
Abstract
- 지적 재산 관리의 핵심 업무 중 하나인 Patent Landscaping에는 사용자 정의 기술 또는 응용 프로그램 중심 기준에 따라 특허를 선택하고 그룹화하는 작업이 포함
- Transformer 기반의 특허 코드 분류(IPC, CPC)는 연구와 달리 Patent Landscape Studies(PLS)의 연구는 아직 부족
- 두 가지 도메인의 PLS向 작업을 위한 세 가지 레이블이 지정된 데이터 세트를 공유
- 특허 전무의 텍스트 정보 뿐만 아니라 CPC label을 이용하여 임베딩을 생헝한 새로운 모델 제안
- 제목과 초록이 중요하며 CPC 라벨도 효과적인 정보
1 Introduction
새로운 시장에 진입하거나 신제품을 개발할 때 기업과 같은 조직은 Patent Landscape, 즉 비즈니스 활동과 관련된 기존 특허를 인식하여 운영의 자유를 보장하는 것이 가장 중요하다. 전략적 결정을 지원하기 위한 목적으로 관련 지적 재산의 개요를 얻는 작업을 Patent Landscape Studies(PLS) 수행이라고 한다. PLS는 검색, 분류, 분석의 세 단계로 구성되며 이 연구는 두 번째인 분류에 집중한다. 특허 분류에 대한 대부분의 이전 연구들은 IPC와 CPC에 집중되어 왔으며 이 계층적 multi-label 분류는 많은 양의 CPC 코드 수로 인해 어렵지만 각 특허마다 할당되기 때문에 많은 양의 데이터가 존재한다.
그러나 PLS는 제한된 범위에서만 CPC 범주에 해당할 수 있는 일련의 응용 프로그램 또는 비즈니스 중심 기준에 따라 문서를 분류하려는 목적으로 일련의 특허 출원 또는 부여된 특허에 대해 수행한다. 이 PLS 지향 작업을 대상 분류 작업이라고 부른다 (Figure 1 참고). 문서에 이미 CPC 라벨이 지정되어 있으므로 이러한 라벨을 하나의 정보로 활용할 수 있다.
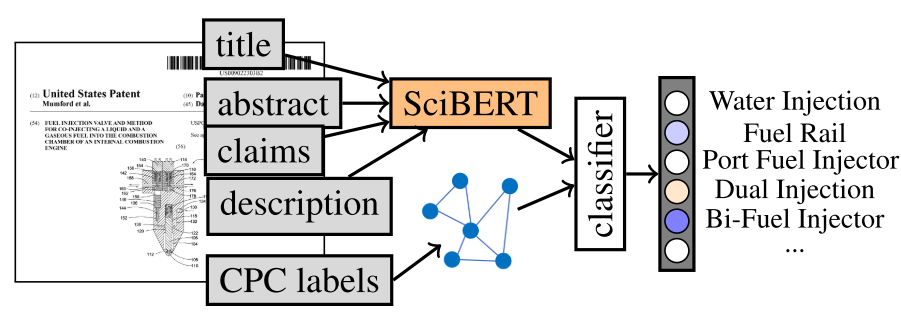
이 작업의 첫 번째 중요한 기여는 두 가지 메인에서 세 가지 실제 PLS向 데이터 세트 공개한 것이다. 하나는 20년 기간의 injection valves에 관한 특허를 해당 산업 관련 도메인 전문가들이 라벨링 하였다. 또한 HIV 약물에 대한 PLS 중에 생성된 WIPO의 두 개의 소규모 문서 컬렉션을 제공하고 이에 대한 벤치마크 작업을 정의한다.
두 번째 기여는 CPC 분류에 효과적인 것으로 최근에 제안된 신경 및 비신경 모델을 비교한 계산 연구이다. 콘텐츠 기반 feature 벡터와 레이블 기반 feature 벡터의 조합을 실험한다. 우리는 특허 제목, 초록, 청구항 및 설명에 대한 SciBERT 기반(Beltagy et al., 2019) 임베딩을 생성한다. CPC 라벨의 의미를 표현하기 위해 label co-occurrence graph와 label description text 기반으로 임베딩을 생성하는 다양한 접근 방식을 비교한다. 우리는 모든 텍스트와 CPC 임베딩을 사용하면 세 가지 PLS 데이터 세트에서 일관되게 잘 작동하여 모든 기준을 능가하는 강력한 방법이 생성된다는 것을 발견했다.
요약하면 다음과 같다.
- 세 가지 데이터에 대해 PLS向 분류 작업을 정의
- 목표 작업 뿐 아니라 데이터의 성질을 분석
- 세 데이터에 대한 Robust 아키텍쳐를 제안
2 Related Work
Patent Dataset.
- CPC 분류 (Pujari et al., 2021, 2022; Li et al., 2018)
- 사람이 작성한 특허 요약 (Sharma et al. (2019))
- 청구항에 대한 선행기술을 mapping (Risch et al. (2020))
Patent Classification.
- 전체 문서 텍스트를 활용하는 TF-IDF feature 벡터(Fall et al., 2003; Guyot et al., 2010; Wu et al., 2010; Verberne and D'hondt, 2011)
- CNN(Li et al., 2018; Niu and Cai, 2019)
- RNN(GRU(Risch and Krestel, 2019), LSTM(Grawe et al., 2017))
- Pre-trained transformer 기반 (Lee and Hsiang, 2020; Pujari et al., 2021; Althammer et al., 2021)
- Bigbird (Zaheer et al. (2020))
Automating Patent Landscaping.
- Citation graph 탐색, CPC one-hot 임베딩, word2vec 및 LSTM 사용하여 PLS 분류 (Abood and Feltenberger (2018))
- 초록과 청구항에 대한 LSTM 출력을 연결하여 분류기로 분류 (Giczy et al. (2022))
- Transformer 이용 초록과 graph 신경망의 diff2vec을 이용하여 CPC labels를 임베딩 (Choi et al. (2022))
Embedding Metadata for Patent Classification.
- 분류(Richter and MacFarlane, 2005; Benites et al., 2018) 및 군집화(Vlase et al., 2012) 목적의 IPC, inventor, 그리고 assignee information을 반영하는 비 신경 개수 기반과 TF-IDF 기반의 feature 벡터 사용
- 문서 텍스트와 CPC 라벨 간 BM25 유사도비교 (Niu and Cai (2019))
- Word co-occurrence, inventor, 그리고 assignee information 정보의 그래프 임베딩을 어텐션 기반의 합으로 조합(Fang et al. (2021))
해당 연구에서는 inventor와 assignee information은 biases를 유발할 수 있으므로 제외되었다.
3 Patent Landscaping: Task and Datasets
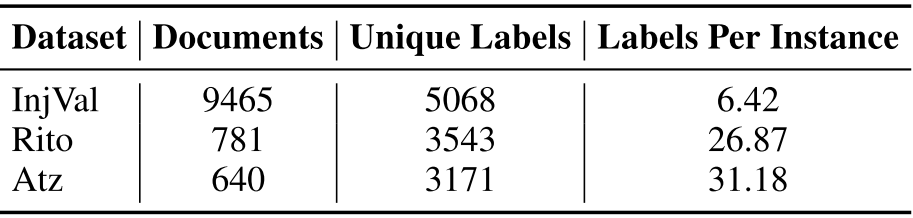
이 섹션에서는 PLS를 도와줄 수 있는 분류 작업을 제안하고 두 도메인(mechanical systems and biochemistry)에서 세 가지의 새로운 데이터를 제안한다. 모든 데이터는 오픈되어 있으며 관련 통계는 Table. 1에 라벨 분포는 Figure. 2에 기술한다.

3.1 Target Classification Task
주어진 학습 데이터 $ \{\left< d^{(i)}, C^{(i)}_d, L^{(i)}_d \right>\}^n_{i=1} $ 에 대해 분류 작업은 문서 $d^{(i)}$와 CPC 라벨의 집합 $C^{(i)}_d$을 목표 라벨 집합인 $ L^{(i)}_d $로 매핑하는 함수를 생성하는 것이다. 특허 문서 $d$는 제목 $t$, 초록 $a$, 청구항 $cl$, 그리고 설명 $desc$과 같은 텍스트 필드로 구성된다. CPC (*CPC라고 적었고 이후로도 그렇게 기술하지만 IPC도 사용) 는 사전 정의된 값을 사용한다. 목표 라벨은 사용자 정의된 값을 사용한다.
3.2 Injection Valves Dataset
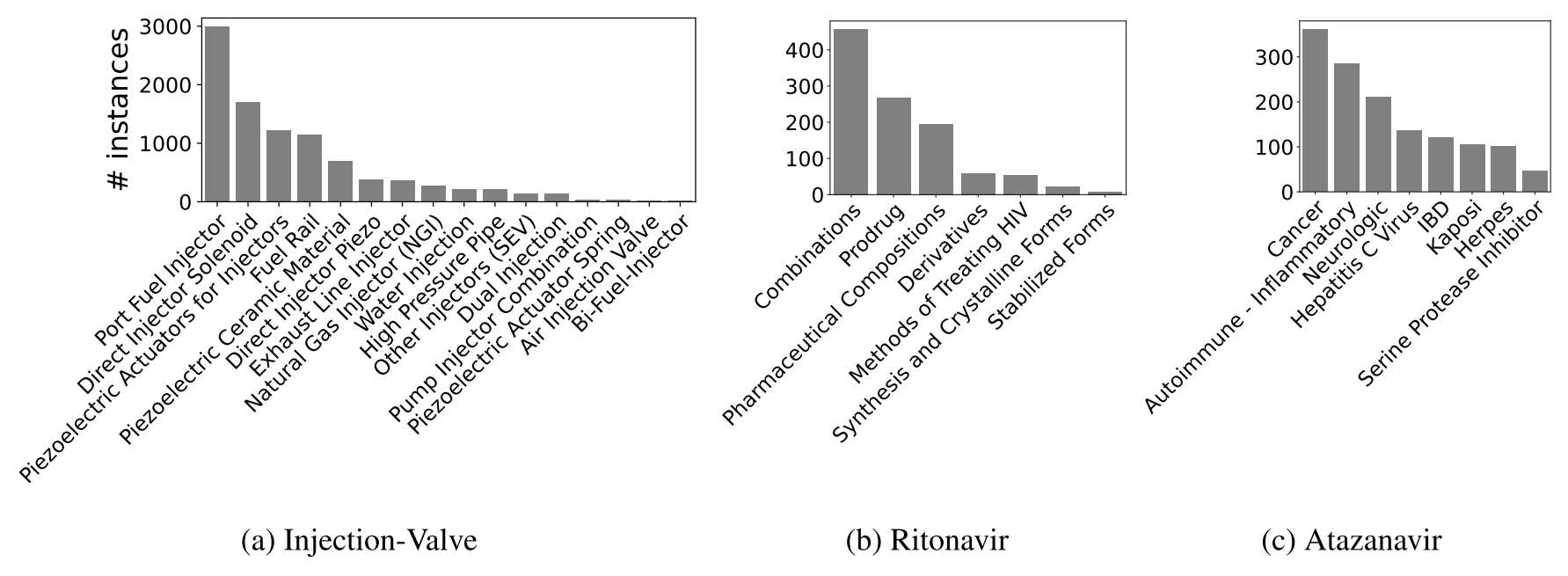
InjVal 데이터 특허군에는 분사 밸브 유형과 관련 기술을 설명하는 카테고리가 표시되어 있다. 해당 데이터는 전문가들이 분류하였으며, 매주 후보 특허들이 CPC 기반의 검색으로 생성된다. 총 9,465개의 특허에 16개의 다른 라벨이 되어있으며, 특허 수는 가장 많은 일본, 독일, 미국 특허순으로 많이 존재한다. 그래서 각 필드당 기계 번역된 영어 텍스트를 추가한다.
데이터는 5,068개 CPC의 넓은 범위를 포함한다. 특허당 평균 라벨 수는 1에 가깝기 때문에 single-label classification으로 볼 수 있다.
3.3 Ritonavir and Atazanavir Datasets
우리는 HIV 감염 및 AIDS 치료를 위해 개발된 두 가지 약물인 Ritonavir(Rito) 및 Atazanavir(Atz)에 대해 World Intellectual Property Organization(WIPO)에서 공개적으로 사용 가능한 두 개의 PLS에서 두 개의 레이블이 지정된 데이터를 파생한다.
Patent Landscape Report on Ritonavir (wipo.int)
Patent Landscape Report on Ritonavir
This report is dedicated to Ritonavir – an antiretroviral drug used to treat HIV infection and AIDS. A major goal of the report is to highlight the technology timeline for Ritonavir from the first filing of this compound to the present filings. It identi
www.wipo.int
https://www.wipo.int/publications/en/details.jsp?id=265
Patent Landscape Report on Atazanavir
This patent landscape report is dedicated to Atazanavir – an antiretroviral drug used to treat HIV infection and AIDS. A major objective of this report is to examine the evolution of the patent environment protecting Atazanavir from the first filing of t
www.wipo.int
InjVal과 달리 두 데이터는 좁은 범위의 단일 발명에 집중한다.
위 데이터는 WIPO의 프로젝트였으며, 해당 작업은 반복적으로 이루어졌다. 우선 키워드 기반 검색 후 관련 문서를 CPC 기반으로 필터링한다. 정방향-역방향 인용 검색을 통해 추가 확인된 특허 데이터를 추가한다. 각 연구는 검색 및 특허에 대한 메타정보를 제공한다. 라벨은 검색(Rito)하는 동안 전문가가 혹은 text mining software의 지원(Atz)으로 할당되었다. InjVal과 Rito와 달리 Atz의 라벨은 silver standard로 고려되어야 한다. 보고서의 설명을 토대로 이런 라벨들로부터 하위집합을 선택하여 PLS 타겟 라벨로 선정했다.
Atz 데이터는 WIPO로부터 Derwent의 제목, 초록 그리고 대표 청구항이 제공된다. Rito는 제목, 초록 그리고 청구항의 목록이다. 저자의 기여는 PatBase로부터 구조화된 전체 텍스트를 데이터에 추가했다. 사용하기 쉬운 형식으로 제목, 초록, 모든 청구항, 설명, CPC 라벨, 특허 번호, family 번호 및 발행일을 제공한다.
Rito데이터는 781개의 특허 families로 구성되며 7개의 구분된 라벨을 갖고 있다. 카테고리는 다음과 같다
- Methods of Treating HIV
- Combination
- Prodrug
- Pharmaceutical Composition
- Derivatives
- Synthesis and Crystalline Forms
- Stabilized Forms
Atz데이터 는 640개의 특허 families로 구성되며 8개의 구분된 라벨을 갖고 있다. Atazanavir의 주요 적용은 HIV이지만, 의료 전문가들은 다른 적용도 시행했으며, HIV가 아닌 적용을 설명하는 특허의 하위 집합을 선택하여 해당(HIV가 아닌) 질병을 식별하는 것으로 목표 작업을 정의했다. 표적 라벨 중에서 암, 염증순으로 빈번하다.
Rito는 특허를 기술별로 나누고 Atz는 특허를 응용별로 나눈다. Table. 1에서 인스턴스당 평균 레이블은 1보다 크기에 Rito와 Atz는 multi-label classification 작업을 구성한다.
3.4 Dataset Analysis and Corpus Statistics
Token Counts / Text Lengths.
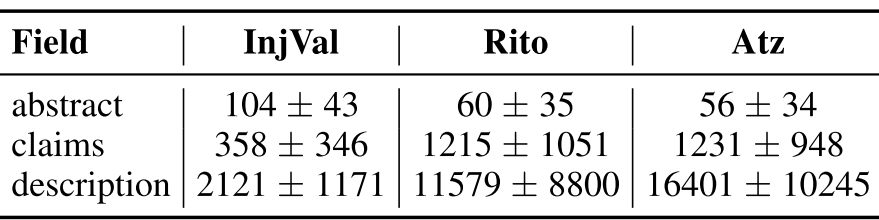
Table. 2 에서 NLTK 공백 tokenizer를 이용하여 평균 토근 수를 보고한다. InjVal은 상대적으로 초록이 많은 토큰을 가지고 있으며, Rito와 Atz는 청구항과 설명이 많은 토큰을 가지고 있으며 분산도 크다.
Publication Date.
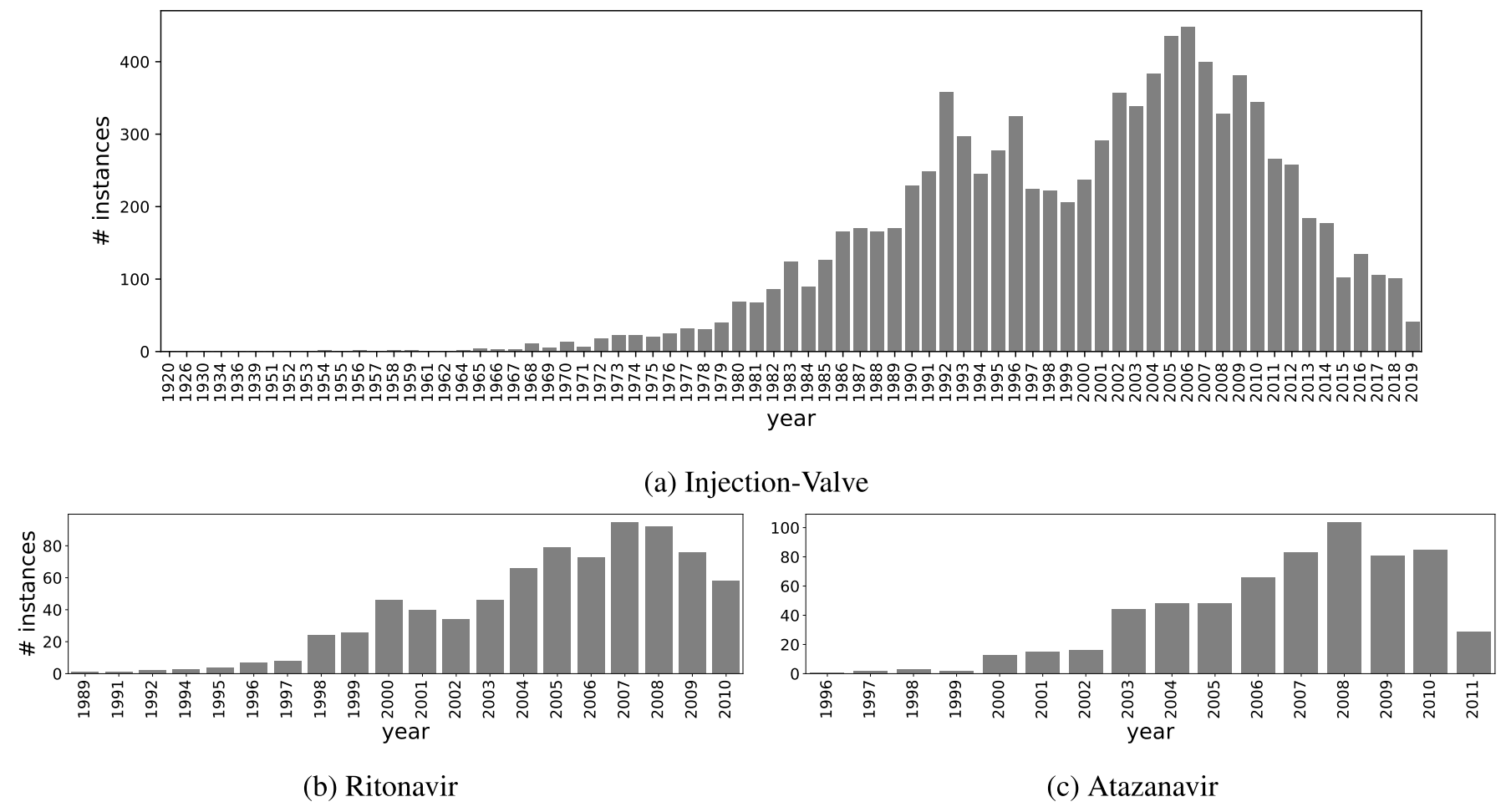
등록 날짜는 각 family특허 중 가장빠른 날을 선택했다. InjVal은 긴 기간의 특허들을 포함하지만 Rito와 Atz는 22, 16년 기간의 특허 정보만 있다.
Patent Office / Original Language.
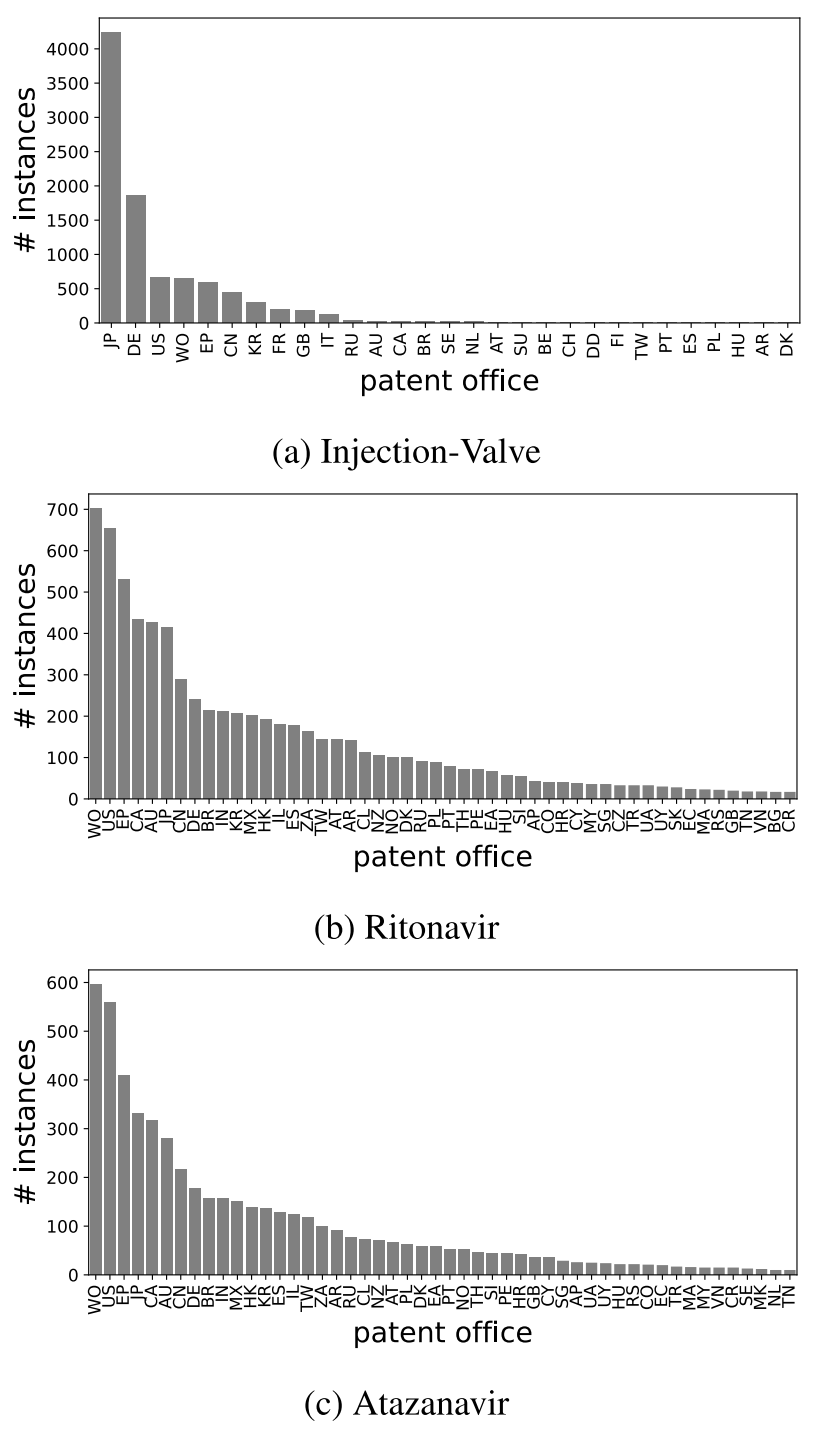
Rito와 Atz의 경우 대부분 USPTO거나 WIPO를 통해 전세계에 출원되었다. (Figure. 6) 따라서 대부분 영어로 작성되어 있다. 그러나 InjVal의 경우 68%가 기계 번역된 텍스트로 구성되어 있다.
Duplicate Abstracts.
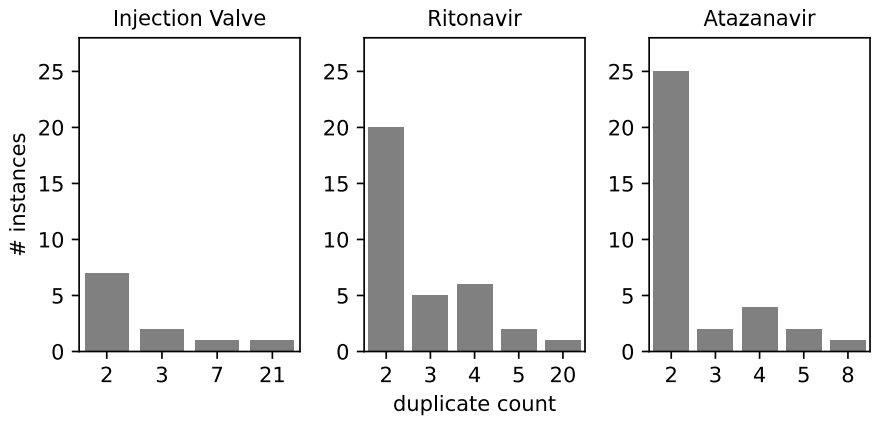
특허 초록은 법적 구속력이 없기 때문에 기업에서는 동일한 초록을 재사용하는 경우가 많으며 때로는 의식적으로 정보를 숨기기도 한다. InjVal, Rito와 Atz 는 각각 48, 90, 109 개의 중복이 존재한다. 몇몇 경우 InjVal과 Rito에서 20번 반복되는 경우도 있다.
CPC Labels.
Rito와 Atz가 InjVal 보다 많은 수의 코드를 받았다. 50개보다 많은 CPC를 받은 특허의 수는 InjVal의 단지 하나 뿐인 반면에 Rito와 Atz는 13, 18개이다. WIPO 데이터의 경우 상대적으로 많은 CPC를 보유하는데, 이 CPC를 feature로 사용하는 것의 효과는 CPC와 타겟 라벨이 얼마나 상응하는가에 의존한다. 따라서 CPC와 타겟 라벨간 Pointwise Mutual Information(PMI, 동시 발생 확률/각각 발생 확률)을 비교했다.
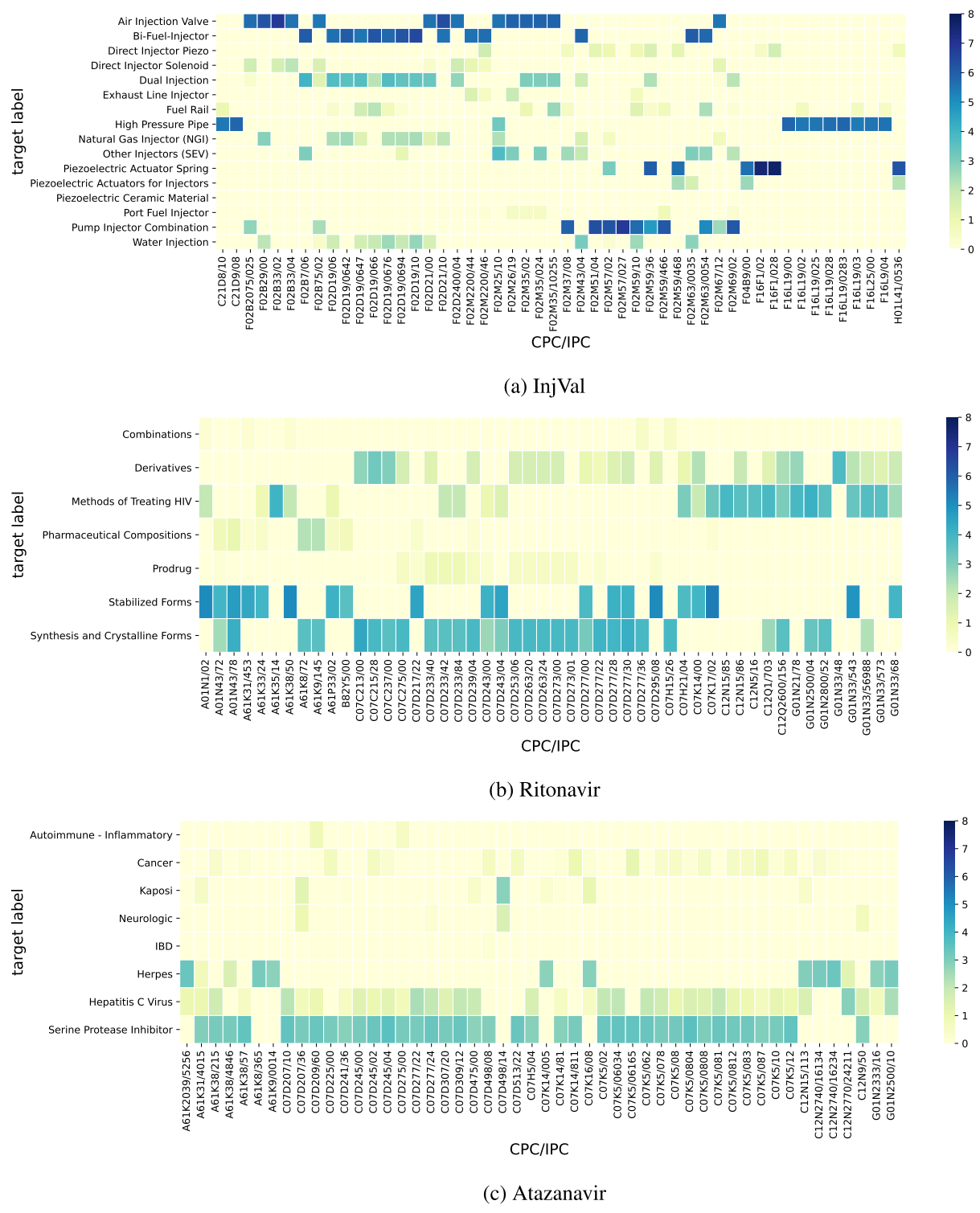
Figure. 8 에서처럼 top-50 CPC/IPC의 경우 타겟 라벨과 상응한다.
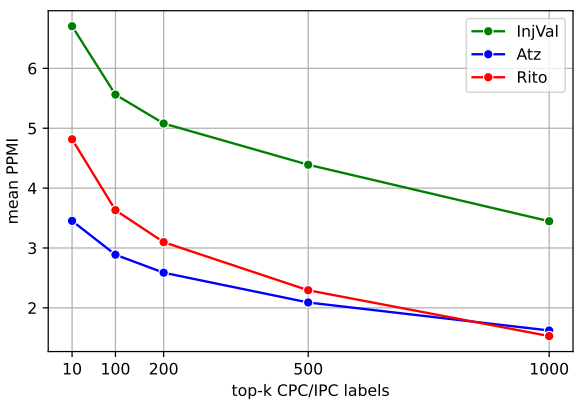
Figure. 9 에서는 top k의 값을 변경하면서 PMI점수가 어떻게 변하는지 확인하였다. 위 그래프를 통해 InjVal, Rito, Atz 순으로 상응 수준이 높으며 feature 사용의 효율이 좋을 것이라 예측 가능하다.
4 Computational Models
텍스트와 CPC 라벨을 기반으로 특허의 대상 카테고리를 예측하기 위한 계산 모델을 설명한다.
4.1 Neural Patent Text Representations
BERT 스타일의 인코더로 과학 텍스트에 대해 사전 학습된 SciBERT는 CPC 분류에서 BERT 성능을 상회하였으며 이 논문에서는 sequence를 word-piece tokens으로 나눈 후 510 길이 까지 truncate하여 SciBERT에 입력한다. 마지막 은닉 상태의 출력 [CLS] 토큰을 텍스트 임베딩 $e(.)$으로 사용한다. 모델은 CPC 분류 작업으로 미세 조정되며, 해당 미세 조정된 SciBERT를 이용해서 텍스트 임베딩을 계산한다. 임베딩은 제목+초록 $e(t+a)$, 청구항 $e(cl)$, 설명 $e(desc)$ 세 가지를 사용하였으며, 같이 사용할 경우 벡터합 ($\bigoplus $)를 사용했다.
4.2 CPC Label Embeddings
CPC 라벨의 featurize 네 가지 방법을 실험한다.
- 각 차원이 하나의 CPC 라벨의 존재를 나타내는 Multi-hot encoding vector($cpc_{multihot}$)
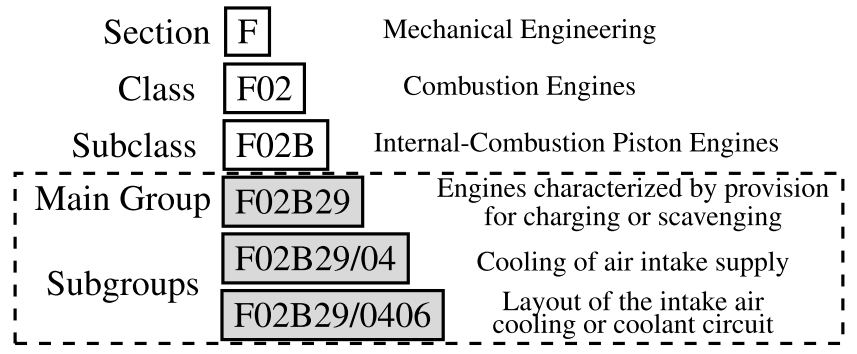
- 각 CPC 는 Figrue. 3처럼 계층마다 코드에 해당하는 설명이 있다. F02B29/0406의 경우 Main group의 설명부터 연결하여 SciBERT에 입력후 임베딩 값을 얻을 수 있다. 문서 수준의 임베딩 $cpc_{text}$는 특허에 할당된 모든 CPC 클래스의 CPC 라벨 임베딩에 대한 평균이다.
- 레이블 설명에는 중요한 도메인별 키워드가 포함되어 있으므로 CPC 분류 체계 내의 모든 레이블 설명에 대해 계산된 TF-IDF 모델을 사용하여 문서에 할당된 CPC 레이블의 연결된 레이블 설명 텍스트에 대해 140k 차원 TF-IDF feature 벡터 $cpc_{tf.idf}$를 계산한다.
- CPC 라벨을 node로 가정하면 동일 문서에서 동시 등장하는 라벨을 연결할 수 있다. Edge의 가중치는 동시 등장하는 횟수에 비례한다. 이후 생성된 Stellar-Graph는 node2vec 알고리즘으로 임베딩을 생성한다. 문서 수준의 임베딩 ($cpc_{graph}$)은 각 임베딩의 평균값이다.
4.3 Classification Model
분류 모델은 Transformer-based Multi-task Model(TMM, Pujari et al., 2021)와 유사하다. 모델의 입력인 CPC 라벨과 특허 텍스트기반의 임베딩은 개별로 사용되거나 연결되어 사용된다. TMM 모델은 각 라벨에 대해 하나의 분류 헤드를 사용한다. 각 분류 헤드는 3개의 dense layer로 구선된다. 마지막 분류층은 이진 softmax 출력으로 각 라벨에 해당하는지 여부를 예측한다.
5 Experiments
이 섹션에서는 PLS 전반에 걸쳐 강력하게 작동하는 특허 문서 표현을 식별하는 것을 목표로 한다.
C Hyperparameters and Implementation
Hyperparameter를 찾기위해서 grid search를 수행했으며 Nvidia Tesla V100 GPU with 40GB VRAM을 사용했다.
Node2Vec.
Global CPC co-occurrence graph (240k nodes and 40M edges)의 큰 크기 때문에 a subgraph comprised of CPC labels from the three datasets with 9.5k nodes and 500k edges를 사용한다. Node2vec 알고리즘을 통해 128차원의 라벨 임베딩을 생성한다. p와 q 변수는 다음 hop을 선택할 때 인접 혹은 비인접한 노드 선택을 결정한다. 동등한 조건을 주기 위해 p와 q모두 1로 설정했다. 연산 효율을 위해 10 random walks와 50 maximun length를 설정했다.
TMM.
hidden layer size of 50 for all dense layers in the classification heads, dropout set to 0.25 across layers, and a batch size of 4. 최대 50 epochs 학습, early stopping은 7 epochs 동안 macro-F1 향상이 없을 시. learning rate of 1e-05, 3e-05, and 5e-05 for InjVal, Rito, and Atz,
5.1 Baselines
TMM with $e(t + a)$.
SciBERT에 제목과 초록을 입력하는 방식
SVM.
TF-IDF 벡터를 이용하는 방식으로 ALTA2018 multi-label IPC 분류에서 TF-IDF 벡터를 SVM에 적용하여 좋은 성적을 거두었다. 140k 차원의 feature 벡터를 전체 문서(제목 + 초록 + 청구항 + 설명)에 대해 70k character n-gram(3- to 6-)와 70k word n-gram(1- to 2-)로 생성한다.
5.2 Dataset Splits
전체 데이터의 15%는 test set으로 분리하고 남은 85%의 데이터로 5-fold cross-validation(CV)을 수행한다. 각 CV fold에 대해 세 개의 fold를 훈련용으로 사용하고, 하나는 튜닝용으로, 하나는 개발용으로 사용한다. 5개의 모델은 test set으로 평가되며 평균과 표준편차 값을 보고한다.
5.3 Comparison of Patent Embeddings
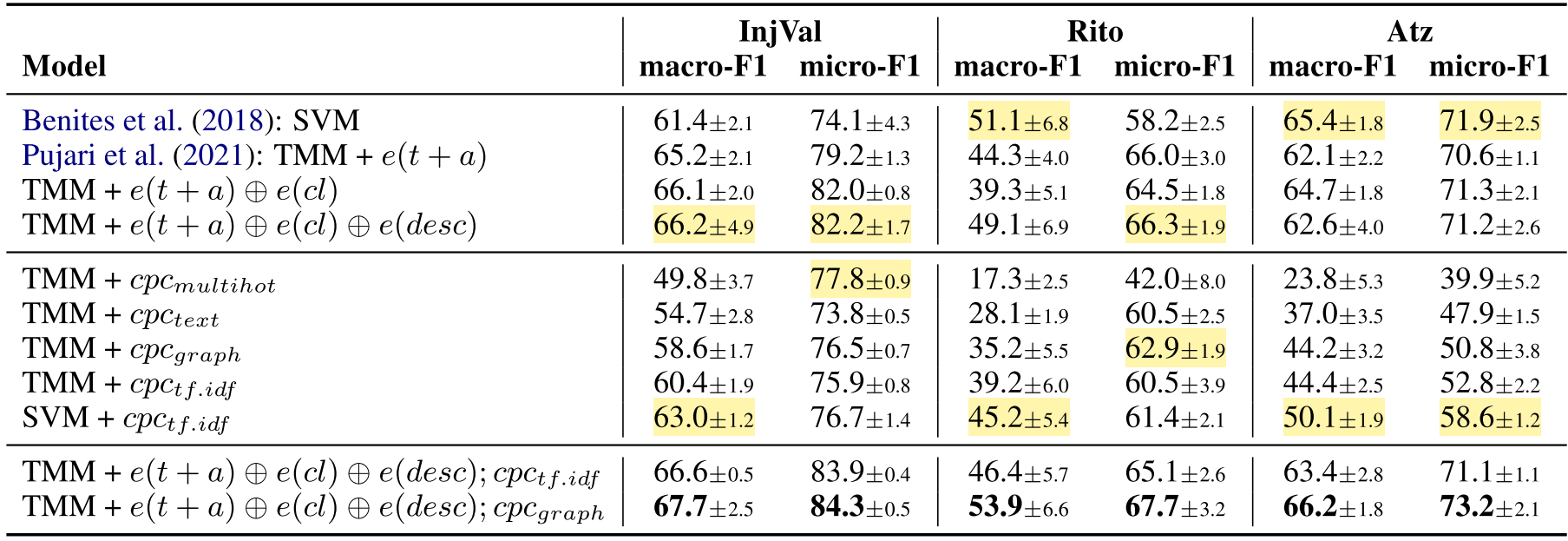
$cpc_{tf.idf}$가 성능이 제일 좋았다가 TMM과 결합 시 성능저하 발생은 140k의 차원을 768 차원으로 전사 시키는 과정이 원인으로 보인다.
즉, TMM + 모든 text 정보 + graph가 가장 성능이 좋다.
5.4 Comparison with the Baselines

Dataset과 상관없이 제안된 방식이 F1에서 가장 높은 성능을 보여주고 robust하다고 볼 수 있다.
5.5 Minimum Training Instances
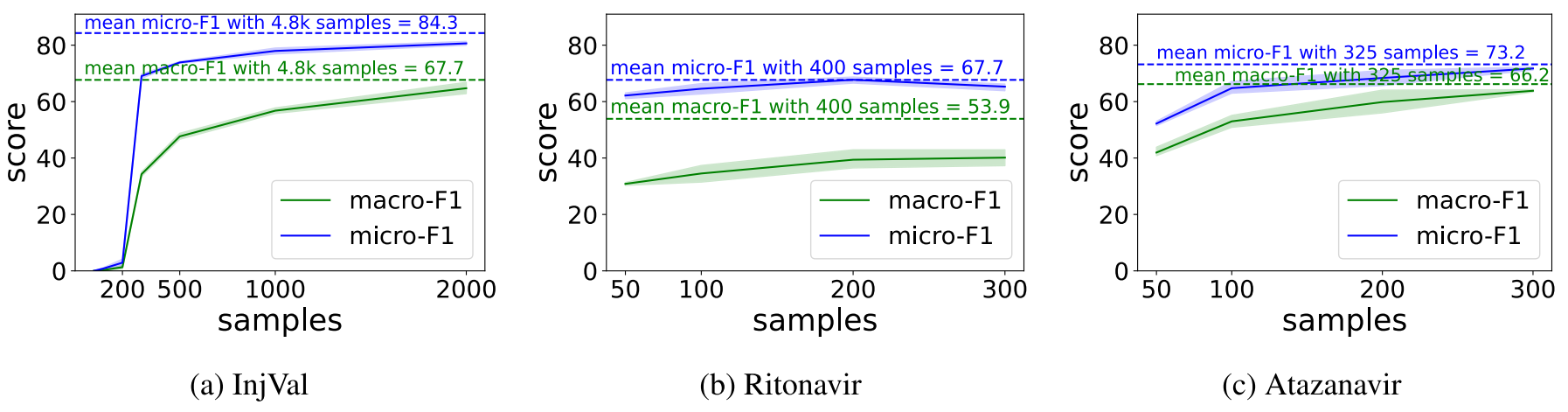
데이터 세트 전반에 걸쳐 200~300개만 학습하면 전체 성능 대비 유의미한 결과를 얻을 수 있다. 그러나 macro-F1이 낮은 것으로보다 적은 빈도수의 라벨 예측 성능은 저조하다.
6 Conclusions and Future Work
PLS 자동화 분야의 연구를 위해 타겟 레이블 분류라는 새로운 작업을 도입하고 3개의 실제 데이터 세트를 발표했다. 특허 텍스트와 CPC 레이블 정보를 모두 활용하고 세 가지 데이터 세트 모두에서 강력한 성능을 보여주는 경쟁력 있는 신경 특허 분류 모델을 제안한다. 마이크로 F1 측면에서 수용 가능한 성능은 200~300개의 훈련 인스턴스만으로 달성될 수 있음을 발견하여 접근 방식의 실용적 적용 가능성을 입증했다.



