
ABSTRACT
- 기존 visual document understanding (VDU) 모델은 다른 분포의 데이터에 좋은 성능을 보여주지 못함
- out-of-distribution (OOD) benchmark Do-GOOD을 개발 (9 OOD dataset, 3 VDU related tasks)
- 5개의 최신 VDU 모델 평가 결과 OOD에 취약한 결과
1 INTRODUCTION
Background.
문서 이미지 처리는 삶에서 빈번하게 일어나고 있으며 최근 AI 모델을 통해 어느 정도 성능을 달성
Motivation.
모델 성능이 OOD dataset에 저하된다는 것을 알았으며 robustness를 평가하기 위한 benchmark도 보고되었다.
비록 RVL-CDIP OOD dataset의 이미지가 문서 분류에 중요한역할을 한다는 것을 알았지만 다른 task에 대해서는 그렇지 않다.
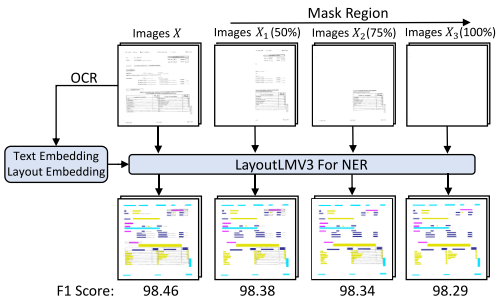
Figure 1에서 image masking 비율을 높여가며 NER task 성능을 비교한 결과 거의 비슷한 결과를 얻을 수 있었고 이는 visual cues는 모델 예측에 사용되지 않는 것을 알 수 있다. 문서 이미지는 image, text, 그리고 layout 정보가 복잡하게 상호작용하고 있으며, 이러한 특징들을 취급하는 모델은 각각을 취급하는 모듈을 필요로 한다. 기존의 pre-trained VDU 모델은 문서 이미지 task의 미세한 분포 이동에 얼마나 robust 한지? 질문을 일으킨다.
Contribution.
OOD benchmark을 위해 다음의 기준을 가지고 디자인했다.
- 훈련 데이터와 테스트 데이터 사이의 분포 격차가 크면 모델 성능이 크게 저하될 수 있다.
- 분포 변화에 대한 세밀한 분석은 기존 모델의 취약한 특성을 드러낼 수 있다.
- 설계된 벤치마크 데이터 세트는 해결 가능하고, 쉽게 확장 가능하며, 사람이 읽을 수 있어야 한다.
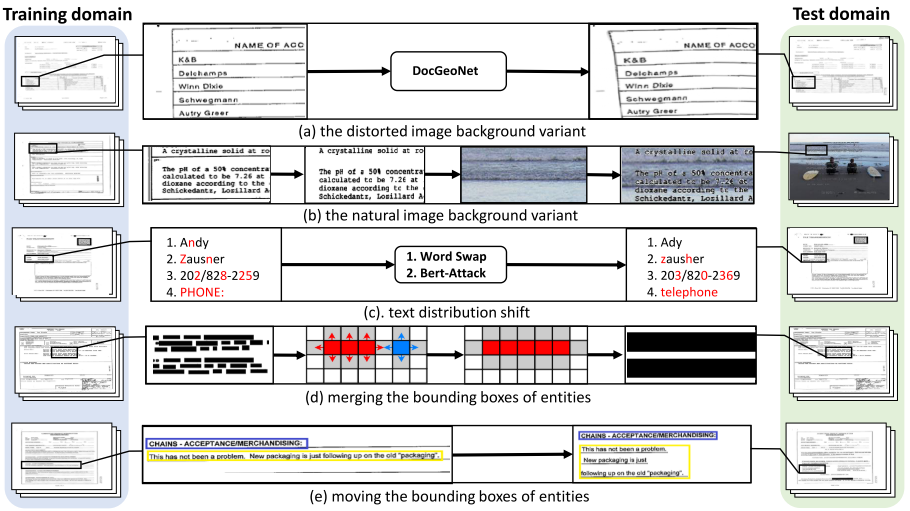
기준 2.를 만족하기 위해 Figure. 2처럼 image, text 그리고 layout의 분포를 변화를 준다. Image, text, 그리고 layout 관점에서 신중하게 설계된 strategies는 OOD 테스트베드를 자동으로 생성하여 기준 (1)과 (2)를 충족할 수 있다.
요약
- 이미지, 텍스트 및 레이아웃 관점에서 문서 이미지의 다양한 분포 변화에 대한 세밀한 분석을 제공
- OOD 데이터를 생성하는 일련의 자동 strategies 를 도입
- 다양한 문서 image 작업에 걸쳐 생성된 OOD 테스트베드(즉, Do-GOOD)에서 사전 훈련된 5개의 최신 VDU 모델과 2개의 대표적인 OOD 알고리즘을 평가하고 비교
2 RELATED WORK
Visual Document Understanding.
분류, 정보추출, QA는 문서 처리의 핵심 task이다. 분류는 CNN 그리고 OCR 출력을 이용한 RNN 혹은 Transformer 기반의 연구가 DocVQA에 대해서는 LSTM 과 CNN 인코더를 이용한 방식으로 연구가 진행되었었으며, 최근 NLP에서 성공을 거둔 BERT와 RoBERTa와 같은 모델에 downstream tasks를 함게 훈련한 연구가 있다.
최근 연구는 문서 image로 부터 text, vision, 그리고 layout 정보를 가져와서 개별로 처리한 후 합친다. LayoutLM 계열은 2차원 위치 벡터를 이용하여 layout 정보를 합쳤다. Donut의 경우 end-to-end 로 OCR을 수행하지 않고 추론을 진행했다. LayoutLMv3의 경우 patch 수준으로 text와 image를 정렬하여 사용했다.
Out-of-Distribution Benchmarks.
최근 연구는 분포 내 모델의 성능을 끌어올리는 것보다 모델의 robustnes와 generalization용량을 파악하는 것에 집중된다. 따라서 다양한 OOD benchmarks(WILDS, GOOD, graph OOD, Wiles at el.)가 생성되었다.
문서 이미지 tasks에서도 다양한 OOD benchmarks가 있다. Larson et al.은 in-domain의 다른 분포인 RVL-CDIP-N과 OOD인 RVL-CDIP-O 두 testbed를 보고했다. LastDoc4000은 OCR 오류로 생성될 수 있는 상황을 포함한다. 하지만 위 두 종류는 layout과 text 분포의 변화는 고려하지 않고 IE task에만 집중하였다. 이와 대조적으로 Do-GOOD는 여러 일반적인 문서 이미지 작업 전반에 걸쳐 text, vision, 그리고 layout의 분포 변화를 이미지 중심에서 텍스트 중심 관점으로 고려한다.
3 DO-GOOD BENCHMARK DESIGN
우리는 $p_{train}$에서 훈련된 모델 $f$가 $p_{test}$로 일반화되어야 하는 이유를 조사하기 위해 text, vision, 그리고 layout 과 관련된 속성으로 나누어 문서 이미지의 분포 변화에 대한 세밀한 분석을 제공한다. 입력 문서 이미지 $x$에 대해 라벨 $y^l$과 세 속성 $\{y^{image}, y^{text}, y^{image}\}$ 로 구성된다. $$y^{1:K}= \{y^l, y^{image}, y^{text}, y^{image}\}$$ 그러면 분포의 이동을 다음과 같이 공식화할 수 있다. $$ p(y^{1:K},x) = p( y^{1:K})p(x| y^{1:K})$$ 잠재 변수 모델의 도움으로 공식화는 다음과 같이 작성될 수 있다. $$ p(y^{1:K},x) = p( y^{1:K}) \int p(x|z) p(z| y^{1:K}) dz $$ 즉, 위 수식에 따라 다른 속성 $y^{1:K}$는 데이터 $x$ 생성에 영향을 줄 수 있다.
3.1 Image-Specific Distribution Shift

Background 변화로 자연과 왜곡된 이미지를 배경으로 사용한다.
- 배경에서 텍스트 콘텐츠를 분리
OCR 도구에서 제공하는 위치 정보를 기반으로 텍스트 내용을 찾고 문서 이미지에서 텍스트 내용의 픽셀을 추출. 나머지 픽셀은 배경 픽셀로 간주. - 원본 배경을 자연 이미지로 대체
MSCOCO에서 이미지를 무작위로 선택하여 문서 이미지 크기에 맞게 크기를 조정. 새로운 OOD 샘플을 구성하기 위해 추출된 텍스트 콘텐츠를 샘플링된 자연 이미지 위에 배치.
유사한 방법으로 왜곡된 이미지 데이터를 생성하며 이 때 DocGeoNet을 사용하여 왜곡시킨다.
3.2 Text-Specific Distribution Shift
입력 문서 이미지는 OCR 오류로 인해 텍스트 문제를 포함할 수 있다. 두 가지 text attack 전략(BERT-Attack, Word Swap)을 사용하였다.

BERT-Attack의 장점은 생성된 샘플의 유창성과 의미 보존을 보장하면서 유사하지만 보이지 않는 단어를 생성할 수 있다. Word Swap의 경우 OOD 샘플을 생성하는 5가지 방법을 적용한다. (1) 임베딩 벡터를 사용하여 유사한 단어를 찾아 스왑한다. (2) 모양은 거의 동일하지만 의미는 다른 단어를 대체 (3) 숫자를 다른 숫자로 대체 (4) "houses"에서 "hoses" 등 단어의 특정 글자를 삭제하는 행위
*본문에 5개라는데 4개만 적혀있어 오타로 추정.
3.3 Layout-Specific Distribution Shift
Layout 분포 변경 방식으로는 Merge와 Move가 있다.

Bounding box를 merge하는 알고리즘은 아래와 같다.

강력한 텍스트 의미가 있는 bounding box를 선택한 다음 텍스트가 없는 곳으로 이동한다. 만약 10번 이동하였는데도 예측 결과가 변화하지 않는다면 해당 텍스트는 강력한 의미를 가지고 있다고 예측할 수 있다.
4 DO-GOOD DATASETS
이 섹션의 목적은 제안된 Do-GOOD benchmark에 사용된 datasets를 소개하는 것이다. 먼저 특정 VDU 작업에 대한 분포 이동 옵션을 분석하기 위한 예비 연구를 수행한다. 마지막으로 3개의 VDU 작업에 걸쳐 9개의 데이터 세트가 구성된다.
4.1 Preliminary Study
특정 데이터 세트 및 작업에 대해 OOD 테스트 데이터 세트를 개발하기 위해 어떤 분포 이동을 선택해야 하는지 결정하기위해 선행 연구를 수행했다. LayoutLMv3BASE를 기본 모델로 사용하고 추론을 위해 해당 입력 임베딩을 제거하여 이미지, 레이아웃 및 텍스트 정보의 효과를 격리한다.

FUNSD (Information Extraction, NER) : Image 정보가 중요하지 않음
RVL-CDIP (Classification) : 분류의 경우는 Layout 정보 뿐만 아니라 Image 정보가 더 중요하게 작용
DocVQA (QA) : 대부분 Text 정보에 영향을 받으며, Text만 사용할 경우 제일 좋은 성능을 보여줌
4.2 Document Information Extraction Task
IE는 FUNSD를 기반으로 OOD 데이터 세트를 생성한다.

FUNSD-L
FUNSD-L은 두 가지 레이아웃별 배포 이동(병합 및 이동)에 기반한 전략을 통해 생성된 OOD 샘플을 포함하는 FUNSD의 변형이다. 우리는 문서 이미지 내의 경계 상자를 무작위로 섞고 미세 조정된 모델을 사용하여 30번 추론한다. 텍스트의 경우 모델 예측에 오류가 적으면 의미론적 강도가 더 높다.
FUNSD-T
두 가지 텍스트 공격 방법으로 생성된 OOD 샘플을 포함하는 FUNSD의 변종이다.
FUNSD-R
FUNSD의 실제 OOD 데이터세트 변형 중 하나로 실제 OOD 데이터 세트와 생성된 OOD 데이터 세트에 대한 VDU 모델의 성능 격차를 표시하는 데 사용된다. RVL-CDIP에서 FUNSD의 분포와 다른 데이터를 선택한다. FUNSD-R에는 총 50개의 문서 이미지가 포함되어 있다.
FUNSD-H
인간 개입 OOD 데이터 세트 FUNSD의 변형이다. 실제로 우리는 약한 텍스트 엔터티를 이동하여 레이아웃과 이미지 이동을 구성하거나, 강한 의미 콘텐츠 주위에 의미상 연결된 몇 가지 텍스트를 추가하여 3가지 종류의 이동을 구성했다. 총 50개의 OOD 샘플이다.
4.3 Visual Document Classification Task
RVL-CDIP는 특정 문서의 카테고리를 예측하는 문서 분류 데이터 세트다. 여기에는 16개 범주의 400,000개 데이터 예제가 포함되어 있으며 이는 320,000개의 훈련 샘플, 40,000개의 검증 샘플 및 40,000개의 테스트 샘플이다.
RVL-CDIP-T
두 가지 텍스트 공격 방법으로 생성된 OOD 샘플을 포함하는 RVL-CDIP의 변형이다.
RVL-CDIP-L
두 가지 레이아웃별 분포 이동을 통해 생성된 OOD 샘플이 포함된다.
RVL-CDIP-I
자연적인 RVL-CDIP-I1과 왜곡된 RVL-CDIP-I2 이미지 분포 이동을 통해 생성된다. (Figure 3 참고)
4.4 Document Visual Question Answering Task
DocVQA 데이터 세트는 각 학습/검증/테스트용 질문 39,463/5,349/5,188개와 10,194/1,286/1,287개 이미지로 구성된다.
DocVQA-T
OCR 결과와 Microsoft READ API에서 텍스트, 질문 및 답변을 수집 후 두 가지 텍스트 공격 방법으로 생성된 OOD 샘플을 얻는다.
5 EXPERIMENT
5.1 Evaluation on state-of-the-art VDU Models
VDU Models.
Fine-tuning의 robustness를 평가하기 위해 다음의 모델을 평가한다.
- Text + Layout: BROS, LiLT
- Text + Layout + Image: LayoutLMv1, LayoutLMv2 및 LayoutLMv3.
Implementation Details.
Information extraction의 경우 학습률은 3e-5로 설정하고 훈련 epochs는 70으로 설정했다. RVL-CDIP 는 Tesseract 3 OCR 엔진을 사용하여 단어를 추출했다. 학습률은 1e-6으로 설정하고 훈련 에포크는 30라운드로 설정했다. DocVQA 작업의 경우 학습률은 2e-5로 epoch는 40이다. 모든 입력 이미지의 해상도는 224,224픽셀이며 훈련 중인 배치는 4로 설정되고 테스트 중인 배치는 1로 설정된다.
Main Results.
In-Domain 다운스트림 데이터 세트에서 사전 훈련된 VDU 모델을 미세 조정하고 ID 및 OOD 데이터 세트 모두에서 테스트하는 실험을 수행한다.

Table 2를 참고하여 대부분의 경우에서 LayoutLMv3가 최고의 성능을 달성했다. BROS는 FUNSD 4개의 OOD에 대해 좋은 결과를 보여주었다. 이로부터 미세한 모델링 예로 patch-level 또는 region-level이 OOD 환경의 robustness에 기여한다는사실을 알 수 있다.
Results on FUNSD-L Dataset.

Table 3에서 LayoutLMv3는 FUNSD-L 데이터 세트에서 최고의 성능을 달성했으며 BROS는 최악의 기타 오류 점수를 얻었다. LayoutLM 및 LayoutLMv2는 기타 오류가 더 높으며, 이는 약한 의미 영역의 예측이 이러한 모델의 강한 의미 영역 레이아웃에 의해 쉽게 영향을 받을 수 있음을 나타낸다. LayoutLM은 또한 QA 오류가 더 높으며 이는 강력한 의미 엔터티의 예측이 여전히 주변 엔터티의 영향을 받을 수 있음을 나타다. 낮은 헤더 정확도는 모델이 위치로 헤더를 예측한다는 것을 의미한다.
Results on FUNSD-T Dataset.

Table 4에서 LayoutLMv3가 6개의 텍스트 분포 변화 중 5개에서 최고의 성능을 달성한다는 것을 관찰했다. LayoutLMv3가 얼마나 text 값에 대해 robust한지 보여주며, Homohlyph 결과로부터 LayoutLMv3 모델이 OCR 오류로 인한 의미론적 OOD를 처리할 때 다른 모델보다 더 robust하다.
5.2 Evaluation on Typical OOD Algorithms
또한 세 가지 다운스트림 작업에 걸쳐 모든 OOD 데이터 세트의 대표적인 OOD 알고리즘을 LayoutLMv3BASE로 비교한다.
Baseline Methods.
Empirical risk minimization(ERM)와 두 가지 OOD 알고리즘을 기준으로 사용합니다. ERM의 목표는 긍정적인 사건의 잠재력을 최대화하고 부정적인 사건의 영향을 최소화하는 것이다. 두 가지 OOD 방법은 Deep Coral과 Mixup입니다. Deep Coral은 소스 도메인과 대상 도메인 간의 2차 통계를 정렬하여 도메인 adaptive effects를 달성한다. Mixup은 입력 기능과 레이블을 interpolate하여 과도한 오버헤드 없이 데이터 증대를 달성한다.
Main Results.

Table 5에서 대부분의 경우 ERM이 Deep Coral보다 성능이 좋다. Mixup은 FUNSD의 OODR 및 OODH 설정에서 ERM보다 성능이 나지만 OODT 및 OODL 설정에서는 ERM보다 성능이 낮으므로 세분화된 종합 평가 개발이 OOD 일반화에 중요하다.
정보 추출 작업의 경우 Deep Coral과 Mixup은 OODR 및 OODH에서 ERM보다 성능이 뛰어나다. FUNSD의 레이아웃 분포 변화 측면에서 ERM은 Deep Coral과 Mixup보다 약간 더 나은 성능을 발휘한다. 이는 일반적인 OOD 알고리즘이 과도한 레이아웃 정보 변경에 대처할 수 없기 때문일 수 있다.
문서 이미지 분류의 경우 Deep Coral 및 Mixup은 OODI1 및 OODI2 설정에서 ERM보다 성능이 뛰어나지만 여전히 OODL에서 성능이 떨어진다. 이는 common OOD 알고리즘이 높은 수준의 이미지 정보 모델링이 필요한 문서 분류 작업에서 좋은 성능을 발휘함을 나타낸다.
DeepCoral과 Mixup은 문서 시각적 질문 답변 작업에서 ERM보다 낮은 점수를 받았다. 이 연구는 문서 시각적 질문 답변과 같은 복잡한 작업의 분포 변화가 일반적인 OOD 알고리즘을 사용하여 쉽게 처리될 수 없음을 보여준다.
5.3 Further Analysis
Effect of OOD Samples Generated by Different VDU Models.
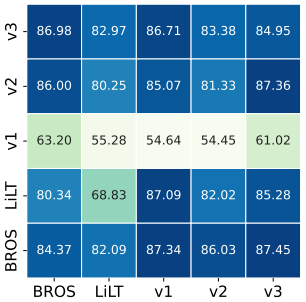
FUNSD-L의 샘플 생성은 의미론적 강도를 평가하기 위해 모델에 의존하기 때문에 다른 모델에 의해 레이아웃 분포 이동에 따른 OOD 샘플이 생성될 때 모델의 성능이 크게 저하되는지 여부를 조사하기 위한 실험을 수행한다. Figure 4로 부터 LayoutLM은 더 낮은 성능을 LayoutLMv3와 BROS는 높은 성능을 보여준다. 이는 패치 수준 및 지역 수준 정보 모델링과 같은 세분화된 정보 모델링이 모델의 견고성을 향상시킬 수 있음을 보여다.
Effect of Text Shift on Document VQA Task.

DocVQA 테스트 세트에서는 텍스트 정보에만 집중한다. Figure 5a는 각 분포 이동에 따른 결과를 보여줍니다. Bert-Attack이나 Word Swap의 영향으로 모든 모델의 ANLS가 정확도 측면에서 약 10포인트 정도 하락한 것을 확인할 수 있다.
Effect of Merge Distance.
figure 5b에서 1은 수직 간격을 의미하고 2는 수평 간격을 의미한다. 수직 병합이 수평 병합보다 예측 정확도를 더 감소시킨다.
Effect of Incremental Training with Do-GOOD.

Figure 6a에서 처럼 당연하게도 학습에 각 데이터를 포함시키는 양이 많을수록 성능이 향상된다. Figure 6b에서 학습 데이터에 OOD를 추가하면 특히 자연 배경을 추가한 데이터에 대한 예측이 급격하게 상승한다.
6 CONCLUSION
본 논문에서는 기존 VDU 모델의 robust를 평가하는 OOD(Out-of-Distribution) 벤치마크, 즉 Do-GOOD를 소개한다. 이미지, 텍스트, 레이아웃의 분포 변화에 대해 논의했다. 우리는 3가지 문서 이미지 관련 작업을 다루는 9개의 OOD 데이터 세트를 얻었다. 이러한 OOD 데이터 세트를 기반으로 기존의 사전 훈련된 VDU 모델 5개와 일반적으로 사용되는 OOD 일반화 알고리즘 2개를 사용하여 실험을 수행했다. 이는 기존 VDU 모델과 OOD 일반화 알고리즘의 취약성을 보여준다.



