
* Test Collection available (restricted)
Abstract
여섯 특허청으로 부터의 multimodal과 multilingual을 포함하는 public 특허 데이터의 필요성이 있다. 새로운 특허 데이터는 기존의 vertical (몇 년 동안의 단일 domain 또는 단일 특허청 범위) 특허 데이터를 보완한다. 새로운 데이터는 horizontal (2년간의 상대적으로 짧은 기간 동안 주요 특허청으로부터 모든 기술적 도메인을 포함) 하다. 현재 여러 테스트 컬렉션에 분산되어 있는 문서를 통합하는 것 외에도 유럽, 미국, 일본, 중국의 문서를 보완하기 위해 최초로 한국어 문서를 제공한다.
Introduction
자연과학과 달리 Natural Language Processing(NLP) 분야에서는 효율 비교를 위한 단위가 없다. 두 시스템을 비교하기 위해서는 변인통제가 엄밀하게 되어야 한다. Test collection의 목적은 이러한 평가 지표의 단위를 만드는 것이다. Patent search test collections는 기존에 TREC, CLEF, NTCIR이 있다. 여기에는 image recognition과 topic mining과 같은 추가 task가 있었지만 이는 검색 고려시 부가적인 사항이였다. Patent search test collections은 horizontal(시간을 수직 축으로 고려)한 성격을 가진다.

Information retrieval(IR, e.g. link and content analysis; clustering, classification, and topic models) 작업을 위해서는 vertical한 대이터가 필요하다.
WPI 테스트 컬렉션은 모든 주요 기관(유럽 특허청(EP), 미국 특허청(US), 세계 지적 재산권 기구(WO), 중국 특허청(CN), 일본 특허청(JP) 한국 특허청(KR))의 특허를 다루며 여기에는 전체 서지 정보, 모든 문서의 전체 텍스트, 모든 관련 이미지 및 추가 자료가 포함되어 있다.
Relation to Other Collections

일본 NTCIR이 생성한 NTCIR 데이터, 유럽 CLEF가 생성한 CLEF-IP데이터, US NIST가 생성한 TREC-CHEM 데이터가 기존에 존재했다. 세 데이터 모두 retrieval task로 시작해 다른 task(translation, classification, text mining, image-based retrieval, and image analysis)가 추가되었다.
Data Content
- WPI test collection
- 2년 동안 6개 특허청의 모든 특허로 구성
- 총 6,313,165개의 특허 문서(XML 파일) / 55,231,022개의 추가 파일(이미지, 화학 구조 등)
- 컬렉션의 첫 번째 버전에서는 매우 많은 양의 데이터(압축, 5TB 초과)로 인해 PDF 파일을 생략
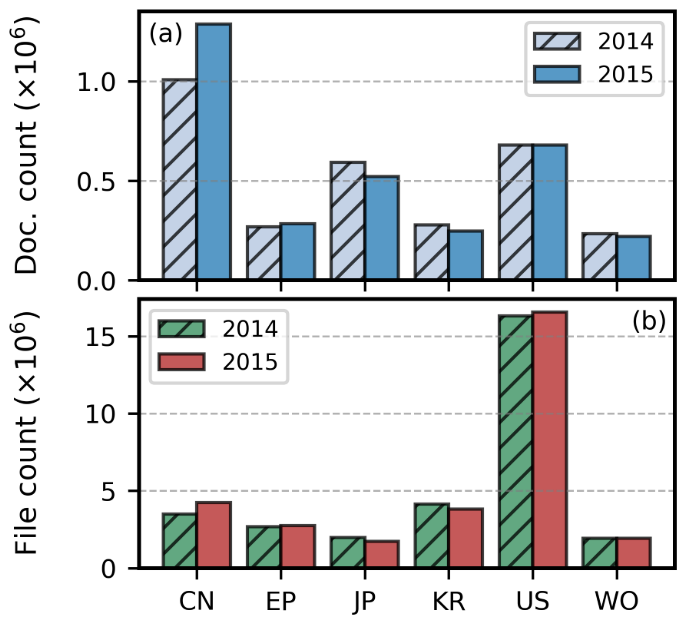
*이하 설명에서 "문서" 는 특허를 설명하는 파일을 "파일"은 collection 내의 문서 혹은 첨부자료를 포함하는 모든 파일을 의미, 문서는 extended ST-36 양식(https://www.kipo.go.kr/club/front/menu/common/print.do?clubId=database&menuId=3&curPage=1&searchField=&searchQuery=&messageId=12059)으로 되어 있다. Figure 2에서 특허 문서는 CN이 파일은 US가 많으며 USPTO에서 많은 보조자료를 발행한다.

Figure 3에서 kind codes(특허 출원까지 허가 절차를 표시) 간 분포의 분균형을 확인할 수 있다. 총 16개의 code 중 5개 A1, B2, A, B1, B가 전체 파일의 ~98%를 차지한다.

대부분의 파일이 미국 특허청의 A1과 B2 kind code에 집중되어 있다.

Figure 5에서 모든 특허청은 그림을 "tif" 파일(39,711,852 개) 형태로 사용한다. 또한 특허당 하나의 "xml" 파일(6,350,664 개) 이 존재하므로 비중이 큰 것을 예상할 수 있었다. 특이한 점은 한국과 미국 특허청에서 상당 수 화학 구조 파일을 cdx, mol 그리고 jpg 형태로 고려한다.

Figure 6에서 대부분의 특허는 영어(EN)와 중국어(ZH) 로 되어 있으며, 이후 일본어(JA)와 한국어(KO)가 많은 비중을 차지한다. 영어의 초록 비중이 높은 이유는 일본과 중국 출원 특허가 영어로 초록을 작성하기 때문이다.

Figure 7은 국가 별 특허의 International Patent Classification (IPC)의 section(첫 글자) 수를 보여준다. 중국 특허청에서 출원된 특허가 모든 분야에서 압도적으로 많으며, 미국 특허청에서 출원된 G, H section(각 Physic, Electricity)의 특허 수만이 유일하게 중국 특허청에서 출원된 특허와 수가 견줄만 하다. 모든 분야에서 D와 E(각 Textile-Paper, Fixed Constructions)는 수가 적다.
De-Anonymistation Use Case
[skip]
Conclusions
6개국 주요 특허청응로 부터 얻은 WPI Patent Test Collection을 제안한다. 해당 데이터는 IR과 data mining 연구에 있어 특허기관과 domain 영역에서 넓은 범위를 포함한다. 또한 기존 데이터에 부족했던 한국어를 포함한 주요 동아시아 언어의 말뭉치를 제공한다.



