이전 강의: https://enjoythehobby.tistory.com/entry/Lec1-Word-Vectors
Lec1) Word Vectors
Denotational semantics(표시적 의미론) ○ 텍스트를 분석을 위해 단어의 뜻을 어떻게 표현(represent)할 것인가? signifier (symbol) ↔ signified (idea or thing) 표시론적 의미론에서 특정 기호(symbol)에 해..
enjoythehobby.tistory.com
○ Word2vec 복습
- 임의의 단어 벡터로 시작
- 주어진 중심단어에 대한 주변 단어 확률(P(o|c)P(o|c)) 예측을 수행
- 전체 말뭉치(corpus)의 각 단어에 대해 반복수행
P(o|c)=exp(uTovc)∑w∈Vexp(uTwvc)P(o|c)=exp(uTovc)∑w∈Vexp(uTwvc)

- 학습(Learning) : 예측이 좋아지는 방향으로 단어 벡터를 update
- 이것만으로 단어공간(wordspace)에서 단어 간 유사도와 의미의 방향을 잘 정의한다
○ Word2vec 매개변수 와 계산
word2vec의 경우 문장에서의 단어 순서에 상관없이 항상 같은 확률을 예측한다. ▶ "Bag of words" 모델
문맥에서 중심 단어에 대한 주변 단어 발생 확률에 대해 높은 확률을 부여하고자 한다. (적게 발생하는 빈도에 대해서도)
▶ 이를 위해서는 고차원 단어공간에서 서로 가깝게 배치해야 한다. (내적 값이 커야하므로 당연하다)
최적화(Optimization): 경사하강법(Gradient Descent)
○ 좋은 단어 벡터는 어떻게 학습하는가?
지난 시간에 손실 함수 J(θ)J(θ)의 값을 최소화하기 위해 미분하는 것을 살펴봤습니다. 여기서는 미분 이후의 작업에대해 기술합니다.
경사하강법(Gradient Descent): 0에 가까운 임의의 벡터로 시작(Initialize)하여 J(θ)J(θ)에서 θθ를 반복적(Iterative)으로 변화를 주어 최솟값에 근접하게 합니다.
이 때 현재 J(θ)J(θ)의 미분값이 0에 가까워지는 방향으로 θθ에 적절하게 작은 변화(step)를 줍니다.
- 변화량이 작을 경우: local minima에 수렴할 수 있으며 최적화에 시간이 오래 걸린다
- 변화량이 클 경우: 아래 그림처럼 큰 변화량에서는 최적화가 힘들고 값이 발산(Diverge)할 수 있다.
미분값(▽θJ(θ)▽θJ(θ))을 반영한 매개변수 update 방법은 아래와 같다.
θnew=θold−α▽θJ(θ)θnew=θold−α▽θJ(θ)
*여기서 αα는 step size 또는 학습률(learning rate)이라고 한다.
while True:
theta_grad = evaluate_gradient(J,corpus,theta)
theta = theta - alpha * theta_grad그러나 이 방식은 전체 말뭉치(corpus)에 대해 수행되므로 이는 너무 비용이 많이 들어 실제 사용되지 않는다.
확률적 경사하강법(Stochastic Gradient Descent, SGD): 일부 window에 대해 한개 혹은 작은 배치(batch)에 대해 매개변수를 update한다.
while True:
window = sample_window(corpus)
theta_grad = evaluate_gradient(J,window,theta)
theta = theta - alpha * theta_grad이 방식을 통해 적은 연산량으로 빠르게 손실 함수를 최적화 시킬 수 있으며, 학습 과정이 진폭이 크고 불안정해 보이지만 global minima를 찾는 성능면에서는 더 우수할 수 있다.
특정 window에 대해 SGD를 수행할 경우 중심단어를 포함하여 2×window+12×window+1개의 단어에 대해서만 매개변수를 update하게며 이는 전체 말뭉치 크기에 비해 굉장히 좁은 영역입니다.
* 실제 deep learning 패키지에서 단어는 지금까지 설명과 달리 열이 아니라 행에 위치한다. 따라서 해당 단어의 행을 U와 V 행렬에대해 update해주면 된다.
○ Word2vec algorithm family: More details
왜 벡터를 중심 단어와 문맥 단어 두 개 사용하는 이유: 쉬운 최적화, 마지막에 둘을 평균내어 사용
* 단어 하나 당 하나의 벡터를 사용할 수 있고 성능도 약간 좋지만 동일 단어가 중심 단어와 문맥 단어에 발생했을 때 algorithm 구현이 복잡해진다.
- Skip-grams(SG)
중심 단어로부터 문맥 단어를 예측 (지금까지 설명에서 예시로 사용) - Continuous Bag of Words(CBOW)
문맥 단어로부터 중심단어를 예측
○ 효율적인 학습을 위해
지금까지 naive softmax(simple, expensive)를 사용하였지만 네거티브 샘플링(Negative sampling, NS)을 word2vec 저자인 Mikolov는 추천한다
naive softmax가 비효율적인 이유는 분모(∑w∈Vexp(uTwvc)∑w∈Vexp(uTwvc))에서 모든 단어에 대해 내적을 해주기 때문이다. 그래서 이진 로지스틱 회귀(binary logistic regression)을 true pair(중심 단어와 window 내 문맥 단어) 대 noise pair(중심 단어와 임의의 단어)에 수행한다.
다음 목적 함수를 최대화 하는 방향으로 최적화를 진행한다.
Jt(θ)=logσ(uTovc)+k∑i=1Ej∼P(w)[logσ(−uTjvc)]
문맥 단어와 중심 단어의 확률을 최대화하기 위해 좌항은 커져야 하고, 노이즈 단어와 중심 단어의 확률을 최소화해야 한다. 여기서 우항 시그모이드 함수 안에 − 를 취해주어 양항이 커지는 방향으로 함수를 조정한다.
이제 전체에 또 −를 취해주고 보기 쉽게 만들면 아래와 같다.
Jneg−sample(uo,vc,U)=−logσ(uTovc)−∑k∈Ksampledindices[logσ(−uTkvc)]
상기 식에서 sampling할 때, P(w)=U(w)3/4/Z 수식을 이용하여 뽑는다. 여기서 U(w)는 unigram distribution(단어 빈도), Z는 단어수이다. 이를 통해 적게 등장하는 단어가 어느 정도 sampling될 수 있도록 보정할 수 있다.
○ Co-occurrence 갯수를 직접 센다면?
함께 나타나는 경우 word2vec과 유사하게 인접하여 등장하는 단어의 수를 세는 co-occurrence matrix X를 생각해 볼 수 있다. 전체 문서에 대해 수행할 수도 있고, 특정 window에 대해서 수행할 수도 있을 것이다. 문단 단위로 행렬을 생성한다면 주제에 대한 의미 분석이 가능하다.
예시) Window 기반 co-occurrence 행렬
- Window 길이 1 (5~10이 일반적)
- 좌우 대칭 (문맥 단어의 위치가 좌, 우 어디든 상관없다)
- 예시 문장
- I like deep learning
- I like NLP
- I enjoy flying
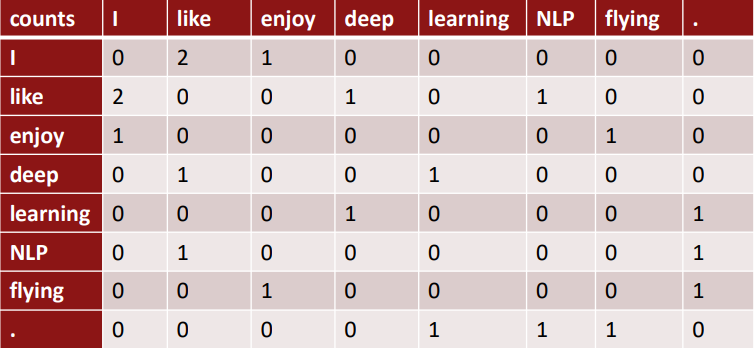
○ Co-occurrence 벡터
위 행렬로부터 co-occurrence 벡터를 생성할 수 있다. 만약 훨씬 큰 말뭉치에 대해 you가 등장한다면 I like, you like, I enjoy, you enjoy 와 같이 I와 유사한 co-occurrence 행렬값을 가질 것이며, 때문에 벡터 값도 유사하다.
문제점: 안의 내용은 희소한(sparse, 대부분이 0벡터) 반면에 벡터의 크기가 vocabulary에 따라 증가한다. 벡터의 희소성(sparsity)과 임의성(randomness) 때문에 모델이 노이지(noisy)하고 *강직(robust)하지 못하다.
*이상치에 영향을 덜 받는 모델을 robust하다고 한다
문제 해결을 위해 대부분의 중요한 정보만 남기고 저차원으로의 축소가 필요합니다.
○ 특이값 분해(singular value decomposition, SVD)를 통한 차원 감소
특이값 분해 관련 포스트
https://enjoythehobby.tistory.com/entry/%ED%8A%B9%EC%9D%B4%EA%B0%92%EB%B6%84%ED%95%B4Singular-Value-Decomposition-SVD
특이값분해(Singular Value Decomposition, SVD)
○ Full singular value decomposition(SVD) Reference) SVD와 PCA, 그리고 잠재의미분석(LSA) Singular Value Decomposition Tutorial \직사각형 행렬 A는 직교성 행렬 U와 대각행렬 S그리고 직교성 행..
enjoythehobby.tistory.com
SVD를 통해 co-occurrence 행렬의 차원 감소를 하면 성능이 좋지 못하다. 이유는 SVD는 오차가 정규분포 한다는 가정이 들어가는데, 해당 행렬에서는 자주 등장하나 실제 의미 분석에 거의 도움을 주지 않는 'a', 'the', 'and' 와 같은불용어(stopwords) 들이 대부분이고 다른 나머지 단어들은 희박하게 등장하기 때문이다.
- 빈도에 로그(log)를 취함
- 최대값을 제한 (min(X,t), with t=100)
- 불용어를 제거
와 같은 방법을 적용한 co-occurrence 행렬에 SVD를 적용하면 모델 성능이 향상되었다.
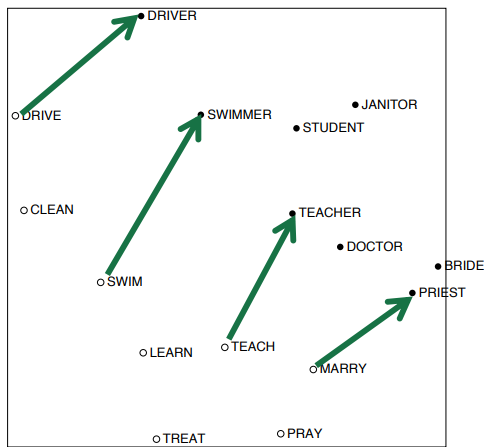
○ GloVe로 나아가기: 갯수 기반 vs. 직접 예측
| 갯수 기반 LSA, HAL (Lund & Burgess) COALS, Hellinger-PCA (Rohde et al, Lebret & Collobert) |
신경망 기반 Skip-gram/CBOW (Mikolov et al) NNLM, HLBL, RNN (Bengio et al; Collobert & Weston; Huang et al; Mnih & Hinton) |
| 빠른 학습 통계적으로 효율적 주로 단어를 잡는데 사용 빈출 단어에 중요도가 집중 |
말뭉치 크기에 비례함 통계적으로 비효율적 (중심 단어를 하나씩 확인하며 최적화) 모델의 활용도가 좋음 (다른 task에 대한 성능이 좋음) 단어 유사도 이외의 복잡한 규칙도 잡아냄 |
○벡터 차이에서의 의미 성분을 인코딩
주요 개념: co-occurrence 확률의 비율로 의미 성분을 인코딩

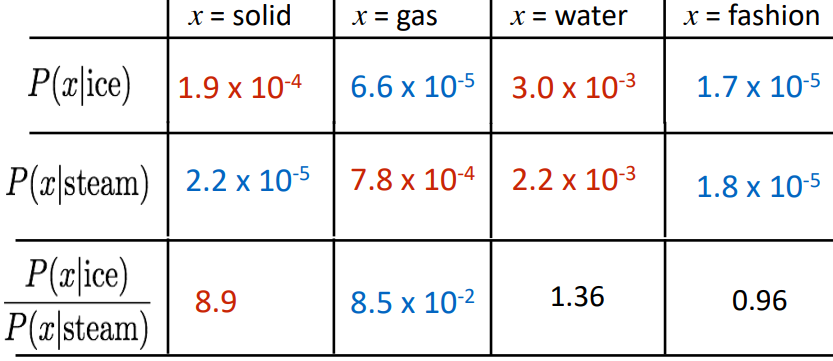
실제 위를 수식적으로 쉽게 구현하려면 확률은 Log-bilinear 모델로 구한 후 단순히 빼주면 된다.
Log-bilinear 모델: wi⋅wj=logP(i|j)
벡터 차이: wx⋅wa−wb=logP(x|a)P(x|b)
목적 함수 : J=∑Vi,j=1f(Xij)(wTi~wj+bi+~bj−logXij)2
*연산량을 줄이고자 softmax, cross-entropy 기반에서 단어 벡터와 실제 확률의 최소제곱에 X를 곱해주어 의미적으로 기대값이 최소가 되도록한다는 의미가 된다
여기서 X는 단어-단어 co-occurrence 수이며, P(i|j)=Xij/Xj는 단어 j가 문맥 단어 i와 함께 등장할 확률이다.
w는 d차원의 단어 벡터이고 ˜w는 d차원의 문맥 단어 벡터이다.
즉, 단어 벡터의 내적(유사도)이 co-occurrence 수의 로그값과 같아지기를 원하는 것이다.
- 빠른 학습
- 큰 말뭉치에 적용가능
- 적은 말뭉치와 작은 벡터에도 좋은 성능

○어떻게 단어 벡터를 평가하는가?
내재적(Intrinsic)
- 중간/세부 하부작업(subtask)에 대해 평가
- 연산속도가 빠르다
- 시스템을 이해하는데 도움
- 실제 작업(전체 task)에 도움이 되는지는 불명확
내재적 평가 예시) 단어 벡터 유사도
a:b::c:?→d=argmaxi(xb−xa+xc)Txi||xb−xa+xc||
단어 벡터 간 코사인 거리가 내재하는 의미(semantic)를 잘 포착하고 구문(syntactic) 유사도 분석을 잘 수행하는지 파악한다


다만, 모델이 성능 향상은 단순이 모델 아키텍쳐가 우수해서가 아니라 양질의 데이터가 많아진 것도 한 몫을 한다
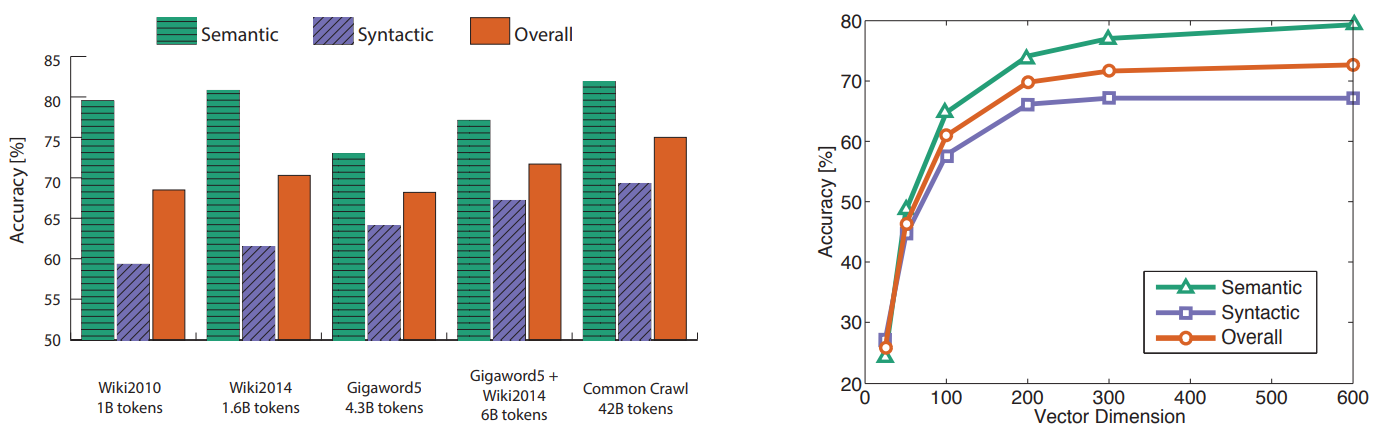
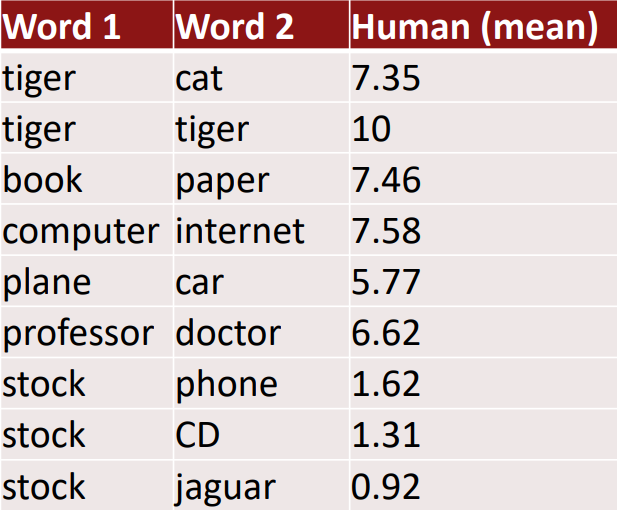
내재적 평가 예시) 단어 벡터 거리와 사람 평가의 상관관계
WordSim353: http://www.cs.technion.ac.il/~gabr/resources/data/wordsim353/
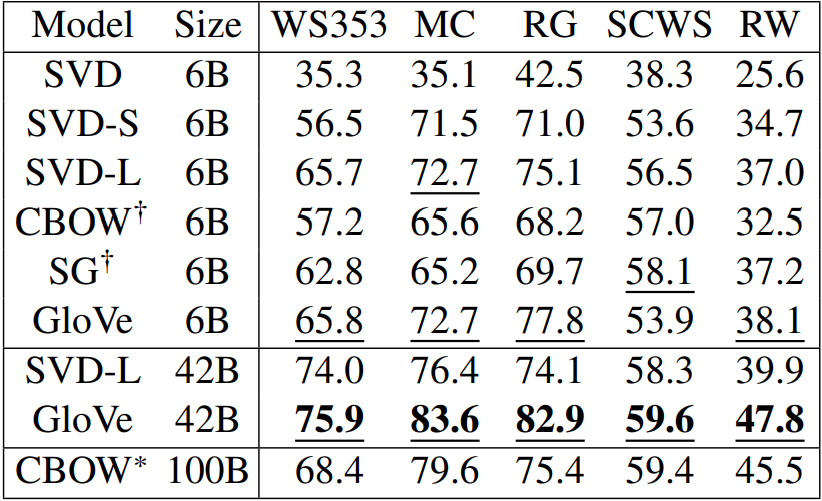
외재적(Extrinsic)
- 실제 작업에 대해 평가
- 정확한 계산에 오랜 시간이 소요
- 실제 작업 결과에 미치는 하부작업에 영향도가 불명확
외재적 평가 예시) Named entity recognition(NER): 단어를 사람, 기관, 장소 등과 같이 카테고리로 분류하여 인식
좋은 단어 벡터를 이용하면 좋은 NER 성능이 나오는가? 정답은 맞다. 좋은 단어 벡터는 단어의 뜻을 잘 표현하기 때문

○단어 의미 중의성
하나의 단어 벡터로 여러 가지 단어의 의미를 표현하는 것이 가능한가?
개념: 단어 window 별로 단어마다 클러스터링을 수행

그러나 실용적이지 못한 방법이다. 우선 클러스터링과 단어 벡터 학습 두 단계로 작업이 진행되어야 한다는 것과 단어의 여러 의미들을 명확하게 나누기 애매하기 때문이다.
여러 의미 단어를 하나의 단어 벡터로 표현할 수 있을까?
개념: 다양한 의미의 단어를 선형으로 중첩시킴(linear superposition, wrighted sum)
va=α1va1+α2va2+α3va3
여기서, α1=f1f1+f2+f3이며 f는 빈도수(frequency)이다.
굉장히 고차원에서 희소한(sparse) 벡터를 형성하면 의미 별로 벡터를 나눌수 있게된다.
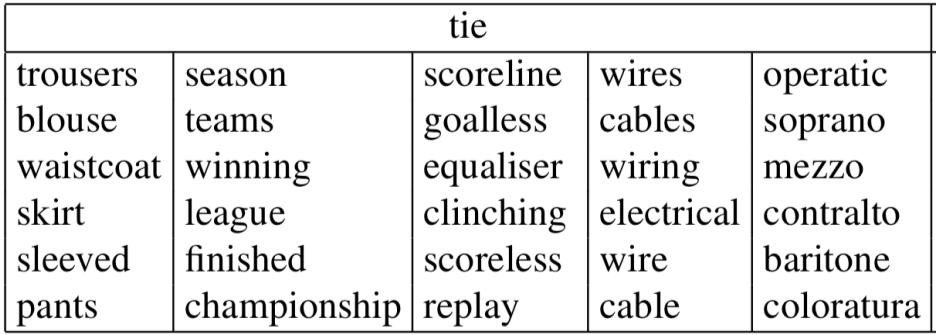
Reference)
Slide: cs224n-2021-lecture02-wordvecs2.pdf (stanford.edu)
Note: CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part II Word Vectors II: GloVe, Evaluation and Training (stanford.edu)
Video: https://youtu.be/gqaHkPEZAew?list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ
'교육 > CS224N winter 2021' 카테고리의 다른 글
| Lec 6) Simple and LSTM RNNs (0) | 2022.05.18 |
|---|---|
| Lec5) Language Models and RNNs (0) | 2022.05.11 |
| Lec 4) Dependency Parsing (0) | 2022.04.29 |
| Lec3) Backprop and Neural Networks (0) | 2022.04.22 |
| Lec1) Word Vectors (0) | 2022.04.11 |



