지난 강의에 이어
○ 단순 RNN 언어 모델 (Simple RNN Language Model)
지난 수업에서 n-gram 언어 모델의 단점을 보완하기 위해 fixed-window 신경망 언어 모델을 사용하여 희소성(sparsity) 문제와 용량 문제를 해결하였다.
이후 simple RNN을 사용하여 입력값의 크기에 의존하지 않으며 어순에 대한 고려도 가능하게 되었다.
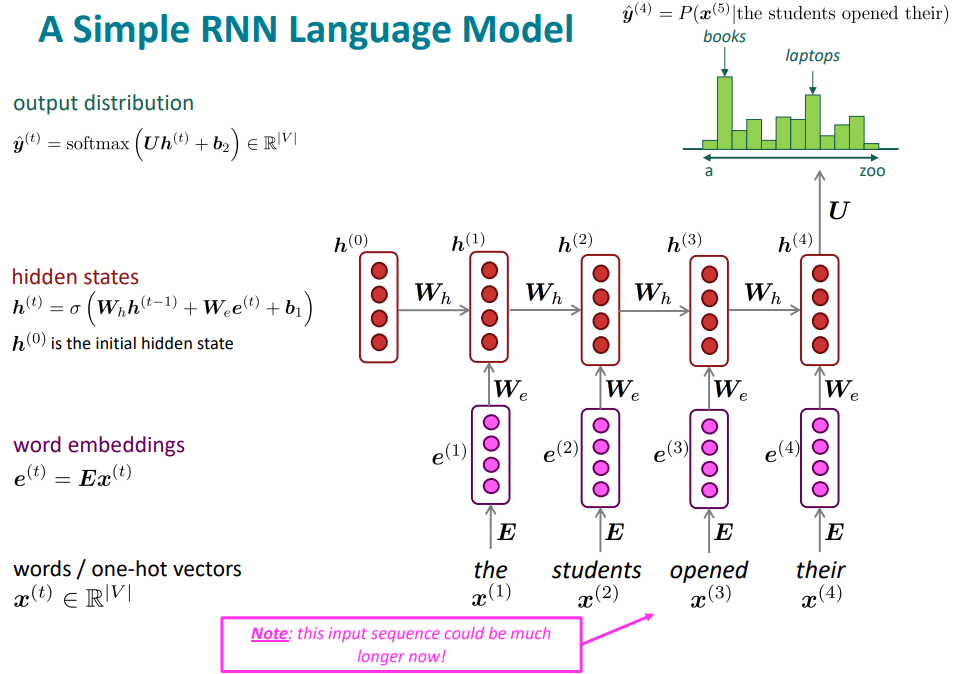
○ RNN 언어 모델의 학습
- 단어들의 나열인 $x^{(1)}, x^{(2)}, ..., x^{(T)}$ 큰 말뭉치를 준비
- RNN 언어 모델에 넣어 결과 확률 분포 $\hat{y}^{(t)}$을 매 timestep t마다 구한다
- timestep t에서의 손실 함수(Loss function)은 예측 확률 분포 $\hat{y}^{(t)}$와 실제 단어 $y^{(t)}$의 cross-entropy
$$J^{(t)}(\theta)=CE(y^{(t)}, \hat{y}^{(t)}) =- \sum_{w\in V}y^{(t)}_{w}log\hat{y}^{(t)}_{w}=-log\hat{y}^{(t)}_{x_{t+1}}$$ - 총 손실을 알기 위해서는 훈련 셋 전체의 평균을 구한다
$$J(\theta)=-\frac{1}{T}\sum^{T}_{t=1}J^{(t)}(\theta)=-\frac{1}{T}\sum^{T}_{t=1}-log\hat{y}^{(t)}_{x_{t+1}}$$
평균을 내는 이유는 문장의 길이에 따라 그 손실의 규모 차이에 의한 문제를 방지하기 위함이다
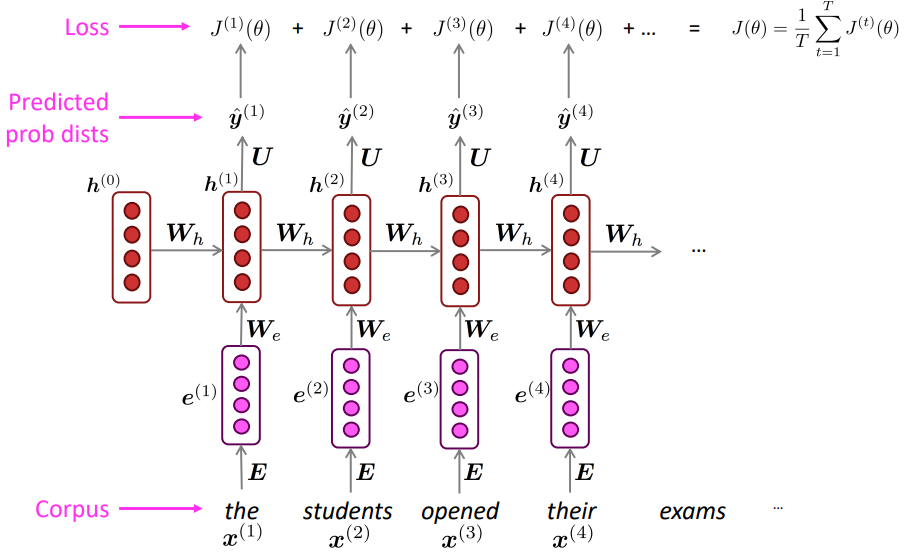
위의 예시에서 각각 timestep의 손실 함수는 다음과 같다
$$J^{(1)}(\theta) = -logP(\hat{y}^{(1)}_{student})$$
$$J^{(2)}(\theta) = -logP(\hat{y}^{(2)}_{opened})$$
$$J^{(3)}(\theta) = -logP(\hat{y}^{(3)}_{thier})$$
$$J^{(4)}(\theta) = -logP(\hat{y}^{(4)}_{exams})$$
연속적인 예측을 수행할 경우 한 timestep에서 잘못 예측하였을 때 다음 timestep에 계속해서 잘못된 추론이 입력으로 들어갈 수 있다. 그렇기 때문에 각각의 입력은 ground truth 값으로 넣어주어 매 timestep마다 조건이 제대로 주어졌을 때를 기준으로 학습할 수 있도록 한다. 이를 teacher forcing이라고 한다.
학습에 있어 추가적으로 전체 말뭉치를 학습하는 것은 너무 연산량이 많다. 그래서 일반적으로 문서 또는 문장 단위로 나누어서 학습을 진행한다. 우리가 SGD(stochastic gradient descent)에서 데이터의 일부만 이용해서 기울기를 update 했었기 때문에 실제로 문장 혹은 여러 문장 단위로 기울기를 계산하고 update 한다.
○ RNN 매개 변수의 학습
그럼 RNN의 매개 변수를 업데이트하기 위해서는 어떻게 해야할까?
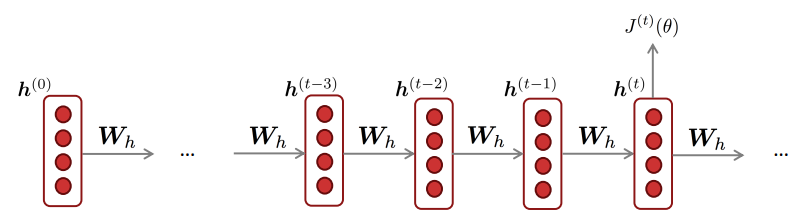
Q: 반복되는 가중치 $W_{h}$에 대해 손실 함수 $J^{(t)}(\theta)$를 미분하면 어떻게 될까?
A: $ \LARGE {\frac{\partial J^{(t)}}{\partial W_{h}} = \sum_{i=1}^{t}\frac{\partial J^{(t)}}{\partial W_{h}}|_{(i)}} $
해당 미분값을 구하기위해 다변수함수의 연쇄법칙을 적용해보자
lecture 3에서 배운 것과 같이 각각의 편미분을 수행한 다음 더해주면 된다.
$$ \frac{d}{dt} f(\textcolor{blue}{x}(t), \textcolor{red}{y}(t))= \frac{\partial f}{\partial \textcolor{blue}{x}} \frac{d\textcolor{blue}{x}}{dt} + \frac{\partial f}{\partial \textcolor{red}{y}} \frac{d\textcolor{red}{y}}{dt} $$
이 수식을 이용하면 아래와 같이 모든 timestep에 대한 $W_{h}$에 대해 다음과 같이 정리가 된다.

이 때, 각 timestep에서 $W_{h}$는 같은 값을 사용하므로 1이 된다.

위와 같이 각 timestep에 대한 기울기를 최종 손실 함수로부터 구하여 역전파해 나간다. 이 때 timestep에 따라 역전파 해 시퀀스의 처음까지 간다고 해서 BPTT(backpropatation through time)이라고 한다. 가끔 시퀀스가 너무 길면 연산속도가 너무 느려지기 때문에 update하는 최대 timestep길이에 제한을 두는 방법을 truncated BPTT라고 한다.
○ RNN 언어 모델의 문서 생성

위의 예시처럼 단어를 주고 시작할 수도 있고 아무것도 없이 시작하려면 special token을 입력으로 준 다음 확률 분포로부터 단어를 샘플링한다. 이후 샘플링된 단어는 다음 timestep의 입력으로 들어가게되고 최종적으로 문장의 끝을 나타내는 special token이 나타나면 생성은 종료된다.
다음은 위의 방법을 이용한 예시이다
Source: https://medium.com/deep-writing/harry-potter-written-by-artificial-intelligence-8a9431803da6
Harry Potter: Written by Artificial Intelligence
I trained an LSTM Recurrent Neural Network (a deep learning algorithm) on the first four Harry Potter books. I then asked it to produce a…
medium.com

Source: https://gist.github.com/nylki/1efbaa36635956d35bcc
char-rnn cooking recipes
char-rnn cooking recipes. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com

여전히 말은 안되지만 n-gram언어 모델보다 말이 되며, 문법적으로 그럴싸함은 물론 필체나 형식도 비슷하다.
○ 언어 모델 평가
언어 모델의 대표적인 평가지표는 perplexity이다
$$\texttt{perplexity}=\prod_{t=1}^{T}(\frac{1}{P_{LM}(x^{(t+1)}|x^{(t)},...,x^{(1)})})^{1/T}$$
수식의 전체적인 의미는 언어 모델을 통한 말뭉치 확률의 역수를 총 단어수인 $1/T$로 normalize 해준 것이다.
이는 cross-entropy 손실 $J(\theta)$에 지수를 취해준 것과 같다.
$$=\prod_{t=1}^{T}(\frac{1}{\hat{y}^{(t)}_{x_{t+1}}})^{1/T}=exp(\frac{1}{T}\sum^{T}_{t=1}-log\hat{y}^{(t)}_{x_{t+1}})=exp(J(\theta))$$
원래는 Fred Jelinek이 처음에 아래의 수식으로 설명하였으나 아무도 이해하지 못해서 위와 같은 직관적인 설명이 더 쉽게 와닿게 되었다. 어떻게 직관적이냐면 언어 모델의 perplexity가 53일 경우 특정 다음 단어를 예측할 때 1/53로 맞춘다는 얘기이다. 따라서 perplexity는 작을수록 좋다.
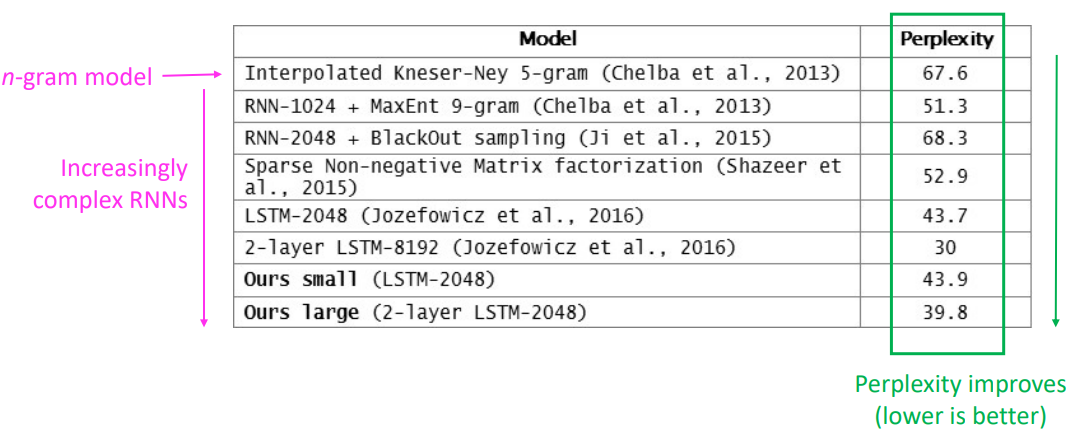
n-gram 모델부터 RNN계열 모델로 오면서 perplexity는 2016년 30까지 감소시킬 수 있었다. 다만 perplexity는 일정 이하로 감소시키기 힘들다. 다음 예시를 보면 이해하기 편하다.
Sue gave the man a nappkin. He said thank _____.
위의 문장에서 빈칸에 올 말은 you로 자명하다. 하지만 다음과 같은 문장의 경우는 어떨까
He looked out the window and saw _______.
이러한 경우 다양한 단어가 올 수 있기 때문에 perplexity는 20 이하로 내려가기 힘들다.
왜 우리는 언어 모델을 중요하게 생각할까? 언어 모델은 다음 단어를 예측하는 작업을 수행하기에 언어를 얼마나 이해하고 있는지 판단할 수 있는 작업이다. 따라서 언어 모델을 많은 NLP 작업의 하부 구성요소로 볼 수 있다.
RNN의 다른 용도
○ 시퀀스 태깅(Sequence tagging)
시퀀스 태깅의 예시로는 품사 태깅(part-of-speech tagging), 개체명 인식(NER, named entity recognition) 등이 있다.

○ 감성 분류(Sentiment classification)
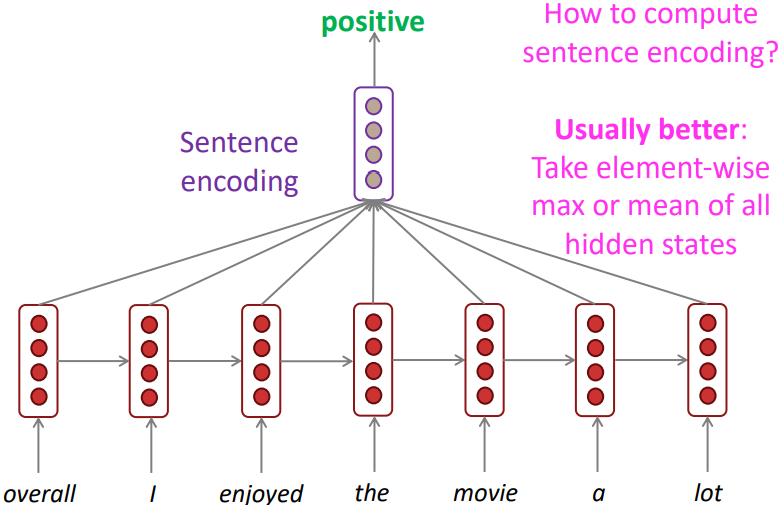
RNN은 또한 문장 혹은 문서의 감성 분류에도 이용된다. 이 때 최종 분류기를 RNN위에 추가적으로 올려서 sentence encoding을 수행하게 되는데, 이를 수행하는 가장 기본적인 방법은 문장의 마지막 단어의 hidden state를 입력으로 넣어주는 것이다. 이 것이 가능한 이유는 문장의 마지막 단어의 hidden state에도 문장 내 선행된 hidden state 정보가 재귀적으로 따라오기 때문이다.

일반적으로 더 좋은 성능을 내기 위한 방법으로는 문장 내 모든 hidden state의 출력값을 sentence encoding의 입력으로 넣어주는 것이다. 이 때 각 요소의 최대값 혹은 평균값을 취해서 입력해준다. 이 방법이 더 효과적인 이유는 모든 timestep에 대해 symmetric한 출력을 보여주기 때문이다.
○ 언어 인코더 모듈(Language encoder module)
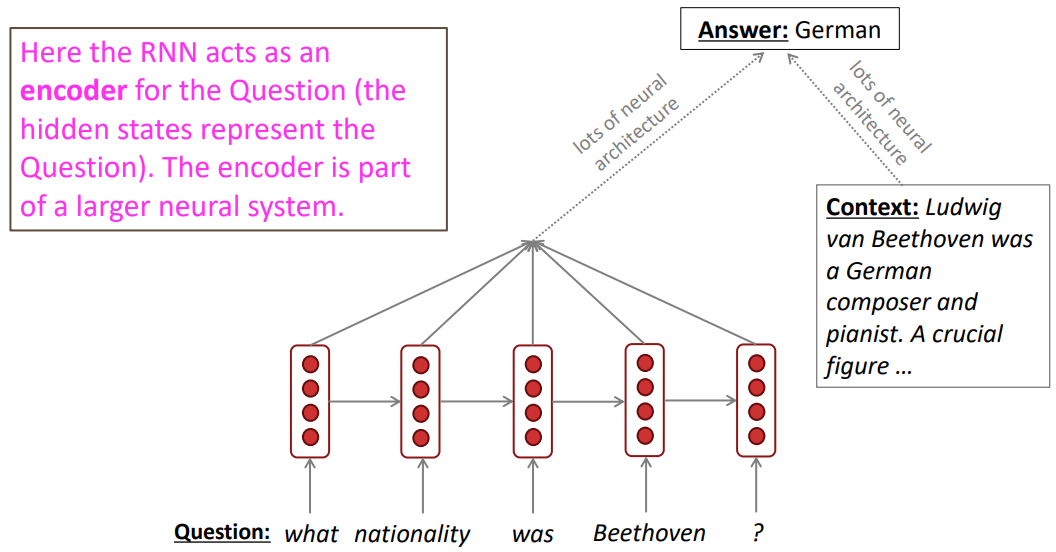
해당 예시로는 질의응답(Question answering), 기계 번역(Machine translation) 등이 있다.
질의응답의 경우 RNN이 질문을 인코딩한 후 다른 신경망 아키텍쳐를 통해 정답을 추론하고, 정답을 추론하기 위해 문맥을 학습하는 또다른 신경망 아키텍처도 구축한다.
○ 텍스트 생성
해당 예시로 음성 인식(Speech recognition), 기계 번역(Machine translation), 요약(Summarization) 등이 있다.
음성 인식의 경우 음성 데이터를 조절(conditioning)하여 RNN에 입력으로 넣어주어 해당 음성에 맞는 단어를 출력으로 받는다.

기울기 소실과 폭주 문제(Gradient Vanishing and Exploding)
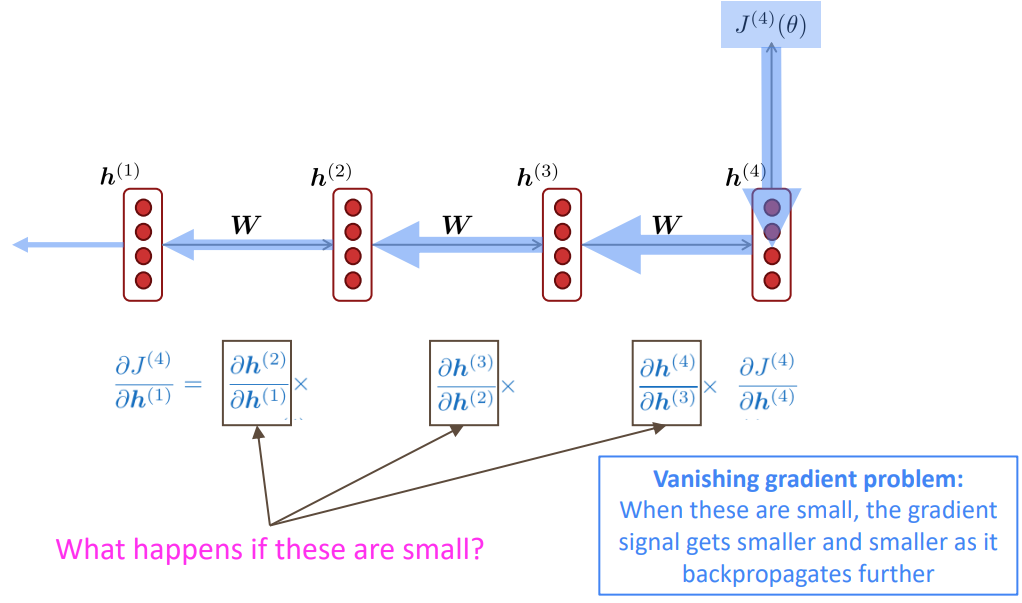
다음 그림을 보자 만약 timestep이 출력에서 4떨어진 곳의 가중치를 업데이트하려면 각 timestep의 기울기의 곱으로 나타낼 수 있다. 이 때 각각의 기울기 값이 작다면 멀리 떨어진 곳의 기울기는 점점 작아질 것이다.
○ 기울기 소실 선형 경우 (Vanishing gradient in linear case)
Hidden state는 다음과 같은 수식으로 정의된다.
$$h^{(t)}=\sigma(W_{h}h^{(t-1)}+W_{x}x^{(t)}+b_{1})$$
이 때 $\sigma$를 항등함수라고 가정하면 ($\sigma(x)=x$), 연쇄 법칙(chain rule)의 일부인 t를 t-1로 미분한 값은 다음과 같다.
$$\frac{\partial h^{(t)}}{\partial h^{(t-1)}} = diag(\sigma '(W_{h}h^{(t-1)}+W_{x}x^{(t)}+b_{1}))W_{h} = IW_{h} = W_{h}$$
timestep $i$에서의 손실의 기울기 $J^{(i)}(\theta)$를 $j$라는 이전 timestep의 hidden state $h^{(j)}$에 반영하려면
$l=i-j$라 할 때,
$$\begin{align}
\frac{\partial J^{(i)}(\theta)}{\partial h^{(j)}}= \frac{\partial J^{(i)}(\theta)}{\partial h^{(i)}}\prod_{j< t\leq i}\frac{\partial h^{(t)}}{\partial h^{(t-1)}} \\
=\frac{\partial J^{(i)}(\theta)}{\partial h^{(i)}}\prod_{j< t\leq i}W_{h}=\frac{\partial J^{(i)}(\theta)}{\partial h^{(i)}}W^{l}_{h}
\end{align}$$
즉, 업데이트할 기울기는 가중치를 $l$번 곱한 양이 포함되며, 만약 $W_{h}$가 작을 경우 $l$의 크기에 비례해 지수적으로 문제가 된다.
$W_{h}$의 eigenvalue가 1보다 작다고 가정해보자
$$ \lambda_{1},\lambda_{2},...,\lambda_{n}<1$$
$$ q_{1},q_{2},...,q_{n} : \texttt{eigenvectors}$$
$$\frac{\partial J^{(i)}(\theta)}{\partial h^{(i)}} = \sum_{i=1}^{n}c_{i}\lambda^{l}_{i}q_{i}\approx 0$$
위와 $l$의 값이 큰 경우 전체가 0으로 근사하게 된다
만약 $\sigma$가 선형이 아닌 경우라도 $\lambda^{l}_{i} <\gamma$의 증명만 추가되고 그 외는 동일하다
Source: “On the difficulty of training recurrent neural networks”, Pascanu et al, 2013. http://proceedings.mlr.press/v28/pascanu13.pdf
(and supplemental materials), at http://proceedings.mlr.press/v28/pascanu13-supp.pdf
○ 기울기 소실이 문제가 되는 이유
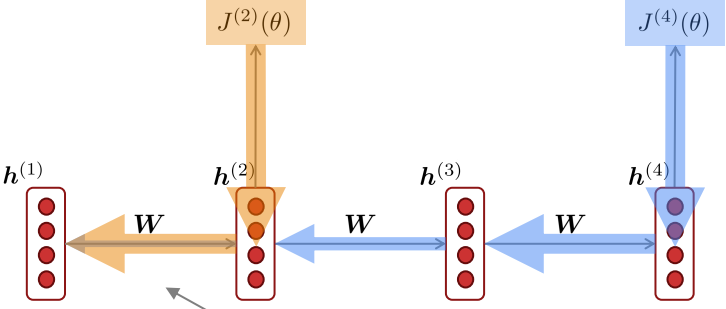
기울기 소실이 문제가 되는 이유는 timestep이 멀리 떨어진 경우 기울기가 거의 소실되어 인접한 기울기만 매개 변수 업데이트에 반영되기 때문이다.
이 영향은 아래의 예시에서 문제가 된다.
LM task: When she tried to print her tickets, she found that the printer was out of toner.
She went to the stationery store to buy more toner. It was very overpriced. After
installing the toner into the printer, she finally printed her ________.
사람이라면 어렵지 않게 빈칸에 들어갈 말이 "tickets"인 것을 파악할 수 있다. 반면에 RNN 언어 모델의 경우 기울기가 작을 경우, 이 관계성을 학습할 수 없다. 일반적으로 RNN의 경우 7번 timestep이상의 정보는 잊어버린다.
○ 기울기 폭주(Gradient exploding)와 기울기 클리핑(Clipping)
반대로 기울기가 폭주하는 경우를 생각해보자
$\theta^{new} = \theta^{old} - \alpha\bigtriangledown_{\theta}J(\theta)$
기울기의 값이 너무 커지게 될경우 매개변수가 너무 가파르게 업데이트 되어 이상하거나 나쁜 분포를 갖게 된다. 최악의 경우 그 결과값이 Inf, NaN값을 갖게 된다.
이를 방지하기 위해서 기울기 클리핑(clipping)이라는 방법이 있다.
단순하게 기울기에 theshold를 정해주어 SGD 업데이트 전에 그 크기를 조정하는 것이다

결과적으로 같은 방향으로 그 값을 작게 업데이트하는 것으로 기울기 폭주문제를 손쉽게 해결할 수 있다.
○ Long Short-Term Memory RNNs (LSTMs)
제일 문제가 되는 것은 많은 timestep을 거치면 정보가 소실된다는 것이다. 바닐라 RNN에서 hidden state는 다음과 같이 $h^{(t)}=\sigma(W_{h}h^{(t-1)}+W_{x}x^{(t)}+b_{1})$ 기술되는데, 이 때 장기와 단기 메모리를 따로 가져간다면 어떨까?
1997년 Hochreiter and Schmidhuber가 제안한 RNN기반의 LSTM이 기울기 소실 문제 해결을 위해 제안되었다.
구성은 step t에 대해서 hidden state $h^{(t)}$ 와 cell state $c{(t)}$로 되어있다.
- 벡터의 길이는 n으로 같다
- cell 이 장기(long-term) 정보를 보관한다
- LSTM은 cell에 정보를 읽고, 지우고, 쓰기가 가능하다
: 정보의 읽기, 지우기, 쓰기는 gates로 조작된다- gates 역시 길이는 n
- open(1), closed(0)로 각 timestep에 대해 정보를 조작
- dynamic gates로 현재 시점의 문맥에 따라 조정된다.
$x^{(t)}$ 입력에 대해 LSTM은 hidden state $h^{(t)}$ 와 cell state $c{(t)}$를 각 timestep t에 대해 계산한다
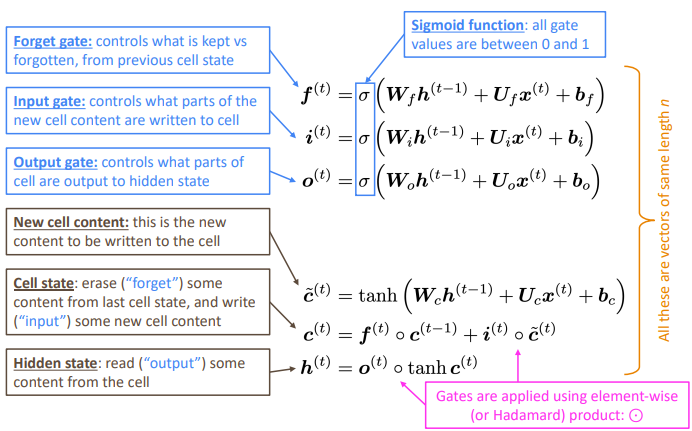
- LSTM은 2개의 hidden vector를 사용한다.
- hidden state: output gate를 통해 현재 cell 정보로부터 일부를 추출.
- cell state: long-term 정보 저장. forget gate로부터 이전 cell의 정보를 일부 지우고, input gate로 부터 현재 정보 일부를 추가하여 생성.
- 3개의 gate를 사용하여 매 time step의 cell state와 hidden state, input에서 취할 정보의 양을 결정한다.
- forget gate: 이전 timestep의 cell state $c^{(t-1)}$에서 어느 정도의 정보를 가져갈 것인지 결정
- input gate: 현재 timestep의 입력$x^{(t)}$과 이전 timestep의 hidden state $h^{(t-1)}$를 통해 생성된 현재 cell 정보에서 cell state로 가져갈 정보의 양 결정
- output gate: 생성된 현재 cell state $c^{(t)}$에서 hidden state로 사용할 비율 결정
당연한 얘기지만 LSTM이 RNN보다 무조건 좋으며 gate도 학습된다 LSTM이 효과적인 비밀은 바로 +에 있다. 곱하기만 있다보면 결국 기울기 소실 문제는 해결될 수 없기 때문이다.

forget gate가 1일 경우 모든 정보가 보존되며, 기존 RNN에서는 7 timestep까지만 정보가 보존되었다면 LSTM을 이용하면 100 timestep까지 정보가 보존되었다. 그러나 LSTM이 기울기 소실/폭주가 없는 것은 아니다. 단순히 장기 의존 정보를 잘 학습할 수 있는 것 뿐이다.
○ LSTMs 사례
2013~2015 여러 실제 NLP task에서 성공을 거두었다. 2021년의 경우 transformer가 그 자리를 대체했다.
예를들어 WMT(a Machine Translation conference + competition)에서
WMT 2016: RNN 44번 레포트
WMT 2019: RNN 7번, tramsformer 105번 레포트
○ 기울기 소실/폭주 문제는 RNN만의 문제인가?
깊은 신경망의 경우 언제나 일어날 수 있는 문제이다. 이를 방지하기 위해서는 직접적인 층간의 연결이 중요하다.
가장 일반적으로 이를 해결하기 위해서는 단순히 더하는 방법을 이용하는 것으로 대표적으로 ResNet이 있다
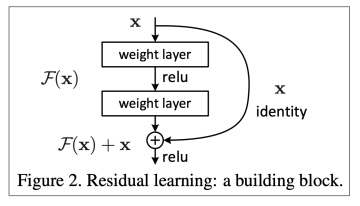
다른 방법으로 DenseNet으로 역시 깊은 층을 직접적으로 연결하는 방식을 취한다.

LSTM에서 영감을 받은 HighwayNet의 경우 resnet처럼 단순히 더하는게 아니라 추가적인 dynamic gate를 이용하여 연결한다.

기울기 소실/폭주문제는 RNN에 특히 취약하다 하나의 가중치를 반복적으로 사용하기 때문이다.
○ 양방향(Bidirectional) RNN
단어는 문맥따라 다른 의미를 갖는데 왼쪽정보만 가져온다면 문제가 된다.
다음 예시의 경우 terribly만 보면 부정적인 단어지만 exciting이 이후에 나오게 되면 긍정적인 단어가 된다. 즉 exciting을 보기 전까지 해당 감성 분류는 계속 부정적인 문제가 발생한다.
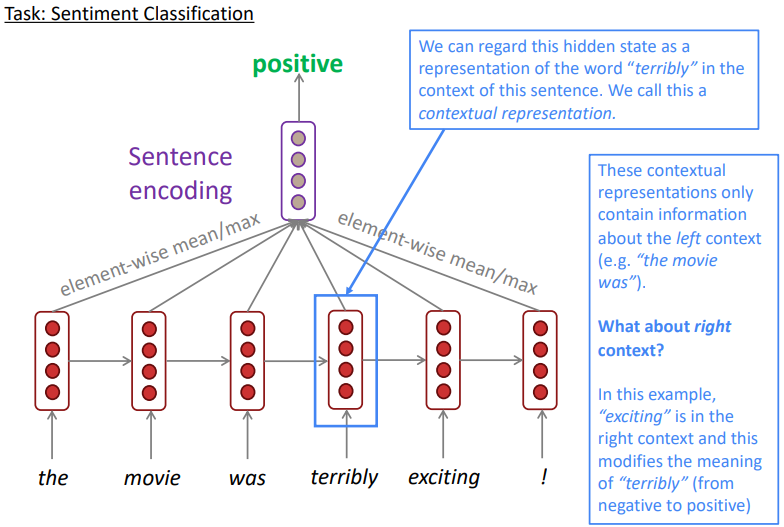
이를 보완하기 위한것이 bidirectional RNNs이고 아래와 같이 문장을 거꾸로 입력해준 값을 concatenate하여 hidden state를 생성하게되면 terribly는 양방향의 문맥을 모두 반영한 representation을 갖게 된다.

감성분류를 위해서는 concatenated된 각 timestep의 hiddens state를 모두 넣어줄 필요없이 문장의 처음 (the와 !)의 hidden state만 이용하는 것만으로도 충분한 성능의 감성 분류가 가능하게 되었다. 수식적으로 표현하면 단순하게 아래와 같이 표현된다.

하지만 이는 전체 입력을 한번에 넣어주기 때문에 언어 모델에 적용은 불가능하다. 다른 말로하면 전체 시퀀스를 가지고 있다면 무조건 다 넣어주는 것이 훨씬 강력하다. 대표적으로 BERT는 양방향을 인식할 수 있도록 설계되었다.
Reference)
Slide: cs224n-2021-lecture06-fancy-rnn.pdf (stanford.edu)
Note: CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part V Language Models, RNN, GRU and LSTM (stanford.edu)
Video: Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 6 - Simple and LSTM RNNs - YouTube
'교육 > CS224N winter 2021' 카테고리의 다른 글
| Lec 8) Attention (0) | 2022.06.16 |
|---|---|
| Lec 7) Translation, Seq2Seq (0) | 2022.06.14 |
| Lec5) Language Models and RNNs (0) | 2022.05.11 |
| Lec 4) Dependency Parsing (0) | 2022.04.29 |
| Lec3) Backprop and Neural Networks (0) | 2022.04.22 |



