이전 강의: https://enjoythehobby.tistory.com/entry/Lec3-Backprop-and-Neural-Networks
Lec3) Backprop and Neural Networks
이전 강의: https://enjoythehobby.tistory.com/entry/Lec-2-Neural-Classifiers Lec2) Neural Classifiers 이전 강의: https://enjoythehobby.tistory.com/entry/Lec1-Word-Vectors Lec1) Word Vectors Denotati..
enjoythehobby.tistory.com
언어 구조를 보는 관점
이전까지 수업에서 우리는 언어학적 관점에서 단어의 의미를 공간에 embedding하고 NER 작업을 통해 단어를 분류하는 작업을 진행했습니다. 이번 수업에서는 문장 단위에서 단어간 상관관계가 어떻게 이루어지는지 확인해보겠습니다.
○ Constituency = Phrase structure(구 구조) grammar = context-free grammars (CFGs)
구문 구조는 단어를 중첩된 constituent들로 구성한다고 보는 관점으로 구문 구조를 통해 문장을 해석할 수 있고 본다.

위 문장에서 각각의 단어는 문법적 역할이 존재하며, 단어들의 조합으로 구문이 완성되고 또한 구문들 간의 조합을 통해 더 큰 구문을 구성할 수 있다. 구문 구조는 그 외에 여러가지 constituency 방법(예를 들어 tree adjoining grammars)이 있고 일부 문장에 적용되는 일반화된 constituent들의 조합으로 구문 구조를 표현할 수 있다.
○ Dependency structure
또 다른 방식으로는 dependecy structure가 있다. dependency 구조는 한 단어가 다른 단어에 어떻게 의존하는 지를 보는 방식이다.

위의 예시에서 Look은 crate를 수식하고 crate는 in과 the를 수식한다. 물론 영어에서 Look이 in을 수식하는 방식도 말은 되지만 다른 언어들을 볼 떄 universal한 방식은 Look이라는 동사가 crate라는 목적어인 명사를 수식하는 것이다. 두 방식이 완전 다른 것이 아니며, 다른 종류의 문법들 사이의 관계에 대한 완전한 공식 이론이 있다. 그러나 겉으로 둘은 많이 달라보이며, 문장 내 인접 관계들을 뽑아내는 것만으로 사용할 수 있다는 편의성 때문에 최근에 문법과 관련된 NLP에서는 많이 사용되고 있다.
○ 사람은 왜 문장구조를 사용하는가?
한 단어로 복잡한 뜻을 전달할 수 없기 때문이다. 그렇기 때문에 단어를 나열하여 의미를 전달하고 듣는이는 그 단어의 나열에서 연결 관계를 파악하여 문장을 이해하고자 한다. 즉 단어간의 수식이 어떻게 되는지를 파악하려 한다.
○ 수식 구조의 애매함
영어에서 전치사구는 수식하는 대상이 명확하지 않고 이 때문에 다양하게 해석될 수 있다.

위와 같이 전치사구가 수식하는 대상은 명확하지 않으며 이 때문에 전치사구의 수에 따라 문장의 복잡도는 지수적으로 증가한다.

뿐만아니라 수식 범위에 따라 해석이 달라지는 경우도 있다.
Shuttle veteran and longtime NASA executive Fred Gregory appointed to board
라는 문장에서 "Fred Gregory"가 수식하는 것이 "longtime NASA executive" 뿐이면 위 문장에는 2명이 나타나는 것이고 "Shuttle veteran and longtime NASA executive"를 수식하면 1명만 나타난다.
혹은 아래의 뉴스 기사처럼 형용사/부사 수식의 애매함이 나타날 수도

동사구에서 애매함이 나타날 수도 있다.

○ Dependency 문법과 구조

dependency 구조는 어휘(lexical) 항목들 간의 관계와 dependencies로 불리는 비대칭 이진 관계(화살표)로 이루어진다. 화살표들은 일반적으로 문법적 관계로 타입지어(typed) 진다. 이 때 화살표의 시작부분은 head라고 하며 가리키는 방향은 dependent라고 한다. 그래서 위의 그림과 같은 구조가 되며 맨 꼭대기가 root가 되며 일반적으로 root는 하나이다.
○ Dependency 역사

Dependency 문법은 산스크리트어로 기원전 5세기 경 Pāṇini가 tree 구조로 작성한 기록에서 시작되어 오랜기간 연구되었다. 반면에 constituency 문법은 20세기(R.S. Wells, 1947; then Chomsky 1953, etc.)에 개발되었다. 근대 dependency 문법은 Lucien Tesnière한테 1959에 정립되었으며 쉽고 자연스럽기 때문에 20세기에 광범위하게 쓰였다. NLP 작업에서 parser로의 사용은 David Hays가 1962년 컴퓨터 언어로 처음 구현하였다

Dependency 구조를 만들 때 fake Root를 추가하여 모든 단어가 무언가에 dependent하도록 한다. 화살표의 방향은 여러가지 방법이 있지만 이 수업에서는 Tesnière 방식을 따라 head to dependent로 그린다.
○ 주석된 데이터 & Universal Dependencies treebanks
데이터를 어디서 가져와야할까?
언어학자들이 수작업한 데이터들이 있다 Brown corpus(1967; 품사 추가 1979)부터 Lancaster-IBM Treebank(starting late 1980s)까지. Univerasal dependencies treebank 가 존재하며 60개의 언어 관련 자료가 있다.
Universal Dependencies: http://universaldependencies.org/
Universal Dependencies
It appears that you have Javascript disabled. Please consider enabling Javascript for this page to see the visualizations. Universal Dependencies Universal Dependencies (UD) is a framework for consistent annotation of grammar (parts of speech, morphologica
universaldependencies.org

그래서 treebank는 좋은가??
수작업으로 문장 구조를 적으면서 생성하는 것이 느리고 보기에는 좋지 않아보일 수 있다.
- 가장 좋은 점은 treebank는 재사용이 가능하다는 것이다.
- 언어의 핵심을 관통하기 떄문에 커버할 수 있는 범위가 넓다
- 문장 구조를 분석하면 통계 정보를 얻을 수 있고 이를 활용하기 좋다
- NLP 평가에 사용될 수 있다. ;영어에서 단어들은 다양한 parser를 가지기 때문에 8,90 년대에 많이 사용되었다.
○ Dependency Conditioning Preferences
dependency parsing에 사용되는 정보는 어디서 오는가?
- 단어 간 친화력 (bilexical affinities); 단어 간 관계로 즉 dependency(화살표)를 나타내고 [discussion → issues]는 그럴싸 하다.
- dependency 거리(distances); dependency와 연관된 단어의 거리로 일반적으로 인접해 있다.
- intervening material; 동사나 구두점을 기준으로 dependencies가 확장되지 않는다.
- valency of head , 어느 방향(왼쪽, 오른쪽)이 head가 dependents를 많이 갖는가?
○ Dependency Parsing 규칙
문장 Parsing은 각 단어가 dependent한 다른 단어를 고르는 것으로 일반적으로 다음의 제약사항이 있다.
- ROOT에 dependent한 단어는 하나 뿐이다
- 순환하지 않는다 (A→B, B→A)
이 두 제약사항을 만족하면 tree 구조를 얻을 수 있다.
마지막 문제는 화살표가 교차하는지 여부이며 universal한 데이터 구축을 위해 projectivity하게 parsing 한다. (projectivity는 화살표가 겹치지 않는 것을 뜻함)


From who로 다른 언어는 많이 사용하며 projective한 parsing을 위해 from을 who 앞으로 가져오면 말이 안되는 문장이 만들어진다. 그러나 이런 특정 구성의 의미(semantic)를 non-projective dependencies 없이는 파악하기 힘들다.
○ Dependency Parsing 의 방법
dependency parser를 만드는 여러가지 방법
- dynamic programming : $O(n^{3})$ 차원으로 비효율적
- graph algorithms: Graph 로 표현, Dozat and Manning (2017) et seq. - 매우 성공적!
- contraint satisfaction: Karlsson (1990)
- transition based parsing : shift reduce parsing , transition을 사용, E.g., MaltParser (Nivre et al. 2008) - 매우 효과적
○ Greedy transition-based parsing [Nivre 2003]
가장 간단한 형태의 greedy discriminative dependency parser.
Parser는 bottom-up 순서로 구축해 나아간다. "shift" 또는 "reduce"는 shift-reduce parser에서 유사하다. 그러나 "reduce"는 왼쪽 혹은 오른쪽의 head와의 dependencies를 생성할 때 특화되어 있다.
Parser는 아래 목록들로 구성된다.
- stack ($\sigma$): ROOT symbol로 시작
- buffer ($\beta$): 입력 문장으로 시작
- dependency arc 집합 ($A$): 비어있는 상태로 시작
- 행동의 집합

parser는 stack은 ROOT만, buffer는 입력 문장의 단어들, arc 집합은 비어있는 상태로 시작한다. 그리고 행동은 3가지가 가능한데,
- buffer에서 stack으로 단어를 가져오는 Shift
- 오른쪽 단어에서 왼쪽 단어의 dependency를 나타내는 left-Arc
- 왼쪽 단어에서 오른쪽 단어의 dependency를 나타내는 right-Arc
그리고 stack에 단어가 하나만 남고, buffer가 비면 종료 된다.
예시를 보자 "I ate fish"

처음엔 stack에 단어가 없으므로 Shift하여 I를 stack으로 가져온다.
이후 ROOT와의 관계를 Reduce할 수 있지만, ROOT가 하나이려면 나중에 Reduce해야 하므로 한번 더 Shift한다.

이후 Left Arc를 통해 I와 ate의 관계를 Arc 집합(A)에 추가하고 dependent I를 제거한다.
다음 또 Shift하여 fish를 Stack으로 가져온다.
이후 Right Arc를 통해 ate에서 fish로의 관계를 Arc 집합(A)에 추가하고 dependent fish를 제거한다.
Right Arc를 한 번 더해서 ROOT와 ate의 관계를 Arc 집합(A)에 추가하고 ate를 제거 후 종료 조건을 만족하므로 종료한다.
여기서 어떤 기준으로 다음 액션을 정할까?
○ MaltParser [Nivre and Hall 2005]
정답은 없고 그래서 어려운 것. 모든 경우의 수를 진행하게되면 지수적으로 문장크기에 따라 지수적으로 증가한다.
이른 2000년대 Joakim Nivre's 가 next action classifier에 machine learning을 이용하기로 했다.
각각의 action을 예측하는 classifier를 구축하고 run classifier - choose next action 을 반복하여 parsing을 진행한다.
- class는 action이므로 최대 3개
- 관계의 총 경우의 수는 최대 R x 2(단어 당 arc가 두 개) + 1(shift) 이다.
- classifier의 feature: top of stack word, POS; first in buffer word, POS;
탐색을 진행하지 않고 greedy 하게 진행한다. (beam search를 쓰면 더 개선)
성능은 비록 최신 dependency pasing에 못미치지만, 문장길이에 대해 매우 빠른 linear time parsing이 가능하다.
○ 고전적인 Feature Representation
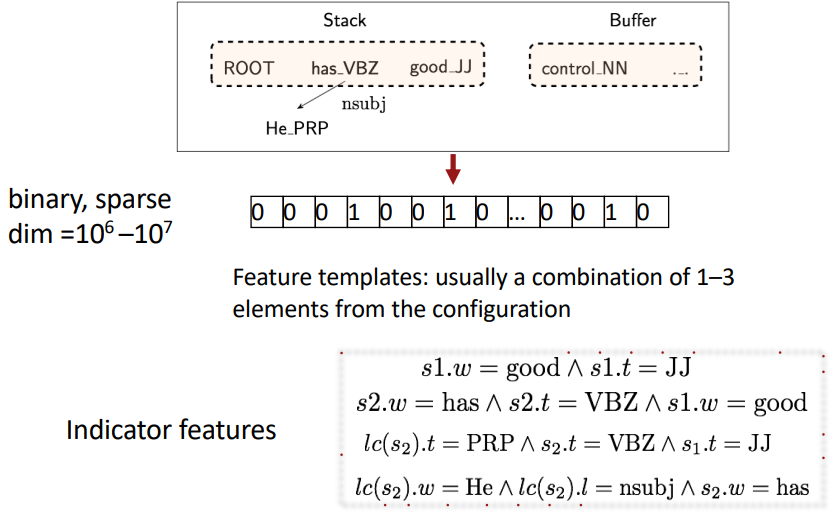
고전적인 방식에선 모든 단어들 간의 관계와 각 단어의 품사를 반영한 indicator features 구성해서 원-핫 인코딩으로 binary, sparse한 feature representation을 생성한다. 굉장히 비효율 적이다.
○ Dependency Parsing 평가 방법: dependency 정확도
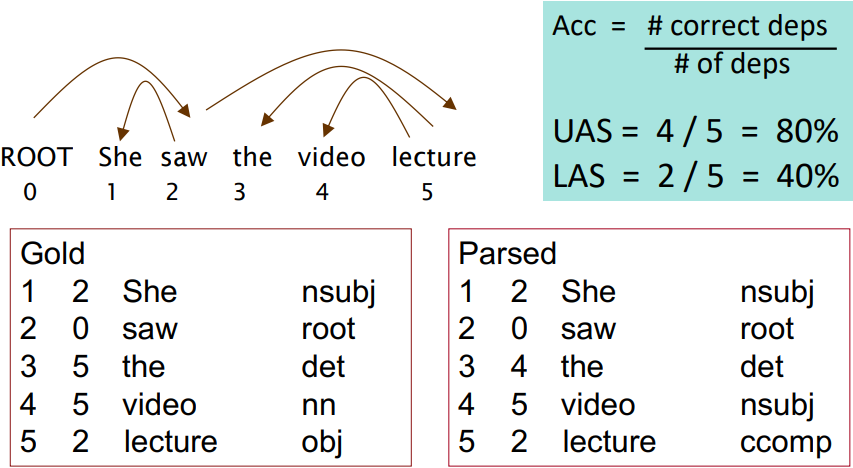
사람들이 수작업하여 작성한 Gold 데이터와 값을 비교하여 평가한다.
unlabelled accuracy score(UAS): head와 dependent가 일치하는지 여부만 판단한다.
labelled accuracy score(LAS): head와 dependent가 일치하는지에 더불어 관계도 올바르게 태깅됐는지 확인한다.
Reference)
Slide: cs224n-2021-lecture04-dep-parsing-annotated.pdf (stanford.edu)
Note: CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part IV Dependency Parsing (stanford.edu)
Video: https://youtu.be/PSGIodTN3KE?list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ
'교육 > CS224N winter 2021' 카테고리의 다른 글
| Lec 6) Simple and LSTM RNNs (0) | 2022.05.18 |
|---|---|
| Lec5) Language Models and RNNs (0) | 2022.05.11 |
| Lec3) Backprop and Neural Networks (0) | 2022.04.22 |
| Lec2) Neural Classifiers (0) | 2022.04.11 |
| Lec1) Word Vectors (0) | 2022.04.11 |



