
ABSTRACT
- 특허는 법적, 기술적, 극도로 모호한 언어가 혼합된 복잡하다.
- Rephrasing을 통해 특허 텍스트를 자동으로 simplification 하는 접근 방식을 제안한다.
- 대규모 특허 문장 silver standard을 제안한다.
- Candidates를 얻기 위해 우리는 general doamin paraphrasing 시스템을 사용한다.
- 추가적으로 적절한 필터와 결합하고 simplification 시스템을 훈련에 사용할 수 있는 코퍼스를 구성한다.
1 INTRODUCTION
특허 긴 문장, 새로운 다용어 항목, 반복되는 항목이 있는 절 대신 명사구로 구성된 복잡한 구문이 포함되어 있다. [특허가 rephrasing 되어야하는 당위성 설명] Suominen은 [...] Feldman은 [...].
특허 simplification 에 대한 이전 연구들은 변리사 이해를 돕기 위한 것으로 주로 전문가를 대상으로 했다. 권리 범위는 유지되어야 하므로 text presentation을 수정하는 것이 rephrasing 보다 선호된다. 해당 논문은 기존 연구 방향성과 다르게 description을 rephrasing 한다. 이는 특허 문서를 이해하기 쉽게하며 다른 도메인처럼 downstream task의 성능을 향상을 기대할 수 있다.
그러나 sentence simplification task 해결을 위한 병렬 말뭉치가 특허 도메인에 대해서는 존재하지 않는다.
본 논문에서는 특허 문장 simplification 병렬 말뭉치를 자동으로 생성하는 방법을 제안한다. 특히 우리는 simplification candidate pairs (bronze)으로 구성된 거대한 noisy 말뭉치를 생성하고 이를 정리하여 고품질 silver 말뭉치를 얻는다. Candidates를 생성하기 위해 우리는 일반 도메인 텍스트에 대해 훈련된 paraphrasing 시스템을 채택하고 특허에 대해 zero-shot으로 적용하면 결과가 좋았다. 그러나 오류가 존재하기 때문에 필터 적용에 대해 논의하고 silver 말뭉치가 어떻게 사용될 수 있는지 보여주겠다.
- General 도메인에서 학습된 paraphrasing 시스템을 zero-shot으로 사용하여 "bronze" simplification 말뭉치를 얻는 방법 제안
- 적절한 filtering 방식을 bronze standard에 적용. 대규모의 병렬 bronze와 silver standard 공개
- Silver standard로 seq2seq SOTA 시스템을 학습하여 결과를 보여줌
- 사람 평가 진행하고 관련 데이터 수집
2 PREVIOUS WORK
2.1 Sentence simplification
[skip] [introduction 내용 자세히 반복]
2.2 Patent simplification
[특허 텍스트 특히 청구항을 simplification 하는 다양한 기존 접근 방식들을 소개]
3 METHOD
3.1 Dataset
Patent Translation Resource (PatTR) 말뭉치를 사용한다. PatTR은 MAREC 특허 collection에서 추출한 문장 수준의 병렬 말뭉치이다. 다국어 (DE- EN, FR-EN, and DE-FR) 문장 쌍으로 구성되며 section (title, abstract, description and clams)별로 나뉘어 있다. 해당 데이터는 pre-tokenized 문장을 포함하고 있으며 기존 방식와 비교가 가능하다.
PatTR DE-EN Description 데이터는 12M 개의 문장 쌍이 있으며 이 중에서 500k를 sampling하여 사용했다.
전처리
- 4 < tokens < 56, 해당 범위에 포함되는 문장만 필터
- 문장 내 alphabet 비중이 60% 이하 삭제
- figure 인용 문구 삭제 (regex 사용)
남은 데이터 425,148개
Table 1은 해당 데이터의 통계를 보여준다.
- Flesch Reading Ease score: 평균 단어 길이(음절)와 평균 문장 길이(단어)의 함수로 문장의 simplicity를 계산한다. 높을수록 좋다.
- Flesch Kincaid Grade Level: 미국 교육 등급 수준에 따라 가중치를 적용한다. 낮을수록 좋다.
- WordRank score: 어휘 단순성의 대용으로 단어 빈도를 사용한다(더 일반적인 단어를 포함하는 텍스트가 이해하기 더 쉬운 것으로 간주됨). 이는 문장에 있는 모든 단어의 로그 순위(빈도 역순)의 3분위수를 취하여 계산된다.
- Maximum Dependency Tree: 구문 복잡성에 대한 프록시로 종속성 트리의 높이를 사용한다.
3.2 Generating simplification candidates using a general-domain paraphrasing system
General 도메인으로 학습된 seq2seq 시스템 중 Pagasus 기반의 paraphrasing 시스템을 선택했다. 시스템은 PAWS를 포함하여 60k의 다양한 데이터의 examples로 fine-tune 되었다(해당 모델은 Huggingface에서 사용 가능).
Table 2는 모델로 생성한 임의의 문장쌍이다. Simplification 주로 문장 압축과 어휘 대체를 통해 이루어진다.
Pegasus 모델을 바로 simplification을 위해 사용하는 데는 두 가지 주요 제한 사항이 있다.
- 생성된 문장은 오류를 포함하고 불명의 토큰을 포함 또는 과도하게 함축될 수 있다.
- 압축 수준을 제어를 포함 의역, 유사성, 어휘 단순화 수준도 통제하기 어렵다.
이런 이유로 위에 생성된 candidates를 "bronze corpus"라고 명명한다.
비교를 위해서 기계번역 모델로 생성한 candidates로 Table 3에 제안한다. 이 방법 번역쌍을 사용한 방법이기 때문에 다른 언어간의 문장 간 복잡도는 유사하며 읽기 점수가 상대적으로 높은 쌍만 유지하더라고 여전히 simplification 수준은 낮다.
3.3 Filtering bad candidates and generating a silver standard of patent sentences.
이 섹션에서는 bronze를 silver로 filtering 하는 기준에 대해 기술한다.
- Bad tokens: unk 토큰이 포함된 쌍을 제거 (Table 2. 10)
- Non-alphabetical characters: 생성된 문장 내 alphabet 비율이 60% 미만을 차지하는 쌍을 제거
- Similarity: 원본 문장과 simple 문장(길이의 합으로 정규화됨) 간의 문자 수준 Levenshteins 유사성이 < 25% 또는 > 90%인 문장을 제거합니다. (Table 2. 0 2 7 12 15)
- Compression: 생성된 문장 길이와 원래 문장 길이 사이의 비율이 > 1.5 또는 < 0.5인 쌍을 제거합니다. (Table 2. 4)
- Simplicity: Fresh Reading Ease 점수, WordRank 점수 및 문장 종속성 트리 높이를 평가 기준으로 이러한 점수에 따라 생성된 문장이 더 간단하지 않은 후보를 제거했다.
Table 4는 각 필터링 단계에서 제거된 쌍의 수를 예시와 함께 보여준다. 우리는 경험적으로 임계값을 선택했다. 남은 문장들로 silver standard를 구성하며 필터링 후 말뭉치 수는 287,965개다.

3.4 Using the corpus for training a controllable simplification system
Silver standard를 활용하여 ACCESS라는 sentence simplification SOTA 모델을 학습한다. 데이터는 train(184,297), validation(46,075) 및 test(57,593) 세트로 임의로 나눈다. Early stopping을 validatio SARI(인내심: 20)로 적용하여 모델을 훈련다. 인간 주석으로도 모델 평가를 진행했다(섹션 5.3).

Table 5는 EASSE 라이브러리를 사용하여 계산된 결과를 보여준다. 예상대로 실버 표준에 대한 지표는 특히 높다. 그러나 인간이 작성한 문장에서 모델을 평가할 때 성능은 다른 일반 도메인 데이터세트에서 얻은 성능과 비슷합니다. 특히 인간 평가 세트를 검증 세트(ACCESS 모델이 전처리 매개변수를 최적화하도록 허용)와 테스트 세트(실버 표준 검증 세트에서 계산된 최적의 매개변수만 사용)로 사용할 때 인간 평가 세트에 대한 결과도 비교한다.
4 CORPUS QUALITY ESTIMATION
4.1 Automatic metrics
- Normalized character-level Levenshtein similarity: 길이로 정규화
- BLEU and BERTScore: token 기반의 의미론적 유사도


Silver corpus가 Flesch 점수에서 더 높은 점수를 WordRank에서 낮은 점수를 기록하여 어휘 수도 적고 simplified 됐다고 볼 수 있다. 구문 복잡도 역시 tree depth로 비교해 볼 때 짧은 것으로 개선된 것을 확인할 수 있다.
4.2 Qualitative error analysis
100개의 문장 중 일부에 대해 분석하여 남아있는 오류를 확인해보았다.
- 과도한 혹은 잘못된 압축으로 중요한 요소가 삭제
Orginal : "Both the solid and the corrugated sheets preferably exhibit on one or both outer sides a layer consisting ofthe compositions according to the invention.”
Simplified: "The corrugated sheets have a layer consisting of compositions on one or both sides.” - 중요한 부사가 삭제
Orginal : "In some cases, it has proved advantageous to use emulsion polymers exhibiting reactive groups at the surface.”
Simplified: "In some cases, it has proved to be beneficial to use emulsion polymers with groups at the surface.” - 문장 구조가 복잡한 경우 구조가 파괴 됨
Orginal : "The contact lugs, projecting from the bearing plate ofthe motor, for the electrical feed ofthe motor are easily accessible there for the connecting cabling in the housing installation orifice.”
Simplified: "There is an easy way to connect the electrical feed ofthe motor to the housing installation orifice with the contact lugs projecting from the bearing plate.”
5 HUMAN EVALUATION
5.1 Evaluation details
Prolific 업체를 통해 Figure 2 양식을 기입할 수 있도록 하청을 맡겼다.
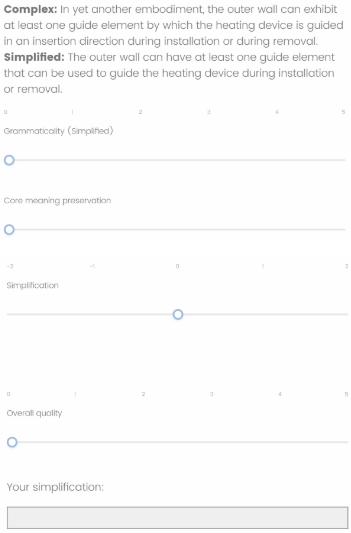
총 96개의 문장 쌍에 78명의 작업자들이 참여하여 문장쌍마다 평귱 3.93명이 참여했다.
5.2 Numerical scores
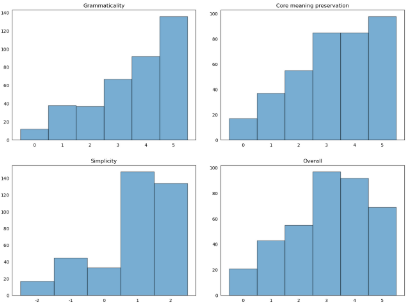
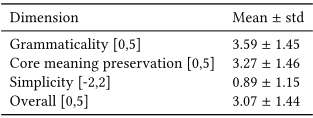
5.3 Human-written simplifications
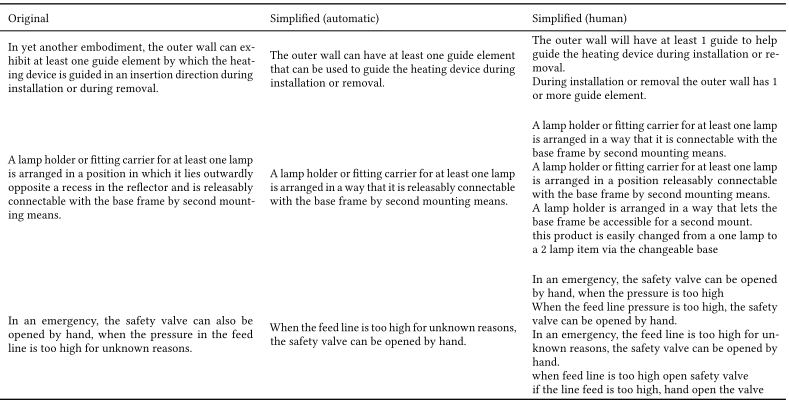

Table 8과 9에서 확인할 수 있는 것처럼 사람이 단순화한 문장은 기존보다 simplifed된 문장과 더 유사하다.
6 CONCLUSIONS
첫 특허 병렬 simplification silver standard를 개발했다. 또한 말뭉치에 대한 인간 평가를 수행하고 인간이 작성한 단순화를 수집했다. 이를 통해 어느 정도 단순화된 코퍼스를 얻을 수 있음을 보여주었다.



