum 방식으로 인식률을 높이고자 했다.
- 초기에는 생성된 Wiki 데이터 small images (96 x 384)의 단순 읽기 task를 150,000 iteration을 진행
- 이후 full size의 생성된 Wiki 데이터를 이용하여 200,000 iterations을 수행
- Abalation study 용으로 사전 학습된 모델은 모든 datasets과 tasks에 대해 10M iterations 를 수행하며 curriculum을 따른다.
- 6개 Nvidia Tesla P100, batch size=1, gradient accumulation=128, 7,800 가중치 업데이트 (abalation model), 마지막 4M iteration의 gradient accumulation=64, AdamW optimizer, learning rate=10E-4, weight decay=0.01
Experiments
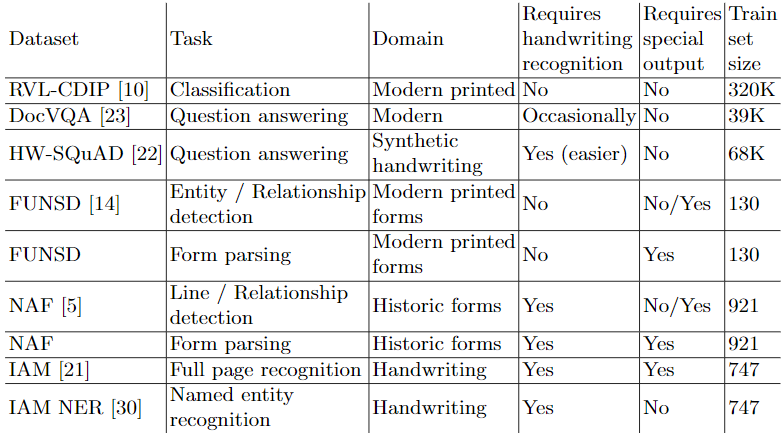
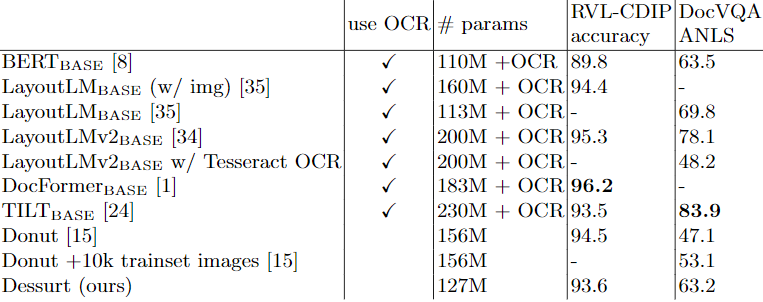
1. RVL-CDIP
Document classification 작업에 대해 Dessurt는 Swin architecture로 적은 매개변수를 가지고 SOTA와 비견할만한 성능을 보여준다
2. DocVQA 와 HW-SQuAD
DocVQA는 텍스트를 이해하는 것이 RVL-CDIP보다 중요하기 때문에 Dessurt와 Donut는 제한된 성능을 보여준다. 다른 모델은 인식 방법에 의존하며 LayoutLMv2에 인식률이 안좋은 Tesseract를 사용할 경우 상당한 성능저하를 관찰할 수 있다. Dessurt는 언어 중심의 사전 학습 진행했기 때문에 Donut보다 좋은 성능을 보여준다. Dessurt가 DocVQA에서 성능저하가 발생하는 이유는 figure/diagrams와 image/photo가 사전학습에 포함되지 않았기 때문이다.
HW-SQuAD의 경우 손글씨 SQuAD로 답이 포함된 문서를 평가하고자 하였다. 이전 작업은 QA가 아니라 snippet retrieval 이였기 때무네 직접적인 비교가 불가능하며 Dessurt의 경우 ANLS로 55.5%이다.
3. FUNSD and NAF
Form parsing을 예측하기 위해 모델은 사전 학습에 사용된 것과 같이 JSON 형태를 사용한다. 기존에는 Normalized tree edit-distance(nTED) 방법을 이용하여 문서 parses를 비교한다. 그러나 nTED의 경우 순서가 중요하기 때문에 순서에 관대한 Greedily-Aligned nTED (GAnTED) 를 소개한다. Predicted bounding boxes에서 Tesseract를 사용하여 JSON 출력을 작성함으로써 FUDGE에 대한 GAnTED를 계산한다.
Entity recognition 및 relation detection를 Dessurt로 예측할 경우 디코더 모델이기 떄문에 string을 출력 후 align한다. 단순히 token이 속한 ground truth box를 식별하는 다른 모델과 달리 정확한 text를 출력해야하기 때문에 Dessurt의 recognition에도 영향을 받는다. 따라서 다른 모델들의 성능보다 저조한 성능을 보여준다.


NAF의 경우 OCR을 사용한 모델이 없다. NAF가 과거의 문서 양식을 사용하는 만큼 U.S.A. 1940 Census로 학습하여 성능도 비교했다.
4. IAM Database

Table. 6에 full-page recognition 모델들을 비교했다. 사용된 평가 지표는 전체 페이지 당 Character error rate (CER)와 Word error rate (WER)이다. Dessurt는 가장 낮은 WER을 기록하였으며 이는 사전 학습 단계에서 IAM의 데이터로부터 synthetic handwriting 데이터를 만들어서 사용했기 때문일 수 있다. WER이 CER보다 상대적으로 낮은 것은 다른 모델이 character prediction을 사용하는 것에 비해 token prediction을 사용하기 때문이다.

IAM NER task 평가는 Tuselmann et al. 이 소개한 방법을 사용하여 두 단계로 이루어 진다. 그들은 단어 수준의 손글씨 recognition 모델로 얻은 결과를 RoBERTa NER 모델에 입력한다. Dessurt는 line-level NER과 document-level NER 수준에서 미세 조정한다. 손글씨 분류는 다음 두 task로 (1) 단어를 읽고 분류 (2) 분류를 선행. 또한 Dessurt recognition 능력 의존도를 줄이기 위해 임의로 단어를 교체(teacher-forcing withclose edit-distance word)한다. 또한 Table 7. 에서 IAM 로 사전학습한 모델도 확인했다.
어느 정도 성능을 보여주었지만 Tuselmann et al. 이 제시한 2단계 방법에는 미치지 못했다. 그들이 사용하는 handwriting recognition model(HWR)의 CER이 6.8인데 이는 Dessurt와 유사하며, Roberta 가 Dessurt보다 강력한 언어모델인 것을 다시 보여준다.
5. Abalation
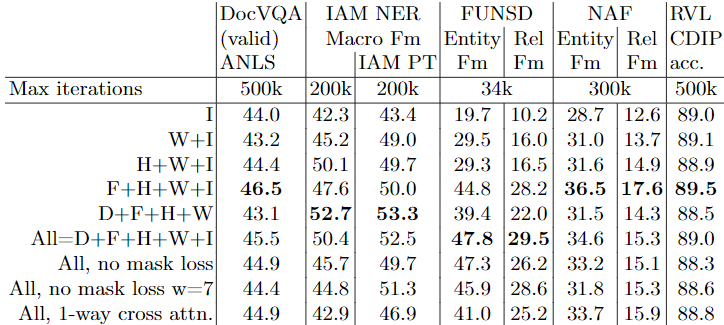
사전학습에 synthetic handwriting과 synthetic forms가 추가됨에 따라 특정 downstream task을 목적으로 사용했지만 일반적으로 다른 task의 성능도 올려준다. 단지 distillation 만이 선택적으로 도움되었다. RVL-CDIP 결과는 사전학습 방식에 크게 영향을 받지 않았다.
Conclusion
- 다양한 문서 문제를 위한 end-to-end architecture
- Autoregressive 한 text 출력



