The Harvard USPTO Patent Dataset:A Large-Scale, Well-Structured, and Multi-Purpose Corpus of Patent Applications
enjoythehobby2023. 9. 13. 17:23
Abstract
The Harard USPTO Patent Dataset(HUPD)를 제안
2004년부터 2018년까지의 USPTO 특허
4.5M 특허 문서
특허 출원 버전이 포함됨 (최초)
다양한 메타데이터 제공
Patent decision의 이진분류 작업을 제안
위 작업에 대한 concept shift에 대한 연구 가능
Multi-class classification, language modeling, 그리고 요약이 가능하며 시연
1 Introduction
지난 20년 동안 미국 특허상표청(USPTO)에 제출된 연간 특허 출원 건수는 거의 두 배로 늘어났다. 2020 회계연도에만 USPTO는 계속 심사 요청을 포함해 650,000건 이상의 특허 출원을 접수했다.
Table 1: Comparison of HUPD with other datasets whose primary goal is NLP patent analysis. The abbreviated columns mean the following. Abst: Abstract, Appl: Applicant Information, Exam: Examiner Information, Invt: Inventor Information, PD: Publication Date, Bkgd: Background, Dsc: Description, and PCs: IPC/CPC codes.
Table. 1에서처럼 특허 연구를 위한 다양한 데이터들이 생성되었지만 한계가 존재한다. 위 dataset들은 등록된 특허에만 집중되어있다. (Section D 참고) 따라서 공공의 무료의 광범위하고 포괄적인 특허데이터가 필요했고 우린 4.5M개의 2004년부터 2018년까지 출원된 USPTO 영어 특허 문서 HUPD를 제안한다.
기존 데이터와의 차이점
출원 당시의 claims와 description이 포함
개정 단계에서의 승인 및 거부에 따른 data shift를 확인할 수 있으며 특허 승인 이진 분류와 같은 연구가 가능
HUPD에는 출원일, 세분화된 분류 코드, 심사관 정보 등을 포함하여 34개 필드가 포함
Google과 같은 검색엔진(BigPatent처럼)이 아닌 USPTO정보를 직접 이용
Figure 1: Three pages of the pre-grant version of an example patent document (Method and Apparatus for Initiating a Transaction on a Mobile Device [Publication No: 2014-0207675 A1]). The highlighted sections show a subset of the 34 data fields that we include in the Harvard USPTO Patent Dataset.
HUPD는 다양한 목적을 염두하고 생성한 데이터로 'abstractive summerization', 'information retrieval', 'named entity recognition', 'extraction' 뿐 아니라 '시간에 따른 특허 승인 변화'에 대한 연구도 가능하다. 특허 전문가들에게는 특허 출원 및 심사와 관련된 작업의 효율성 및 비용 절감에 기여할 수 있다.
2 Preliminaries and Background
특허 출원은 일반적으로 title, abstract, set of claims, detailed description, drawings 및 기타 서면 사양 중에서 관련 출원에 대한 상호 참조(있는 경우)로 구성됩니다. 출원된 특허는 심사관에 의해 심사되며, 심사관은 출원인에게 USPTO의 결정을 알립니다. 결정이 호의적이라면 신청자는 USPTO가 특허를 등록하도록 선택할 수 있다. 그러나 결정이 불리할 경우 신청자는 거절 통지를 받는다. 계속해서 신청을 진행하며 재심사를 요청할지 여부를 결정하는 것은 신청자에게 달려 있다. HUPD에서는 특허청에서 최종 또는 비최종 거부 조치를 받고 궁극적으로 신청자가 포기한 경우 해당 응용 프로그램을 “거부됨”으로 표시한다. 아직 USPTO의 응답을 기다리고 있는 나머지 모든 신청은 "보류 중"으로 분류된다. 상기 데이터를 통해 특허 승인 여부를 예측할 수 있는 작업을 할 수 있다.
3 Related Work on Patent Analysis
Automated Subject Classification.
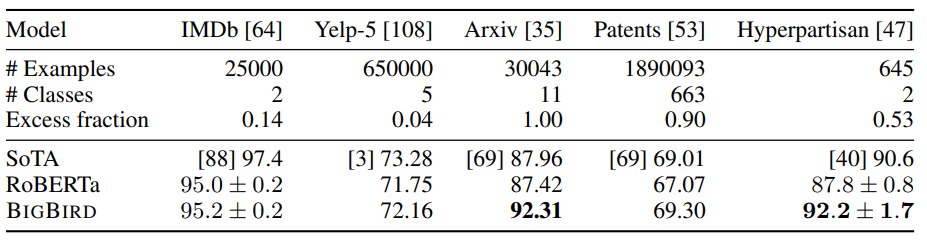
특허는 표준 분류법인 International Patent Classification (IPC) 와 Cooperative Patent Classification (CPC) 로 주제에 따라 분류된다. 지난 연구들에서는 계측적인 IPC나 CPC를 class 혹은 subclass 수준에서 통계적인 방법을 동원하여 분류하고자 했다. 최근에는 트랜스포머를 적용한 특허분류 연구가 PatentBERT나 Bigbird 논문에서 진행된 바 있다.
Classification results. We report the F1 micro-averaged score for all datasets. Experiments on smaller IMDb and Hyperpartisan datasets are repeated 5 times and the average performance is presented along with standard deviation.
Table. 1을 과 같이 기존에 분류에 많이 쓰이던 WIPO-alpha, CLEF-IP, 및 USPTO-2M은 상대적으로 좁은 범위의 특허 텍스트 및 메타데이터 세트가 포함되어 있으며 사용자가 집중할 연도 범위를 선택할 수 없다.
Patent Text Generation and Summarization.
특허 텍스트 생성과 요약과 관련된 연구는 Sharma et al. 이 BigQuery를 이용하여 1971년부터 2018년까지의 USPTO 1.3M의 특허 문서를 수집한 BigPatent로 지난 몇 년 수행되었다.
BigPatent와 HUPD의 차이점 (1) 더 많은 메타데이터와 필드 (2) 승인 결과와 그에 해당하는 문서 (3) 세 배 더 많은 문서 수
Patent Acceptance Prediction.
HUPD는 텍스트 관점에서 특허 승인 및 거절에 대한 특성을 분석할 수 있는 유일한 데이터이다. 관련하여 특허 승인 예측 task를 제안한다.
4 The Dataset
Construction.
특허 출원 텍스트는 USPTO Bulk Data Storage System(BDSS, 특허 출원 데이터/XML 버전)에서 XML 파일로 얻었다. 원본 데이터 양식은 각기 상이하기 때문에 정규표현식을 이용하여 데이터를 parsing 후 JSON 형태로 구조화했다. Acceptance decisions, filing dates, titles, 및 classification information은 2021년 2월 USPTO 특허 심사 연구 데이터 세트 파일에서 따로 메타데이터를 추출하여 2020년 이전에 출원된 특허 자료와 연결시켜 준다. 이 과정 덕분에 업데이트된 메타데이터와 출원 문서 텍스트까지 포함된다.
마지막으로 출원 문서의 등록 여부를 "Accepted", "Rejected", "Pending", "CONT-Accepted", "CONT-Rejected" 및 "CONT-Pending" 6가지로 분류하였으며 접두어 "CONT-"는 이전 출원 버전이 존재하는 경우에 해당한다.
Statistics.
Table 2: Brief description of and average number of tokens in each text-based section in our dataset. Typically, the description section in a patent application is almost 100 times longer than the abstract section.
Table.2 에서 텍스트 기반의 각 section의 통계를 제공한다.
Binary Decision Classification
2011년 1월부터 2016년 12월 사이에 USPTO에 제출된 특허 출원을 살펴보고 대기 중인 출원을 실험에서 제외했다. 처음에 우리는 가장 일반적인 IPC subclass에서 특허 출원의 등록 가능성을 예측하기 위해 NB 분류기부터 RoBERTa에 이르는 개별 도메인별 분류기를 훈련했습니다(Figure. 2). 우리는 abstract와 claims를 각각 별도로 사용했습니다.
Figure 10: Distribution of decision status labels for patents filed between 2011 and 2016. Note that the relative share of pending to rejected applications increases over time as certain patents remain under review beyond the end of our metadata collection period. Approximately three quarters of patent applications are labeled as new filings.
Label의 불균형 문제를 해결하기 위해(Figure. 10) 가중치가 적용된 무작위 샘플러를 사용하여 샘플을 선택했다. 그런 다음 데이터를 85/15로 분할하여 무작위로 배분했지만 공정한 비교를 보장하기 위해 각 범주의 각 모델에 걸쳐 무작위 시드를 수정했다.
Limitations.
이미지는 제외하고 영어로 구성된 텍스트로만 제한되어 있으며, 너무 긴 텍스트나 처리할수 없는 단어가 문제를 야기할 수 있다.
Potential Biases.
2011년부터 2016년 사이에 USPTO에 제출된 특허 출원에 중점을 두고 발명자의 성별, 기업 규모, 특허 발명자의 지리적 위치와 특허 결과 간의 상관 관계를 조사했다. USPTO에서 여성 발명가가 눈에 띄게 과소되고, 소규모 및 미시적 실체(예: 독립 발명가, 소규모 기업)가 회사, 비영리 조직은 대기업(예: 직원이 500명 이상인 회사)보다 특허 획득에 있어 긍정적인 결과를 얻을 가능성이 낮으며, 특허 출원 및 승인률이 미국 전역에 균일하게 분포되지 않는다. (본문 Section C 참고)
Ethical Consideration.
동기, 목표, 수집 프로세스, 작업 흐름, 사용 사례, 배포, 유지 관리, 잠재적 기여 및 오용 가능성에 대해 논의했다.
Table 3: Summary of the four NLP tasks presented in this work, along with some evaluation metrics for them. Our dataset can be used to conduct many other NLP/IP experiments. See Section 5 for detailed information.
Patent Acceptance Prediction.
출원서를 바탕으로 해당 출원이 USPTO에서 승인될지 여부를 예측한다. NLP 커뮤니티의 관점에서 볼 때 이는 표준 분류 작업이지만 이 결정 작업의 잠재적인 응용 프로그램과 이점은 난이도뿐 아니라 일반적인 이진 분류 벤치마크(예: SST, Yelp)와도 구별된다. 실험에서는 모든 'CONT-' 를 제외했다. 또한 'pending' 중인 신청서는 포함되지 않는다.
Automated Subject Classification.
출원서 텍스트(일부 하위 집합)를 바탕으로 특허 출원서의 Primary IPC 또는 CPC 코드를 예측하는 것이다. 실험 설정에서는 IPC 코드가 CPC 코드보다 더 큰 특허 세트에 사용 가능하므로 subclass 수준에서 주요 IPC 코드를 예측한다. CPC와 IPC의 subclass 수준에서 중복은 99.6%이다.
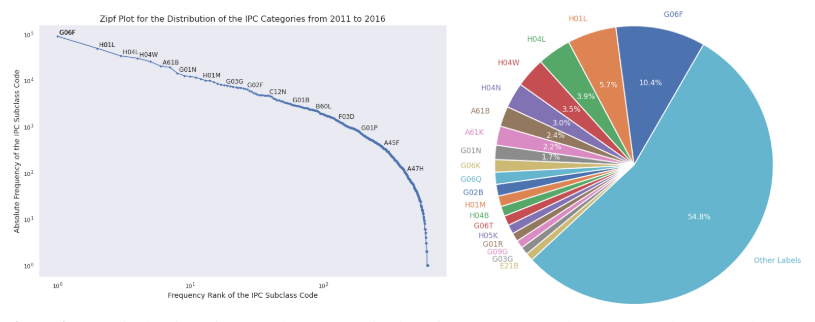
Figure 2: IPC distribution of accepted patent applications from 2011 to 2016 at the IPC subclass level. There are 637 IPC subclass labels in HUPD, of which the most common 20 codes make up half of the distribution. G06F-Electric Digital Data Processing is the largest IPC subclass, accounting for 10.4% of applications.
subclass 수준에서 label은 637개가 존재하며 균일하게 분포하지 않는다.(Figure. 2)
Language Modeling.
다음은 claims의 masked LM을 고려한다. 청구항은 특허의 권리를 주장하는 텍스트이기 때문에 독특한 언어 스타일을 가지고 있다. 일반 자연어와 비슷한 abstract에 대해서도 LM 실험을 진행한다. 이러한 언어 모델은 다운스트림 작업은 물론 도메인별 조사에도 사용할 수 있다
Figure 11: Visualizations of the vector representations of the data fields (abstract, summary, and title) of patent applications, embedded using four different Transformer models. Of these four models, two were fine-tuned on HUPD (Fine-tuned DistilRoBERTa and Fine-tuned T5-Small) and two were off-the-shelf, pre-trained models (RoBERTa-Base and Mini-LM v2). The Mini-LM v2 model was trained on a paraphrase dataset to produce good sentence-embeddings for text clustering. To create the figures above, we randomly sampled 500 patent applications from each of the top nine IPC categories for each year from 2008 to 2018. For each data field and each model, we computed embedding vectors using the model and reduced the dimensionality of these vectors using PCA. The above plots show the results of this dimensionality reduction, colored by IPC codes. We see that categories cluster strongly and similar categories (e.g., H04W-Wireless Communication and H04L-Transmission ofDigital Information) are often close in embedding space.Figure 13: Depiction of the evolution over time of the averaged embeddings of the abstracts of patent applications from G06Q-Data Processing Systems or Methods relative to the other popular IPC codes in our dataset. To create this figure, as in the figures above, we randomly sampled 500 patent applications from each of the top nine IPC categories for each year from 2008 to 2018. Using our custom DistilRoBERTa model, we computed embedding vectors for the abstracts of each patent application and then reduced the dimensionality of these vectors using UMAP. The figure above shows the average UMAP embedding of the G06Q category for every other year, along with the average embeddings of the other categories (averaged across all samples from all years). The movement of the centroids of the G06Q category might be consistent with covariate shift over time in the distribution of language of patents in the category. G06F-Electric Digital Data Processing seems to move closer to H04L-Transmission ofDigital Information/H04W-Wireless Communication. This evolution seems to be consistent with the digitization of data processing methods over the past two decades.
Abstractive Summarization.
각 특허에는 신청자가 특허 내용을 요약한 abstract가 포함되어 있다. 이 내용을 ground truth로하여 abstractive summerization task를 수행하며, 입력은 claims나 description을 이용한다. 여기서 Sharma et al. 와 동일하게 조건부 생성 작업을 수행하며, 유일한 차이점은 claims도 입력으로 사용할 수 있다는 것이다.
6 Results and Discussion
위의 tasks에 대해 subsets of Bernoulli and Multinomial naive Bayes classifiers, logistic regression (Logistic), CNN, DistilBERT, BERT, DistilROBERTa, RoBERTa, and T5-Small 들을 baseline으로 사용했다.
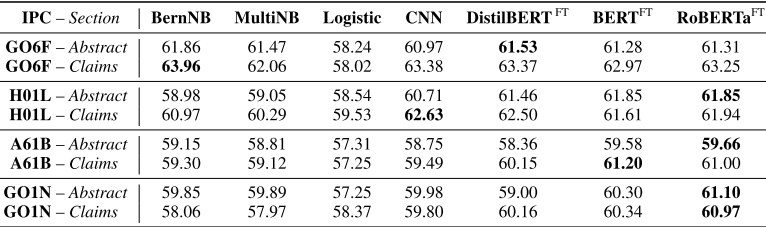
Patent Acceptance Prediction.
Table 4. 는 높은 빈도의 4개의 IPC에 대한 특허 등록 여부에 대한 예측 성능을 보여준다. G01N을 제외하고는 각 모델에서 claims를 활용하는 것이 더 좋은 성능을 보여준다. 놀라운 점은 NB 분류기나 BERT가 큰 성능차이를 보여주지 않는다는 것이다. BERT 모델이 결국 NB처럼 단어 수준의 feature 추출만 수행했다고 볼 수 있다.
Table 4: Baseline performances of our models on the binary classification of patent acceptance task. All the models were trained and evaluated on the patent applications filed to the USPTO between January 2011 and December 2016. All the test sets contained equal numbers of accepted and rejected applications, so the baseline accuracy to compare these models against is 50%. In all but one IPC category, the models trained on the claims sections yielded the best performance. None of the individual accuracy scores, however, went beyond 64%. In Section 7, we further report results on our conditional universal acceptance prediction classifier. The superscript FT on the Transformers denotes that these models were fine-tuned, not trained from scratch. (See Table 7 for our full results and Table 8 for English descriptions of the four-digit IPC codes.)
Automated Subject Classification.
IPC/CPC를 받은 등록된 특허만 사용했다. Table. 5는 TOP1과 TOP5의 multi-class IPC 분류를 subclass 수준에서 수행한 결과이다. 모델이 고도화될수록 성능이 향상되는데 claims로 훈련된 DistilBERT가 TOP1에서 63%, TOP5에서 90%의 정확도를 보여준다. 가장 많이 등장하는 class의 경우 TOP1은 10% TOP5는 26.5% 이므로 해당 결과는 주목할만하다. Figure.8 에서도 minor한 label에 대해 잘 분류하는 것을 확인할 수 있다. 또한 abstract로 학습한 결과가 claims와 많이 차이나지 않았으며, 당연하게도 subclass 대신 class대한 분류 성능은 훨씬 좋고 이에 대한 DistilBERT의 TOP1 성능은 80%이다.
Table 5: Performances of our models on the multi-class IPC classification of patent codes at the subclass level. Our DistilBERT models yielded the best performance overall under both abstract and claims input setups. TOP1 (i.e., accuracy) checks whether our prediction is the same as the actual label, whereas TOP5 measures whether the actual label of the input is amongst our five top predictions (i.e., five classes with the highest probability weights). Our high TOP5 scores indicate that our models are good at predicting the IPC codes of both popular and underrepresented classes— Figure 8 also provides evidence towards this conclusion.Figure 8: Confusion matrix of IPC code classification at the subclass level. This matrix was obtained from the DistilBERT model that was fine-tuned on the abstract sections. The IPC codes were ordered by their sizes from left to right and from top to bottom, respectively. The light diagonal line present on the center figure represents high recall values. The diagonal line disappears towards the lower right corner, since patents belonging to those IPC subclasses do not appear in our test set.
Language Modeling.
BERT 스타일의 특허 청구에 대한 마스크된 언어 모델을 훈련했습니다. 우리는 2011년부터 2016년까지의 특허 출원(157만 건)으로 구성된 전체 특허 데이터 세트의 일부에 대해 학습하고 2017년의 모든 특허 출원(187,000건)으로 평가했다. DistilRoBERTa를 OpenWebtext로 초기화한 MLM수행 모델을 공개한다.
Abstractive Summarization.
Table. 6에서 description과 claims 모두 효과적으로 abstract로 요약될 수 있는 것을 확인했다.
Table 6: Performances of our T5 summarization models on HUPD, as measured by ROUGE. Higher numbers reflect better performance. Summarization from the claims performs better than summarization from the description. Although our ROUGE scores are higher than those reported by Sharma et al. [46] on BIGPATENT, the scores are not directly comparable, since the evaluation data and tokenization schemes are different.
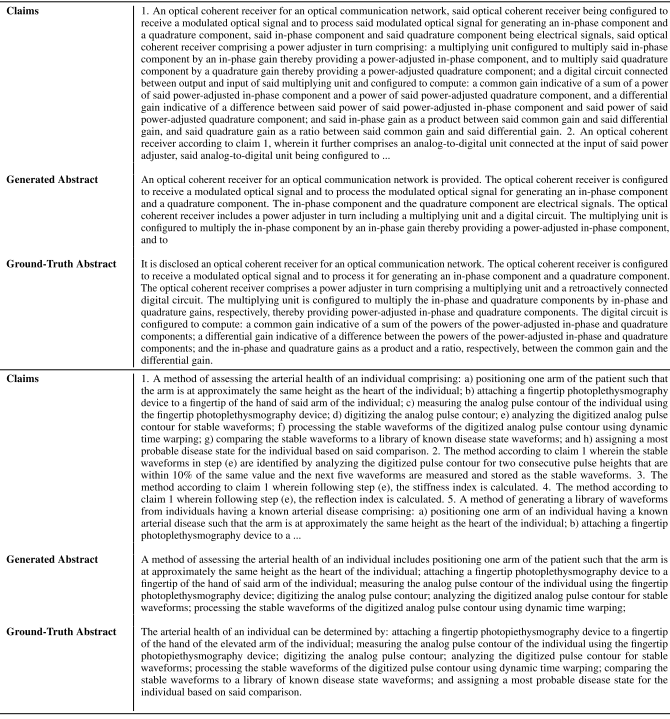
모델은 Table. 10과 같이 유창한 요약을 생성해낸다.
Table 10: Examples of claims summaries produced by our T5-Small model. Qualitatively, the models produce fluent patent abstracts complete with accurate details drawn from the claims section. Note also how different the structure of the above legal language is from most text used to train large language model; often, the entire abstract is a single long and complex sentence.
7 Evolution of Innovation Criteria and Trends over Time
데이터 셋이 시간과 상태 변화 개념을 나타내는 방법에 대해 논의 한다.
Universal Acceptance Classification.
IPC가 포함된 조건부 DistilBERT 분류기를 이용하면 전체 데이터에서 62%의 정확도를 보여준다. 만약 subclass별로 제한하여 보면 G06F엔 64.5% H04N에는 61.9%, G06Q에는 57%의 성능을 보여준다.
Cross-Category Evaluation.
다양한 IPC 클래스의 다양한 특허 등록 여부 기준 간의 관계를 이해하고 식별하기 위해 우리는 특허의 하나의 IPC subclass에 대해 훈련된 각 DistilBERT 모델을 가져와 다른 모든 인기 있는 IPC subclass에 걸쳐 평가했다. Figure 3은 경험적 발견을 보여준다. G06F와 H04L처럼 개념적으로 유사한 특허 기술 분야는 유사한 등록 기준은 갖는다. 특히 한 상황에서 다른 상황으로 일반화되지 않는데 이는 특허 승인 기준이 특정 범주에 대한 기술적 요구에 민감하다.
.Figure 3: Cross-category evaluation of BERT acceptance prediction classifiers trained on one IPC code evaluated to predict acceptance on other IPC codes. Patent categories that are conceptually similar appear to have closer shared criteria for acceptance (for example, A61B and G01N). Most models also tend to perform well when evaluated on patent applications in H04L-Transmission ofDigital Information; moreover, the model trained on H04L-Transmission ofDigital Information has high predictive power across other application types. This might reflect acceptance criteria in this category involving more high-level evaluations of quality, as opposed to more domain-specific innovations in engineering or manufacturing.
Performance Over Time.
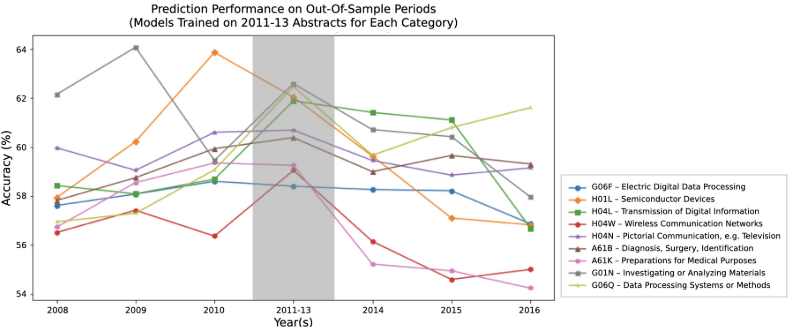
Figure. 4는 2011년부터 2013년까지의 특허 출원에 대해 훈련된 등록 분류 모델의 성능을 보여주며, 이전과 이후에 생성된 청구서에 대해 평가되었다. 모델의 성능은 시간에 따라 악화하며 이는 예측에 사용되는 feature의 변화를 암시하며 빠르게 변화하는 분야에 관해 그 정도는 더 심하다.
Cross-Category Evaluation. InFigure 4: Performance of a BERT decision classifier trained on applications from 2011 to 2013 and evaluated on applications produced in earlier and later years. While model performance decays over time across most categories (suggesting changing acceptance standards), acceptance criteria appear to change more quickly in faster-moving fields (e.g., H01L-Semiconductor Devices and H04W-Wireless Communication) and slower in more developed fields (e.g., A61B-Diagnosis, Surgery, Identification). In future work, it may also be illustrative to use this dataset to investigate the impact of the U.S. Supreme Court decision in Alice Corp. v. CLS Bank International, 573 U.S. 208 (2014), on the software-related patent applications issued after 2014.
Additional Tasks.
추가적인 Tasks를 통해 다양한 연구가 가능하다.(Section H 참고)
Long Sequence Modeling
Patent Clustering
Patent Examiner Assignment
Potential Social Impact and Applications & Future Work
8 Conclusion
HUPD에는 2004년부터 2018년 사이에 USPTO에 제출된 450만 개의 영어 특허 출원이 포함되어 있다. 또한 데이터셋에서 두 가지 분류 기반 작업과 두 세대 기반 작업에 대한 벤치마크를 설정했다