어텐션 (Attention)
○ Sequnce-to-sequence: 병목 문제 (the bottleneck problem)
감성 분석 문제에서는 문장 전체를 보지않고 마지막의 hidden state만으로도 좋은 성능을 낼 수 있었지만, 기계 번역 작업의 경우엔 각각의 단어가 무엇이고 그 배열이 어떤지가 중요하기 때문에 해당 방식으로 접근할 경우 encoder RNN의 마지막 hidden state에 모든 정보가 쏠리는 정보 병목 문제 (information bottleneck problem)이 발생한다. 단순히 사람이 번역을 할 경우에도 변역하면서 원문장 (source sentence)를 확인하며 어떤 단어가 어떻게 배열되어 있는지를 확인한다. 이 개념에서 시작된 것이 Attention이다.

○ 어텐션 (Attention)
어텐션은 병목 문제를 해결하기 위해서 제안되었다.
핵심 아이디어는 디코더의 각 단계에서 인코더에 직접 연결하여 소스 시퀀스의 특정 부분에 초점을 맞춥니다.

target 문장의 첫 단어를 번역하기 위해서 초점을 맞춰야할 source 문장 내의 단어의 어디에 주목해야하는지를 알아보고 싶다. 모델 상에서 위 그림을 이용하여 설명하면 decoder의 hidden state를 이용하여 encoder의 정보를 직접적으로 가져오고 싶다. 따라서 decoder의 hidden state와 encoder의 각 위치에서의 hidden state 내적을 통해 attention score 다른 말로 유사도를 확인한다.
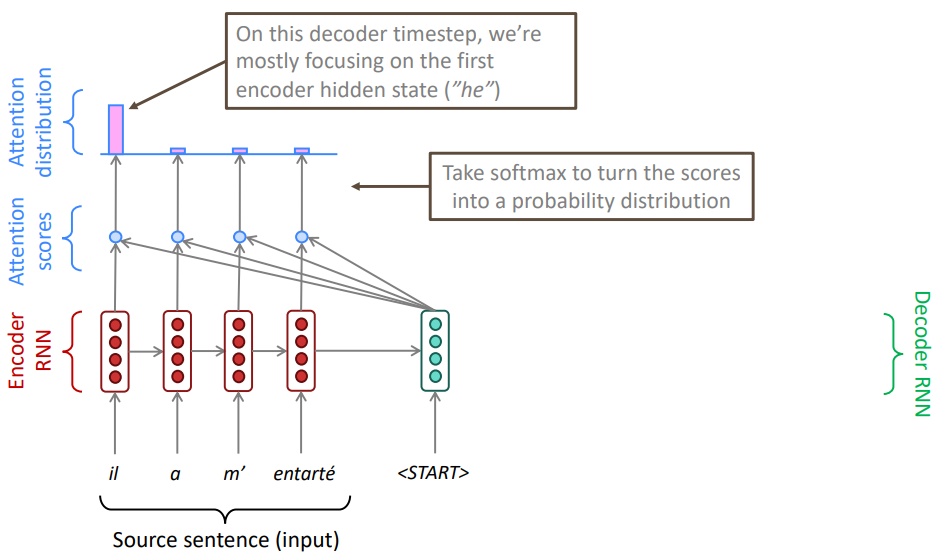
이후 구해진 각각의 attention score에 softmax를 취해 각 단어의 attention 확률 분포를 구한다. 이를 통해 해당하는 decoder state가 어떤 encoder state와 유사한지 확인이 가능하다. 위의 그림에서 결과적으로 decoder의 <START>를 번역하려면 encoder의 첫 state 단어인 il에 집중해야 한다는 것을 알 수 있다.

구해진 attention 확률 분포를 통해 encoder state들의 가중 평균을 내 attention output을 구할 수 있으며 이는 당연하게 높은 attention score를 지닌 hidden state 정보를 많이 포함하고 있다.
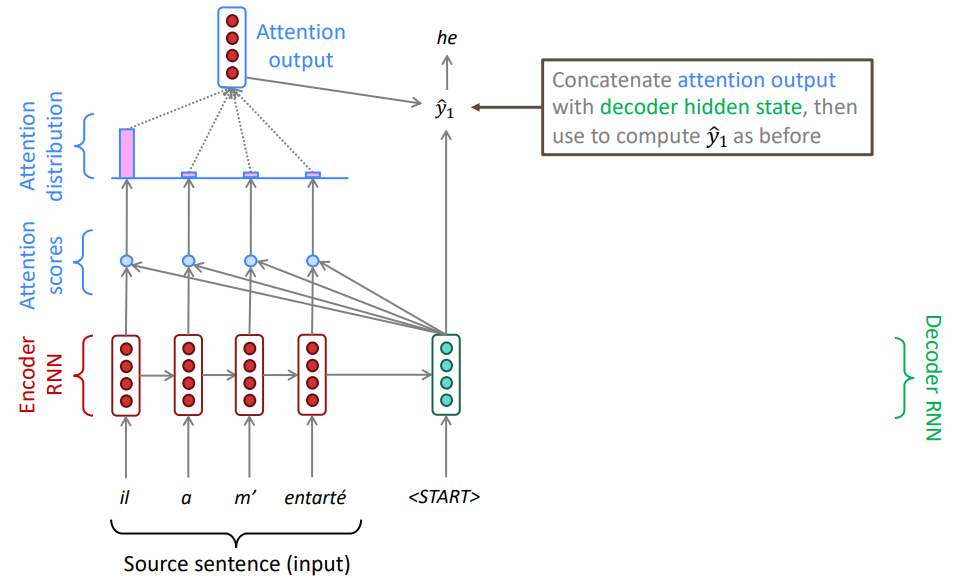
이후 attention output과 decoder의 hidden state를 연결한 후 softmax를 취해주어 단어를 예측할 수 있다. 이후에는 위 작업을 target 문장의 각 단어에 대해 반복해주면 된다. 때로는 이전 step의 attention output을 decoder의 입력으로 넣어줄 수도있다. (assignment 4에 포함)

conditional language model에서 이런 방식으로 반복하여 얻은 target 문장은 source 문장으로부터 더 많은 정보를 가져올 수 있기 떄문에 더 유연하고 좋은 번역을 얻을 수 있다.
일련의 과정을 보면서 우리는 attention을 decoder에도 적용하는 것을 생각해볼 수 있다. 이것을 self-attention이라고 한다. 개념적으로 생각해볼 때 source 단어의 어디에 집중해야할지만 알면되고 decoder의 경우 LSTM을 이용하면 기존의 RNN문제가 어느정도 해결되므로 충분할 것으로 생각되지만, self-attention의 성능이 월등히 좋은 결과를 보여주었으며 이는 과거의 정보가 decoding에서도 중요하다는 것을 의미한다.
○ 어텐션 (Attention) : 수식
- encoder hidden states = $h_{1},...,h_{N}\in \mathbb{R}^{h}$
- timestep t에서 decoder hidden states = $s_{t}\in \mathbb{R}^{h}$
- t에서 attention score: $e^{t}=[s^{T}_{t}h_{1},...,s^{T}_{t}h_{N}]\in \mathbb{R}^{N}$
- t에서 attention 분포 $\alpha ^{t}$를 구하기 위해 softmax를 취해준다. (총합은 1이다): $\alpha ^{t}=\texttt{softmax}(e^{t})\in \mathbb{R}^{N}$
- $\alpha ^{t}$를 가중하여 encoder hidden states의 합인 attention output: $a_{t}=\sum_{i=1}^{N}\alpha^{t}_{i}h_{i}\in \mathbb{R}^{h}$
- $a_{t}$를 decoder hidden states $s_{t}$와 concatenate: $[a_{t};s_{t}]\in \mathbb{R}^{2h}$
○ 어텐션 (Attention) 장점
- 어텐션은 NMT 성능을 상당히 향상시켰다.
- decoder가 source의 특정 부분에 집중하게 하는 것은 효과적이였다.
- 어테션은 기계번역에서 더 "사람 같은" 모델을 제공한다.
- 문장을 전부 기억해 두는 것이 아니라 번역과정에서 source를 되돌아 본다.
- 어텐션은 병목 문제를 해결했다.
- 어텐션은 기울기 소실 문제를 도와준다
- 멀리 떨어진 state까지 지름길을 제공한다.
- 어텐션은 어느 정도의 해석 가능성을 제공한다.
- 주의 분포를 검사함으로써, 우리는 디코더가 무엇에 초점을 맞추고 있었는지 알 수 있다.
- 네트워크가 스스로 정렬을 학습했습니다.
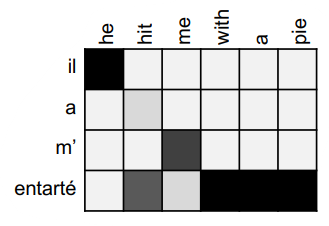
○ 다양한 어텐션 (Attention)
해당 변수들을 가진 상태에서, Vaule:$h_{1},...,h_{N}\in \mathbb{R}^{d1}$, Query:$h_{1},...,h_{N}\in \mathbb{R}^{d2}$
어텐션은 항상 아래를 포함해야한다.
- attention score: $e\in \mathbb{R}^{N}$
- attention distribution: $\alpha=\texttt{softmax}(e^{t})\in \mathbb{R}^{N}$
- attention output: $a=\sum_{i=1}^{N}\alpha^{t}_{i}h_{i}\in \mathbb{R}^{d_{1}}$
- 기본 dot-product attention: $e^{i}=s^{T}h_{i}\in \mathbb{R}$
- $d_{1}=d_{2}$ 라고 가정한다.
- hidden states 내의 모든 정보가 다 필요하지 않을 수 있다. 예를들어 decoder의 LSTM의 경우 이전 정보에서 얼마만큼 어떤 정보를 가져올지와 같은 정보는 attention score 계산에 필요없을 것이다.
- Multiplicative attention: $e^{i}=s^{T}Wh_{i}\in \mathbb{R}$ [Luong. Pham, and Manning 2015]
- $W\in \mathbb{R}^{d_{2}\times d_{1}}$
- W를 학습하여 hidden states 내의 중요한 위치에 집중할 수 있게 되었지만, 매개 변수가 너무 많다.
- Reduced rank multiplicative attention: $e^{i}=s^{T}(U^{T}V)h_{i}=(Us)^{T}(Vh_{i})$
- $U\in \mathbb{R}^{k \times d_{2}}, V\in \mathbb{R}^{k \times d_{1}}, k < d_{1}, d_{2}$
- $k$로 차원을 감소시켜 더 효율적으로 연산을 수행.
- Additive attention: $e_{i}=v^{T}\texttt{tanh}(W_{1}h_{i}+W_{2}s)\in \mathbb{R}$ [Bahdanau, Cho, and Bengio 2014]
- $W_{1}\in \mathbb{R}^{d_{3}\times d_{1}}$, $W_{2}\in \mathbb{R}^{d_{3}\times d_{2}}$ 는 weight matrices, $v\in \mathbb{R}^{d_{3}}$는 weight vector이다
- $d_{3}$는 hyperparameter이다.
- 신경망을 이용하여 attention score를 구한다.
○ 어텐션은 일반적인 딥러닝 기술
우리는 기계 번역의 시퀀스 투 시퀀스 모델을 개선하는 데 관심이 좋은 방법이라는 것을 알았다.
그러나: 많은 아키텍처(seq2seq뿐만 아니라)와 많은 작업(MT뿐 아니라)에서 어텐션을 사용할 수 있다
더 일반적인 어텐션 정의: 벡터 값의 집합과 벡터 query가 주어지면, 어텐션은 query에 따라 value의 가중치 합계를 계산하는 기술이다.
Intuition:
가중치 합계는 value에 포함된 정보의 선택적 요약이며, 여기서 query는 어떤 값에 초점을 맞출지 결정합니다.
어텐션는 다른 표현(쿼리)에 따라 임의의 표현 집합(값)의 고정 크기 표현을 얻는 방법이다.
Upshot:
어텐션은 딥러닝 모델에서 강력하고 유연한 일반적인 포인터 및 메모리 조작이 되었다. 2010년 이후에 나온 새로운 아이디어!
Reference)
Slide: cs224n-2021-lecture07-nmt.pdf (stanford.edu), cs224n-2021-lecture08-final-project.pdf (stanford.edu)
Note: CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part V Language Models, RNN, GRU and LSTM (stanford.edu)
Video: Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 7 - Translation, Seq2Seq, Attention - YouTube, Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 8 - Final Projects; Practical Tips - YouTube
'교육 > CS224N winter 2021' 카테고리의 다른 글
| Lec10) Transformers and Pretraining (0) | 2022.07.05 |
|---|---|
| Lec 9) Self-Attention & Transformers (0) | 2022.06.16 |
| Lec 7) Translation, Seq2Seq (0) | 2022.06.14 |
| Lec 6) Simple and LSTM RNNs (0) | 2022.05.18 |
| Lec5) Language Models and RNNs (0) | 2022.05.11 |



