기계 번역 (Machine Translation)
○ Section 1: Pre-Neural Machine Translation
- 1950`s
기계 번역(Machine Translation, MT)랑 하나의 언어 x(Source language)를 또 다른 언어 y로(Targent language)로 번역하는 작업이다.
x: L'homme est né libre, et partout il est dans les fers
▽
y: Man is born free, but everywhere he is in chains
개발 배경은 1950년도 냉전 시대에 미국과 소련이 서로의 통신 혹은 기밀 문서를 빠르게 번역하여 정보를 얻기 위함입니다. 이 당시는 주로 rule-based 방식으로 번역이 되었으며, 이 이후로 지금까지도 DARPA가 큰 규모의 funding을 진행하고 있습니다.
- 1990~2010s : 통계적 기계 번역(Statistical machine translation, SMT)
핵심 아이디어: 데이터로 부터 확률 모델을 학습
불어($x$)를 영어($y$)로 번역할 경우,
$$\texttt{argmax}_{y}P(y|x)$$
Bayes Rule을 이용해서 위 수식을 두 개의 component로 나눌 수 있다.
$$\texttt{argmax}_{y}{\color{Blue} P(x|y)}{\color{DarkGreen} P(y)}$$
${\color{Blue} P(x|y)}$ : Translation Model, 단어나 구문이 의미가 어떻게 번역되어야하는지 병렬 데이터로부터 학습
${\color{DarkGreen} P(y)}$ : Language Model, target language로 번역될 때 문장의 유창함(fluency)을 학습
○ SMT에서의 정렬 (alignment) 학습
Q) ${\color{Blue} P(x|y)}$를 어떻게 학습할 수 있을까?
우선 대규모의 병렬 데이터가 필요
Q) 병렬 데이터로부터 어떻게 ${\color{Blue} P(x|y)}$를 학습할 수 있을까?
병렬 데이터 간 정렬이 필요하다. 즉, source 문장 x와 target 문장 y 간 단어 수준에서 상응하는 것이 정렬 (alignment, a)이다.
이를 통해 다음을 구하면 된다 $P(x,a|y)$
모델은 $P(x,a|y)$를 다양한 요인들의 조합으로 학습할 수 있다.
정렬 a는 잠재된 변수로 병렬된 데이터 내에 명시되어 있지 않다.
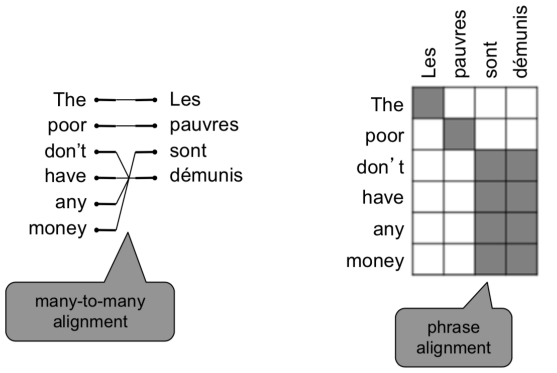
○ 정렬 (alignment) 이란?
정렬이랑 문장 쌍에서 특정 단어 간의 대응을 얘기한다.
하지만 언어 간의 특성 차이 때문에 대응이 잘 되지 않느 경우가 있다.
- 아래의 Le처럼 대응이 없는 경우 "spurious word"라고 한다.

- 정렬은 다대일 대응이 될 수도 있다. (many-to-one)

- 정렬은 일대다 대응이 될 수도 있다. (one-to-many), 이 경우 하나에 해당하는 단어는 "fertile word"라고 한다.

- 정렬은 구문 수준에서 다대다 대응이 될 수도 있다.
○ Decoding for SMT
$$\texttt{argmax}_{y}{\color{Blue} P(x|y)}{\color{DarkGreen} P(y)}$$
다시 해당 식으로 돌아와서 argmax값을 어떻게 구할 수 있을까?
왜냐하면 모든 경우의 수를 전부 조합하는 것은 너무 계산량을 많이 요구한다.
그래서 모델 내에 강하게 독립적이라는 가정을 적용하고, 동적 프로그래밍을 이용하여 전역 최적해를 구한다. (e.g. Viterbi algorithm)
이를 decoding이라고 한다

해당 decoding 방식의 예를 들면 위 그림에서 두 번째 독일 단어는 동사인데 영어에서는 올 수 없는 위치이며 재배열이 필요하다. 따라서 각 단어들의 변역될 수 있는 영단어들을 나열하여 조합해나간다. 그래서 시작할 때 첫 단어가 he가 가장 가능성 있으므로 he를 선택하게 되고 위의 박스는 검게 칠해진 것이 사용된 독일 단어의 위치를 표기해준다. 이렇게 단어의 조합을 살펴보면서 가능성이 낮은 애들을 가지치기 해나가 가장 적절한 문장을 선택하게된다.
○ 1990~2010s : 통계적 기계 번역(Statistical machine translation, SMT)
SMT는 큰 연구 분야이며 최적의 시스템은 극도로 복잡하다.
시스템은 다양한 subcomponent들로 구성
많은 feature engineering이 필요
추가 리소스 편집 및 유지 관리 필요 (구문 대응 표 같은)
유지를 위해 human effort가 많이 들어간다
○ Section 2: Neural Machine Translation
○ 신경 기계 번역 (Neural Machine Translation, NMT)이란?
Neural Machine Translation(NMT)는 단일 end-to-end 신경망을 이용하여 기계 번역을 수행하는 방법으로 신경망 아키텍처는 sequence-to-sequence 모델 (이하 seq2seq)으로 불린다.
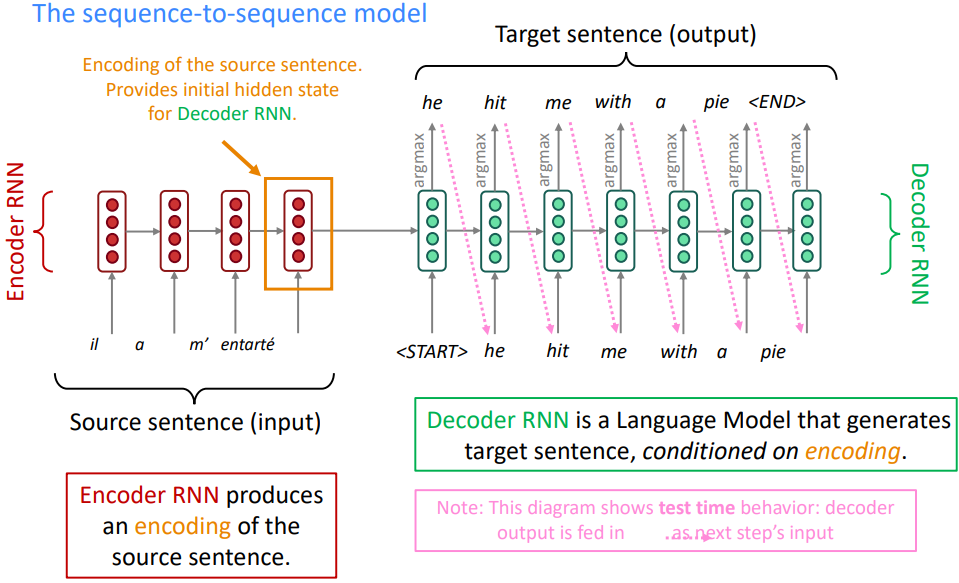
NMT의 경우 source 문장을 Encoder RNN에 넣어 생성된 hidden state를 Decoder RNN에 입력으로 넣어준다.
Decoder RNN의 경우 시작토큰 <START>와 함께 두 개의 입력을 받아서 가장 단어를 추론하고 그 단어를 또 다음 입력으로 넣어주어 문장을 생성한다.
seq2seq은 단순 MT에만 유용한 것이 아니라 다양한 곳에 유용하다
- 요약 (긴 텍스트 → 짧은 텍스트)
- 대화 (이전 대화 → 다음 대화)
- Parsing (입력 텍스트 → parsing 방법)
- Code 생성 (자연어 → code)
seq2seq은 조건부 언어 모델의 예로 언어모델인 이유는 decoder에서 target 문장의 다음 단어를 예측하고, 조건부인 이유는 source 문장에 조건부이기 때문이다.
$$P(y|x)=P(y_{1}|x)P(y_{2}|y_{1},x)...P(y_{T}|y_{1},...,y_{T-1},x)$$
NMT는 $P(y|x)$를 계산하며 source 문장 x와 target 문장읠 위해 생성된 단어들을 입력으로 받아서 확률을 계산한다.
그렇기 때문에 단순 언어모델 보다는 더 낮은 perplexity를 갖고 있다.
NMT 학습을 위해서는 무엇이 필요할까? 답은 큰 병렬 말뭉치(parallel corpus)를 구하는 것이다
○ 신경 기계 번역 시스템의 학습

학습은 end-to-end로 단일 시스템으로 취급되어 최적화됩니다.
시스템에서 예측한 단어와 실제 단어의 교차 엔트로피를 손실로서 구해 준 후에 teacher forcing으로 각 단어들에 대한 손실을 모두 구해준다. 그렇게 구한 모든 손실의 평균을 통해 역전파를 수행하는데 이 때 역전파는 decoder 뿐아니라 encoder의 매개변수까지 업데이트 해준다.
○ 다층 순환신경망 (Multi-layer RNNs)
RNN은 이미 하나의 차원에서 깊다. (여러 timestep에 대해 순환하기 때문)
여러 RNN을 적용하여 또 다른 차원에 대해 깊게 적용할 수 있으며 이것이 multi-layer RNN이다.
이는 더 복잡한 표현의 계산을 가능하게 해준다. 예를 들어 lower RNN은 단어와 구문같은 특징인 lower-level feature를 처리하고 higher RNN은 문맥과 같은 high-level feature를 연산한다.
Multi-layer RNNs은 stacked RNNs로도 불린다.
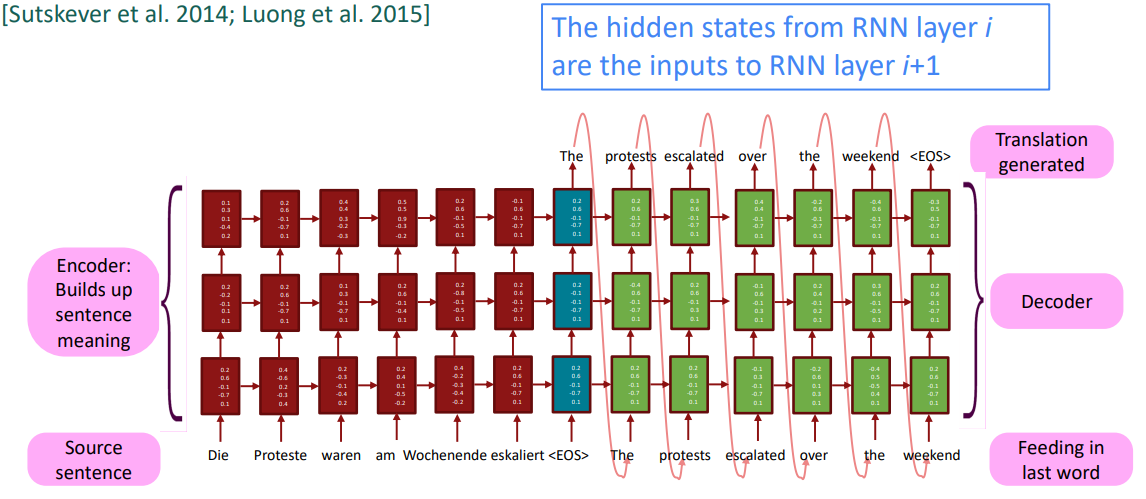
높은 성능을 보여주는 RNNs은 주로 multi-layer를 적용했다. 대표적으로 2017년 Britz et al.의 논문에서 NMT의경우 encoder는 2~4개의 층을 decoder는 4개의 층을 이용하는 것이 좋았다. 2개의 층을 쌓기만해도 하나보다 많은 성능 향상을 기대할 수 있으나 그 이상 쌓는 것은 효과가 미미하며 오히려 안 좋을 수도 있다. 따라서 skip-connections/dense-connections가 깊은 RNNs 학습에는 필수적이다.
이후에 배울 Transformer 기반의 신경망은 12~24개 층으로 훨씬 깊다.
○ Greedy decoding
위의 decoder에서 target 문장을 생성할 때 각각의 hidden state로부터 argmax로 가장 확률 높은 단어를 뽑는다. 이를 greedy decoding (각 단계에서 가장 확률이 높은 것을 취함)

그러나 한 스탭에서 단어를 잘못 추론했을 경우 되돌아갈 수 없다. 이 문제를 어떻게 해결할 수 있을까?
○ Exhaustive search decoding
$$P(y|x)
=P(y_{1}|x)P(y_{2}|y_{1},x)...P(y_{T}|y_{1},...,y_{T-1},x)
=\prod_{t=1}^{T}P(y_{T}|y_{1},...,y_{T-1},x)$$
이상적으로 우리는 위 수식값 즉 최대 확률 문장으로 가는 단어 y를 구하고 싶다.
결론적으로 우리는 모든 가능한 나열을 계산하면 된다.
즉, decoder의 각 단계 t에서 vocab 크기 $V^{t}$ 개의 가능한 모든 번역을 수행한다.
복잡도는 결국 $O(V^{t})$로 너무 큰 비용이 든다
○ Beam search decoding
핵심 아이디어: 각 step에서 k개의 가장 그럴듯한 부분 번역들을 계속 추적한다면 어떨까? (hypotheses 라고 부른다)
이 때 k가 beam size이다 (일반적으로 5~10)
hypotheses $y_{1},...,y_{t}$ 의 점수는 log 확률을 가진다.
$$score(y_{1},...,y_{t})=logP_{LM}(y_{1},...,y_{t}|x)=\sum_{i=1}^{t}logP_{LM}(y_{i}|y_{1},...,y_{i-1},x)$$
즉 모든 점수는 음수이고, 높을수록 좋다. 결과적으로 가장 높은 점수 k개를 각 단계에서 계속 추적한다.
이 방법은 최적의 해를 찾아주는 방법은 아니지만 exhaustive search 방법보다는 훨씬 효율적이다.
k=2 일때 예시를 보자
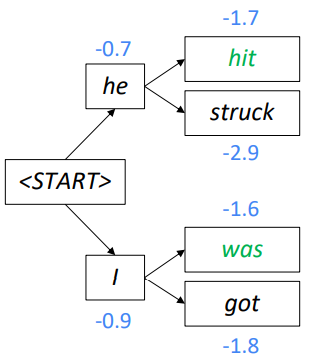
<START>로 시작해서 he와 I를 추론했고 그 이후 각각 2개씩 추가로 단어를 추론했다. 이 step에서 he hit (-1.7)과 I was (-1.6)이 가장 점수가 높기 때문에 이 두 부분 번역을 계속 추적한다.
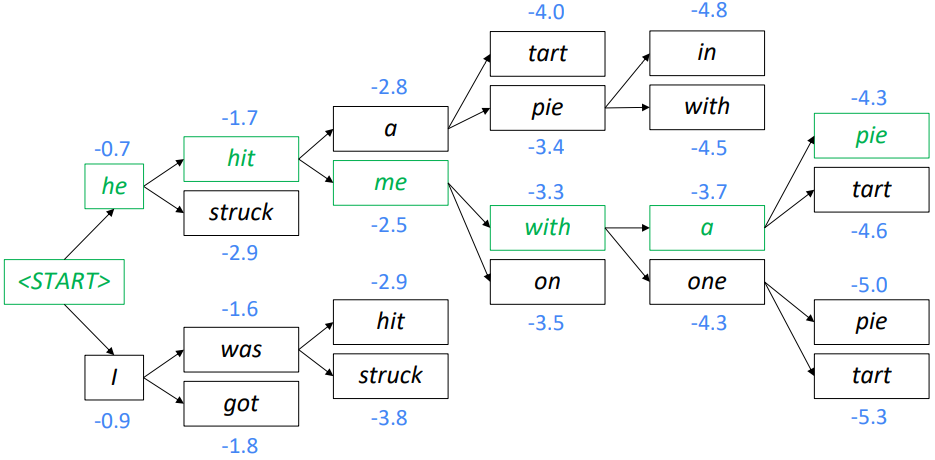
2개의 점수가 높은 문장을 계속 추적해 나가면 다음과 같이 he hit me with a pie라는 문장을 도출하게 된다.
중단 기준
greedy decoding에서 코드 중단 기준은 <END> 코튼이 생성될 때이다.
예) <START> he hit me with a pie <END>
그러나 beam search decoding에서는 다양한 hypotheses가 다양한 timestep에서 <END> 토큰을 생성할 것이다.
그래서 hypotheses가 <END>를 생성하면, 해당 hypothses는 생성이 완료된 것으로 간주한다.
해당 hypotheses는 따로 저장해두고 나머지 hypotheses의 탐색을 지속한다.
결과적으로 특정 timestep T에 도달할 때까지 지속하거나 최소 n개의 완성된 hypotheses가 나올 때가지 탐색을 지속한다.
종료
완료된 hypotheses 목록을 가지고 누가 가장 높은 점수를 가지는지 비교를 한다.
$$score(y_{1},...,y_{t})=logP_{LM}(y_{1},...,y_{t}|x)=\sum_{i=1}^{t}logP_{LM}(y_{i}|y_{1},...,y_{i-1},x)$$
그러나 수식에서 확인할 수 있는거처럼 긴 문장이 작은 점수를 가질 수 밖에 없다.
따라서 단어수로 일반화를 시켜준 후 가장 높은 점수의 문장을 선택한다.
$$\frac{1}{t}\sum_{i=1}^{t}logP_{LM}(y_{i}|y_{1},...,y_{i-1},x)$$
○ NMT의 장단점
장점
- 더 나은 성능
- 하나의 신경망으로 최적화된 end-to-end: subcomponent를 개별로 최적화 시킬 필요 없음
- human engineering effort가 적게 소요됨
단점
- debug가 어렵다
- 조절하기 힘들다
○ 기계번역 평가 방법
BLEU (Bilingual Evaluation Understudy) 는 기계번역된 문장과 사람이 번역한 문장을 비교하여 유사도 점수를 구하는 것이다.
- n-gram 정확도 (일반적으로 1,2,3, 그리고 4-grams)
- 추가적으로 짧은 문장에 대한 패널티 부여
BLEU score는 효율적이지만 불완전하다. 왜냐하면 문장 번역은 다양한 방법으로 가능하며 위 방식으로는 단순 단어만 비교하는 것이기 때문에 좋은 번역이여도 낮은 BLEU score를 갈질 수 있다.
○ MT progress over time
[Edinburgh En-De WMT newstest2013 Cased BLEU; NMT 2015 from U. Montréal; NMT 2019 FAIR on newstest2019]
NMT가 나온지 2014년 이후 발전 속도는 SMT와 비교하여 비약적으로 빠르다.

NMT는 2014년 이후 주력 방법으로 자리 잡았으며 2016년 구글 번역도 SMT에서 NMT로 전환되었다. 그리고 2018년 모든 번역을 하는 기업들을 NMT를 사용한다.

결과적으로 NMT는 SMT에서 많은 연구원들이 수년간 만든 성능을 작은 집단이 몇 달만에 뒤집는 성과를 보여주었다.
○ MT는 해결되었나?
아니다!
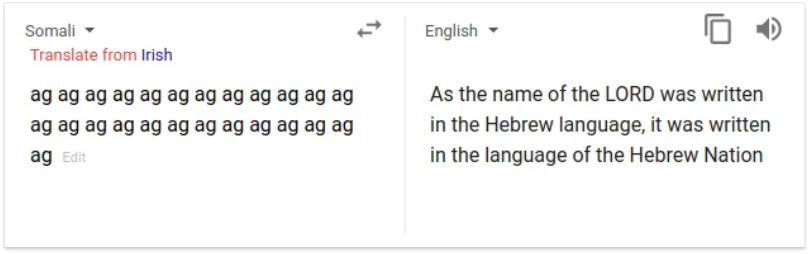
- Out-of-vocabulary words
- 학습-테스트 간 도메인 불일치
- 긴 텍스트의 문맥 유지
- 소수 언어
- 문장 의미를 정확하게 포착하지 못함
- 대명사(또는 제로 대명사) resolution 오류
- 형태학적 일치 오류
그 외의 구체적인 사례를 보면 다음과 같다
일반 상식

학습 데이터의 편견
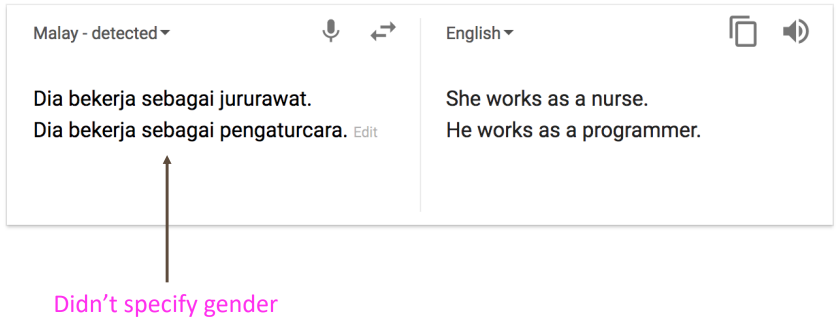
해석 불가능 시스템인 경우의 이상행동
○ NMT research continues
NMT는 NLP 딥 러닝의 주요 과제이다.
• NMT 연구는 최근 NLP 딥 러닝의 많은 혁신을 개척
• 2021년: NMT 연구는 계속 확장
연구자들은 방금 소개한 시스템 바닐라 seq2seq NMT의 많은, 많은 개선을 발견했다.
하지만 이제 새로운 바닐라처럼 필수적인 한 가지 개선점에 대해 다음 글에 소개하겠다.
ATTENTION
Reference)
Slide: cs224n-2021-lecture07-nmt.pdf (stanford.edu)
Note: CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part V Language Models, RNN, GRU and LSTM (stanford.edu)
Video: Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 7 - Translation, Seq2Seq, Attention - YouTube
'교육 > CS224N winter 2021' 카테고리의 다른 글
| Lec 9) Self-Attention & Transformers (0) | 2022.06.16 |
|---|---|
| Lec 8) Attention (0) | 2022.06.16 |
| Lec 6) Simple and LSTM RNNs (0) | 2022.05.18 |
| Lec5) Language Models and RNNs (0) | 2022.05.11 |
| Lec 4) Dependency Parsing (0) | 2022.04.29 |



