
PatentSemTech 2022
- Foreword
- Information Extraction
- End-to-End Chemical Reaction Extraction from Patents
Yuan Li, Biaoyan Fang, Jiayuan He, Hiyori Yoshikawa, Saber A Akhondi, Christian Druckenbrodt, Camilo Thorne, Zenan Zhai and Karin Verspoor - Optimizing BERT-based reference mining from patents
Zahra Abbasiantaeb, Suzan Verberne and Jian Wang
- End-to-End Chemical Reaction Extraction from Patents
- Classification
- An Ensemble Architecture of Classifiers for Patent Classification
Eleni Kamateri and Michail Salampasis - Patent Classification using Extreme Multi-label Learning: A Case Study of French Patents
You Zuo, Houda Mouzoun, Samir Ghamri Doudane, Kim Gerdes and Benoît Sagot
- An Ensemble Architecture of Classifiers for Patent Classification
- Search
- Query Terms Suggestion
Matthias Wirth and Alexander Klenner-Bajaja - A Combination of BERT and BM25 for Patent Search
Vasileios Stamatis, Michail Salampasis, Konstantinos Diamantaras and Allan Hanbury - Patent Search Using Triplet Networks Based Fine-Tuned SciBERT
Utku Umur Acikalin and Mucahid Kutlu - Graph-based patent search
Juho Kallio and Sebastian Björkqvist
- Query Terms Suggestion
- Datasets
- Patents Phrase to Phrase Semantic Matching Dataset
Grigor Aslanyan and Ian Wetherbee - Recent Developments in AI and USPTO Open Data
Scott Beliveau and Jerry Ma
- Patents Phrase to Phrase Semantic Matching Dataset
Foreword
PatentSemTech는 SIGIR과 연결되어있는 workshop으로 Patent Retrieval과 Patent Analytics에 Natural Language Processing, Text와 Data Mining 및 Semantic Technologies를 적용하는 것에 초점이 맞춰져 있다. 특허 데이터는 문맥이 복잡하고 길이가 길며 다양한 분야를 포함하는 만큼 서로 이질적인 특징의 과학적 텍스트를 가지고 있다. 해당 특징들로 인해 일반적인 텍스트 대비 분석에 어려움이 있다.
Abstract
- 기존 모델들은 chemical entity와 reaction event를 뽑을 수 있지만 한계가 명확 (길이가 긴 문서 처리 불가능, 화학 반응식 인식 불가)
- reaction detection - chemical named entity recognition - event extraction - anaphora resolution - reaction reference resolution - table classification 으로 구성된 chemical reaction extraction pipeline을 제안
System Overview
- Reaction snippet detection
- 특허는 문단들로 구성되어 있으며 화학 반응이 포함된 문단을 찾는 문제로 paragraph-level sequence tagging problem으로 구성
- Chemical NER
- 위에서 추출된 snippet에 대해 chemical entity를 구분하고 그들의 role을 지정
- Event extraction
- 화학 반응은 event steps의 순서로 구성 (반응물이 생성물로 변환 혹은 정제)
- event는 trigger word와 trigger word와 관련된 chemical entity를 연결
- Anaphora resolution
- event steps 간 혹은 내에서 진행
- coreference (두 mention이 같은 entity)와 bridging이 화학물과 그 source를 연결하는지 여부
- (a) anaphora mention detection (b) relation classificatino으로 task 구성
- Reaction reference resolution
- 화학 특허는 공통된 substructure를 갖는 유사한 물질이 동일한 방식으로 합성될 수 있다는 상세 내용을 포함
- 우선 참조할 다른 snippet이 있는지 판단 후 가능한 snippet 쌍을 생성 후 분류
- Table classification
- 표들은 반응 물성으로 분류
- 반응을 기술할 정도로 정보가 충분하다면 표로부터 반응을 추가로 추출
Introduction
비구조화된 특허의 글에서 참고문헌을 추출하는 작업은 중요하다. 해당 작업은 두 단계로 이루어 진다. (1) reference extraction (2) reference matching. 단계 (1)에서 참고 문헌들을 특허로부터 추출하고 단계 (2)에서 과학 문헌의 데이터 베이스에서 일치 여부를 확인한다. 단계 (2)에서 성공적일 일치여부를 확인하려면 단계 (1)에서의 recall이 precision보다 중요하다.
contributions
- Multiple pretrained BERT-based models
- Effective method for sequence splitting
- The impact of down sampling on model to cope with the class imbalance
- Annotating a larger dataset
Our Reference Extraction Method
- Pre-trained language models에 classification layer (BIO tagging, e.g. 'I' is inside of a reference)
- BERT-base
- SciBERT
- PatentBERT
: BERT-base 모델을 USPTO의 claim을 특허 분류 task에 finetuning - BERT for patents
: BERT-large 모델을 description와 abstract 및 claims 에 대해 post training 진행 - BioBERT
- Sequence splitting
- BERT에 맞춰 512를 max sequence length로 선택했으며, 512가 넘지 않는 선에서 sequence를 최대한 밀어 넣었다.
- Downsampling
- 특허의 대부분의 텍스트에서 참고문헌이 언급되지 않기 때문에 상당수의 sequence는 참고문헌이 없다. 따라서 train set에서 그러한 참고문헌이 없는 sequence를 삭제하여 down sampling하였다.
- Data
- Google Patents 에서 22개의 annotation 된 dataset을 사용
- 모든 특허는 2010년에 출원되어 "C12N" IPC class를 가짐
- 전체 데이터중 2318개의 "B" 태그 (2318개 참고문헌) 32,359 "I" 태그 보유
- 22개의 특허 14,270 sequence중 segmentatino 되어서 8,530 개가 "B" 또는 "I" 라벨을 보유
Experiments and Results
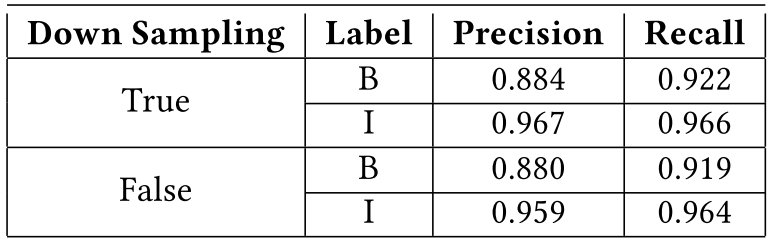
- Down sampling 효과
- 성능이 Table 1. 과 같이 향상되었으며, 학습이 수월하게 되었다.
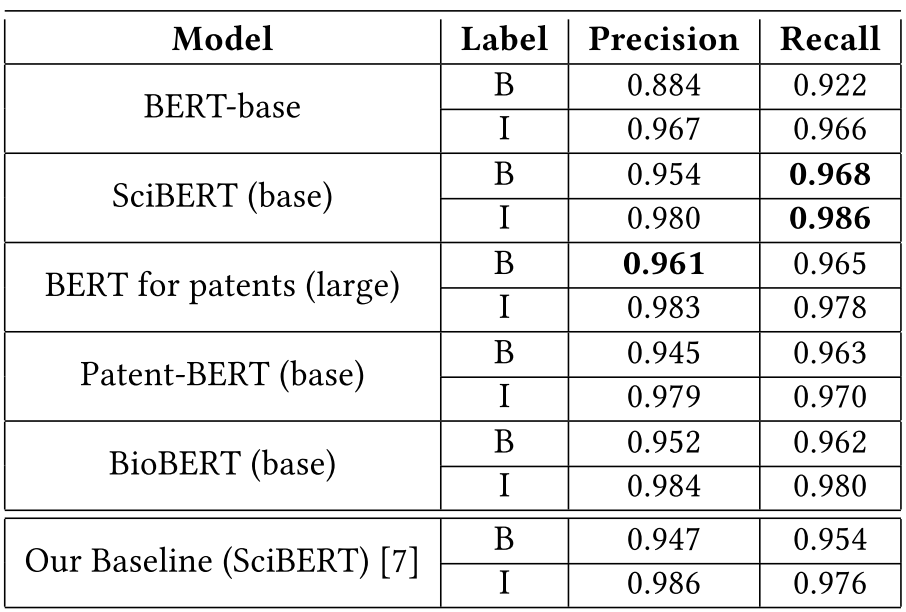
- BERT와의 비교
- SciBERT가 recall이 높고 BERT for patentes 가 precision이 높다
- SciBERT가 성능이 높은 이유는 sequence tagging task로 fine-tune 되었기 때문
- Patent-BERT는 다른 모델에 비해 성능이 낮은데 그 이유는 claims로 fine-tune이 되었고 claims는 참고문헌을 가지지 않기 때문

Introduction
20년 동안 특허 분류 자동화는 대규모 특허를 다루는데 있어 중요해졌다. 일반적인 분류 기준은 IPC (International Patent Classification) 와 CPC (Cooperative Patent Classification)를 사용하며 각각은 section - classes - subclasses - groups - subgroups로 계층적 구조를 갖는다. 과거 방법은 일반적인 텍스트 분류모델을 사용하였다. 몇몇은 XML(eXtreme Multi-label Learning)을 이용하여 많은 수의 class를 다룰려고 했지만 IPC의 subclass 수준에만 집중하였다. 해당 논문에서는 INPI-CLS라는 프랑스 특허 말뭉치를 이용한다.
2002년부터 2021년까지 출원된 특허의 모든 부분 (Title, abstract, description, claims)를 포함한 INPI 데이터셋에서 추출되었다. Train 데이터는 2020년 전 Test는 2020년 이후 데이터로 구성된다.


- N: 특허의 수
- L: IPC label의 수
- ˉL: IPC label의 평균 수
- ˆL: Label당 문서의 평균 수
- 4, 6, 8은 IPC의 subclass, group, subgroup level을 의미
XML(eXtreme Multi-label Learning) 방법을 다른 유명한 NLP 방법과 성능 비교를 수행하였다. 이 때 평가 대상은 INPI-CLS 와 USPTO-2M 특허 분류 benchmark를 사용하였다 (train/test : 1.9M/48k).
Experiments and Results
- Logistic Regression
- 이진 분류기를 각 label에 대해 학습. TF-IDF를 입력 feature로 사용
- 입력 텍스트의 처음 1000단어들에 대해 stop words를 제거하고 NLTK의 snowball stemmer를 적용
- FastText text classification
- 얕은 신경망에 FastText n-gram 글자 임베딩(text 분류로 학습된)을 이용
- Token representation을 Wikipedia에 사전 학습된 embedding matrix로 초기화
- 선형 분류기를 multi-label text 분류로 학습
- BERT
- BERT를 특허 분류로 미세조정
- bert-Large를 미세조정하여 Bert for Patents와 비교
- Bert for Patents
- 1M 이상의 USPTO의 영어 특허 문서로 scratch부터 학습된 bert-large (특허 특화 tokenizer를 사용하여 긴 token을 처리)
- USPTO-2M으로 미세 조정된 버전을 사용
- XML-CNN
- CNN-Kim (Yoon Kim. 2014. Convolutional Neural Networks for Sentence Classification) 기반으로 XML-CNN은 dynaimc maximum pooling을 사용하여 긴 텍스트의 위치 정보를 추출
- Hidden bottleneck 층을 pooling와 출력층 사이에 넣어서 더 좋은 표현자를 뽑도록 한다.
- Parabel
- XML 접근법의 트리 기반 알고리즘 중 하나
- 각 클러스터의 label 수가 주어진 값보다 작을 때까지 라벨 노드를 두 개의 균형 클러스터로 재귀적으로 나누어 라벨의 균형 이진 트리를 학습한 다음 확률적 계층적 다중 라벨 모델을 학습
- AttentionXML
- AttentionXML은 더 큰 label을 더 잘 처리하기 위해 (Yashoteja Prabhu, Anil Kag, Shrutendra Harsola, Rahul Agrawal, and Manik Varma. 2018. Parabel. In Proceedings ofthe 2018World WideWeb Conference on World WideWeb - WWW'18. ACM Press) 의 이진 분할 레이블 트리를 더 얕고 넓은 트리로 압축
- Multi-label mechanism을 갖춘 bi-LSTM은 raw text의 처음 500개 단어를 입력으로 사용하여 트리의 각 수준에 대해 훈련
- 단어 표현 레이어는 영어의 경우 Glove에 의해 초기화되고 프랑스어 특허의 경우 Wikipedia에서 훈련된 프랑스어 FastText로 초기화
- LightXML
- 다수의 사전 학습된 언어모델을 사용
- 마지막 5개 hidden state에서 [CLS]의 표현자를 연결해 text representation으로 사용
- Label recall network를 훈련하여 negative 샘플을 동적으로 샘플링한 다음 label ranking network를 통해 negative label로부터 positive label을 분리
Parabel과 AttentionXML은 3개의 앙상블을 사용하였다. LightXML에서 앙상블에 사용된 각기 다른 모델은 하기와 같다.
- USPTO-2M (영어)
- bert-base-uncased
- roberta-base
- xlnet-base-cased
- INPI French patent corpus (불어)
- camembert-base
- bert-base-multilingual-cased
- xlm-roberta-base
Rank-based Precision@K(P@K(%); k=1, 3, 5) 평가 지표를 적용
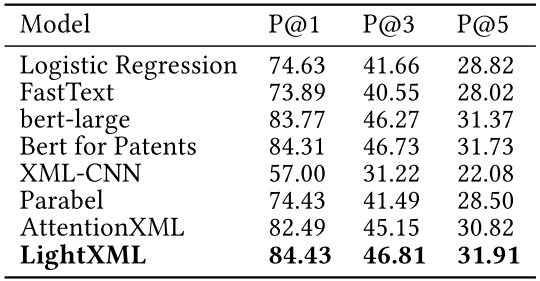
Large 모델을 사용한 Bert for Patents와 유사한 성능을 LightXML을 통해얻을 수 있다.
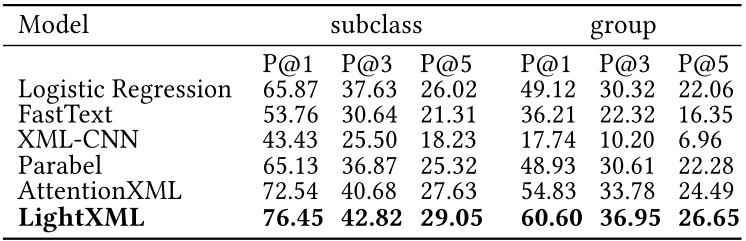
LightXML이 다양한 트랜스포머 인코더를 통해 뽑은 feature 덕에 모두 성능을 압도한다.
같은 모델이 USPTO-2M에서 더 좋은 성능을 보이는 이유
- USPTO-2M이 더 큰 데이터를 보유
- training/test 셋 간의 KL-divergence를 비교 시 USPTO-2M이 더 유사
프랑스 특허 말뭉치에서 Title과 Description의 조합이 최고의 결과를 달성
보다 정확하게는 입력 제약 조건이 느슨할 때(128개 하위 단어보다 훨씬 큼) 정밀도@1에서 약 4%~8% 향상.
그러나 max_sequence_length=128로 설정된 사전 훈련된 언어 모델을 사용하는 방법의 경우 제목+초록에 비해 제목+설명을 사용한 정밀도 향상은 2% 미만



